
TL;DR
- Open-source голосовые модели появляются одна за другой, но нет единой нативной платформы для инференса (выполнения моделей) голосовых задач. К таким задачам относятся транскрипция, стриминг в реальном времени, диаризация (разделение речи по говорящим), детекция голосовой активности и живой перевод. Платформа должна работать на разных устройствах и железе.
- ExecuTorch закрывает этот пробел. Это универсальная PyTorch-нативная платформа для инференса. Она позволяет экспортировать голосовые модели прямо из PyTorch и запускать их на CPU, GPU и NPU (нейропроцессорах для ускорения ИИ-задач) — на Linux, macOS, Windows, Android и iOS.
- Мы подготовили базовые примеры реализации (референсные реализации) для пяти голосовых моделей. Они покрывают четыре разные задачи и включают рабочие C++-слои приложения, а также готовые к использованию мобильные приложения. LM Studio уже использует транскрипцию на базе ExecuTorch в продакшене.
Голос на грани сегодня
От AI-агентов всё чаще ждут, что они будут слышать и говорить. Будь то личный ассистент в умных очках, живой переводчик на телефоне или голосовой помощник программиста на ноутбуке — голос становится ключевым типом входных данных (модальностью) для взаимодействия. Голосовой агент нуждается не просто в оффлайн-транскрипции. Ему нужны потоковое распознавание речи, диаризация, детекция голосовой активности, подавление шума, speech-to-text (перевод речи в текст), живой перевод и полнодуплексная поддержка (одновременная запись и воспроизведение). Всё это должно работать локально, с низкой задержкой.
Этот спрос порождает волну open-source голосовых моделей. За последние месяцы появились Qwen3-ASR, Parakeet ASR, Voxtral Realtime, Kyutai Hibiki-Zero, Kokoro TTS, SAM-3-Audio, Liquid LFM2.5-Audio, Sortformer Diarization и многие другие. Чего не хватает — так это единого способа развернуть их нативно (напрямую на уровне ОС) на edge-устройствах (пользовательских гаджетах вроде смартфонов). Нужны скомпилированные C/C++-библиотеки, которые работают напрямую на железе без Python-рантайма и зависимости от облака.
Большинство этих моделей можно запустить в Python, но продакшен-деплой на устройствах требует нативных C++-библиотек. Существующие нативные решения — это либо специфичные для модели C++-переписывания, которые нужно переделывать под каждую новую архитектуру, либо привязанные к одной экосистеме железа платформо-зависимые фреймворки. По мере того как голосовые модели диверсифицируются по архитектуре и сложности, ни тот, ни другой подход не масштабируется.
Мы построили ExecuTorch как универсальную нативную платформу для инференса. Она работает поверх разных моделей, бэкендов (модулей вычислений) и устройств. В прошлом году мы выпустили стабильную версию (general availability) с продакшен-поддержкой LLM (больших языковых моделей), vision-моделей (компьютерное зрение) и мультимодальных моделей. Теперь мы расширяем ту же платформу на голос. Мы видим в голосе ключевое направление для on-device AI (ИИ на устройстве). Мы хотели доказать, что архитектура ExecuTorch справится с разнообразием голосовых нагрузок на разном железе. В этом посте мы приводим базовые примеры реализации пяти голосовых моделей. Они покрывают четыре разные задачи. Также мы публикуем примеры приложений и мобильные приложения. LM Studio уже использует голосовую транскрипцию на базе ExecuTorch в своём десктопном приложении.
Принципы проектирования
Три принципа лежат в основе подхода:
Минимум изменений модели, а не полный перепис. Исходный PyTorch-код модели — это стартовая точка. Вместо переписывания моделей на других языках или конвертации в другие форматы мы используем torch.export() напрямую над ключевыми компонентами оригинальной PyTorch-модели. К таким компонентам относятся аудиоэнкодер, текстовый декодер, token embedding (векторное представление токенов) и mel-спектрограмма (частотное представление звука). Вносятся минимальные правки. Например, когда Mistral выпустила Voxtral Realtime, а NVIDIA опубликовала Parakeet TDT и Sortformer, мы экспортировали их PyTorch-исходники напрямую. Потребовались лишь точечные правки для удовлетворения ограничений torch.export(). Без конвертации форматов, без реимплементации на C++.
Экспортируй модель, оркестрируй в C++. Модель и логика приложения живут на разных слоях. Компоненты модели экспортируются в скомпилированный файл (артефакт). Тонкий C++-слой приложения связывает всё вместе и управляет координацией работы (оркестрацией). Он учитывает стриминговые окна, обрабатывает перекрытия аудио, выравнивает спектрограммы и запускает stateful циклы декодирования (циклы с сохранением состояния между шагами). ExecuTorch берёт на себя сложную часть — эффективный инференс поверх разных аппаратных бэкендов.
Написал один раз — запускай на любом бэкенде. Один экспорт обслуживает все целевые платформы. Та же экспортированная модель работает на XNNPACK (CPU), Metal Performance Shaders (Apple GPU), CUDA (NVIDIA GPU) или Qualcomm (NPU). При этом в модели или скрипте экспорта остаётся минимум логики, зависящей от конкретного бэкенда. Квантование (сжатие весов модели до форматов int4 или int8) применяется в PyTorch до экспорта. Это существенно уменьшает модель без ручной работы над вычислительными ядрами.
Голосовые модели на практике
Мы валидировали этот подход на пяти голосовых моделях с совершенно разными архитектурами:
Voxtral Realtime (потоковая транскрипция, ~4B параметров). Модель потоковой транскрипции от Mistral обеспечивает реал-тайм транскрипцию с точностью оффлайн-моделей. Это хороший пример подхода «экспортируй модель, оркестрируй в C++». C++-слой приложения обрабатывает аудиосигнал. Он работает с перекрывающимися аудиоокнами, использует прошлый контекст и заглядывание вперёд, выравнивает кадры спектрограммы и отслеживает позиции энкодера. Экспортированная модель выполняет тяжёлые вычисления. В ней применяются трансформеры с ring-buffer KV-кэшами (кольцевым буфером для кэша ключей и значений). Это позволяет вести стриминг неограниченной длительности в фиксированном объёме памяти. Все стриминговые константы вычисляются на этапе экспорта и вшиваются в модель как самодескрибирующие метаданные (данные, описывающие параметры самой модели). Квантование int4 сжимает модель с 20 ГБ до 5–6 ГБ.
Parakeet TDT (оффлайн-транскрипция, 0.6B параметров). Модель распознавания речи высокой точности от NVIDIA использует архитектуру Token-and-Duration Transducer. На каждом шаге модель предсказывает, какой токен выдать и на сколько продвинуться по аудио. Этот нестандартный цикл декодирования — хороший пример multi-method экспорта в ExecuTorch. Энкодер, декодер и joint-сеть (объединяющую сеть) экспортируются как три отдельных метода в одном артефакте. C++-слой приложения реализует жадный декод (последовательный выбор наиболее вероятных токенов) с управлением LSTM-состояниями (состояниями рекуррентной сети). Слой приложения также включает извлечение таймстемпов в C++ (границы слов, сегментация предложений). Это делает конвейер обработки (пайплайн) полностью автономным on-device решением для транскрипции.
Sortformer (диаризация говорящих, 117M параметров). Модель диаризации от NVIDIA отвечает на вопрос «кто и когда говорил» для до четырёх говорящих в аудиопотоке. Сама модель stateless (не сохраняет внутреннее состояние между вызовами). Она принимает аудиоэмбеддинги (векторные представления аудиофрагментов) и выдаёт посегментные вероятности говорящих. Вся сложность стриминга живёт в C++-слое. Он управляет кэшем говорящего, который сохраняет наиболее отличительные (дискриминативные) кадры. Также он использует скользящее FIFO-окно («первым пришёл — первым ушёл») для краткосрочного контекста и сжатие кэша, отбрасывающее наименее информативные кадры при заполнении памяти. Это одна из самых наглядных демонстраций разделения модели и оркестрации в ExecuTorch.
Whisper (оффлайн-транскрипция, 39M–1.5B параметров). Широко используемая модель распознавания речи от OpenAI с самым широким покрытием бэкендов в ExecuTorch (CPU, Apple GPU, NVIDIA GPU, Qualcomm NPU).
Silero VAD (детекция голосовой активности, 2 МБ). Лёгкая модель, определяющая, говорит ли кто-то в данный момент. Базовый блок для любого голосового агента и хорошая стартовая точка для контрибьюторов.
| Модель | Задача | Бэкенды | Платформы |
|---|---|---|---|
| Parakeet TDT | Транскрипция | XNNPACK, CUDA, Metal Performance Shaders, Vulkan | Linux, macOS, Windows, Android |
| Voxtral Realtime | Потоковая транскрипция | XNNPACK, Metal Performance Shaders, CUDA | Linux, macOS, Windows |
| Whisper | Транскрипция | XNNPACK, Metal Performance Shaders, CUDA, Qualcomm | Linux, macOS, Windows, Android |
| Sortformer | Диаризация говорящих | XNNPACK, CUDA | Linux, macOS, Windows |
| Silero VAD | Детекция голосовой активности | XNNPACK | Linux, macOS |
Примеры приложений
Помимо поддержки моделей, мы построили несколько end-to-end приложений (с полным циклом обработки данных) для демонстрации возможностей. Это стартовые точки — мы призываем разработчиков строить на их основе решения под свои задачи:
Реал-тайм транскрипция на десктопе. Демо читает живое аудио с микрофона и выводит транскрибированный текст по мере речи, полностью на устройстве. Это фундамент для голосового ввода в любом десктопном приложении: ассистенты программиста, инструменты для заметок, функции доступности. Скачайте dmg и попробуйте прямо сейчас:
Автономное приложение потоковой транскрипции на macOS на базе ExecuTorch и Voxtral Realtime. Видео
Распознавание речи на Android. Parakeet и Whisper Android-приложения позволяют записывать аудио и транскрибировать его на устройстве. Это полностью функциональные приложения с загрузкой модели, записью с микрофона и транскрипцией, доступные в репозитории executorch-examples.
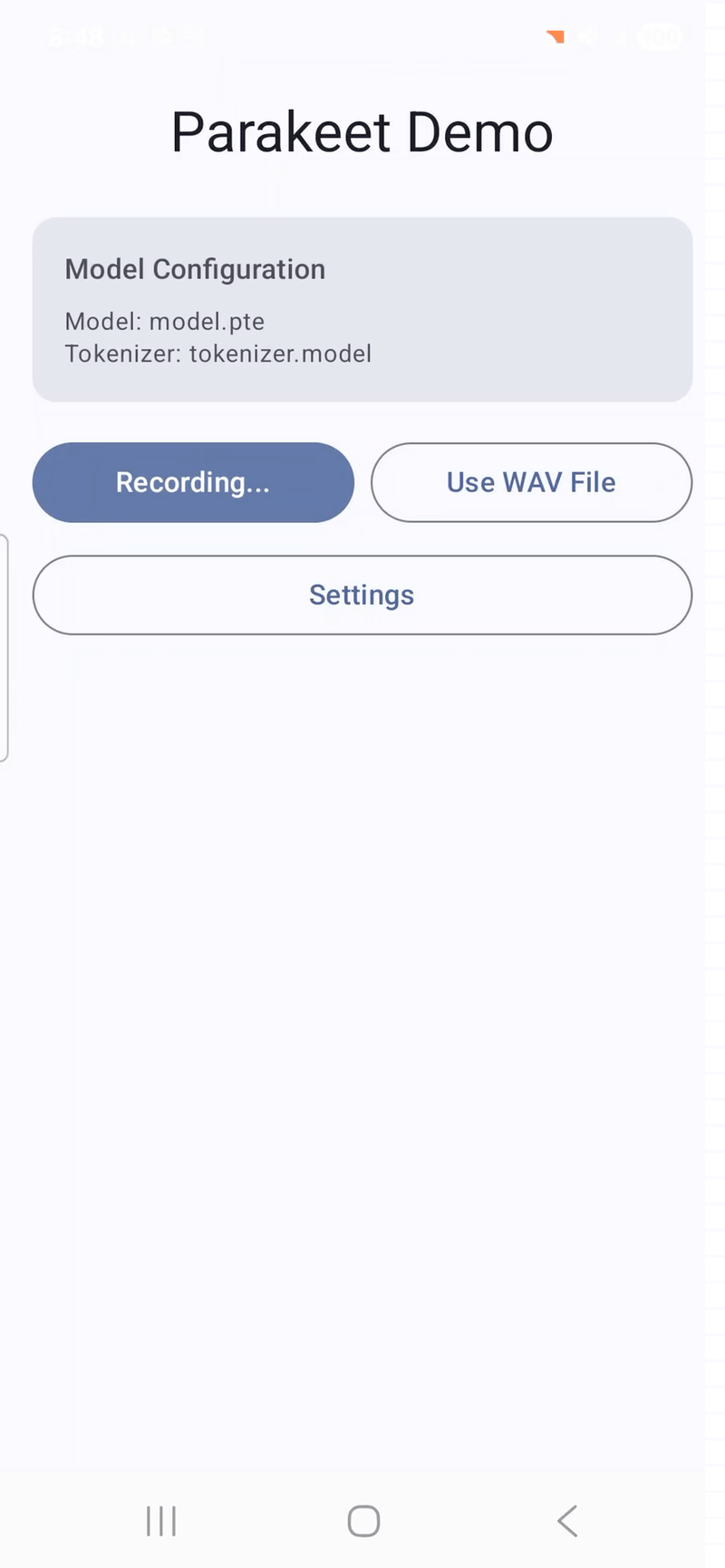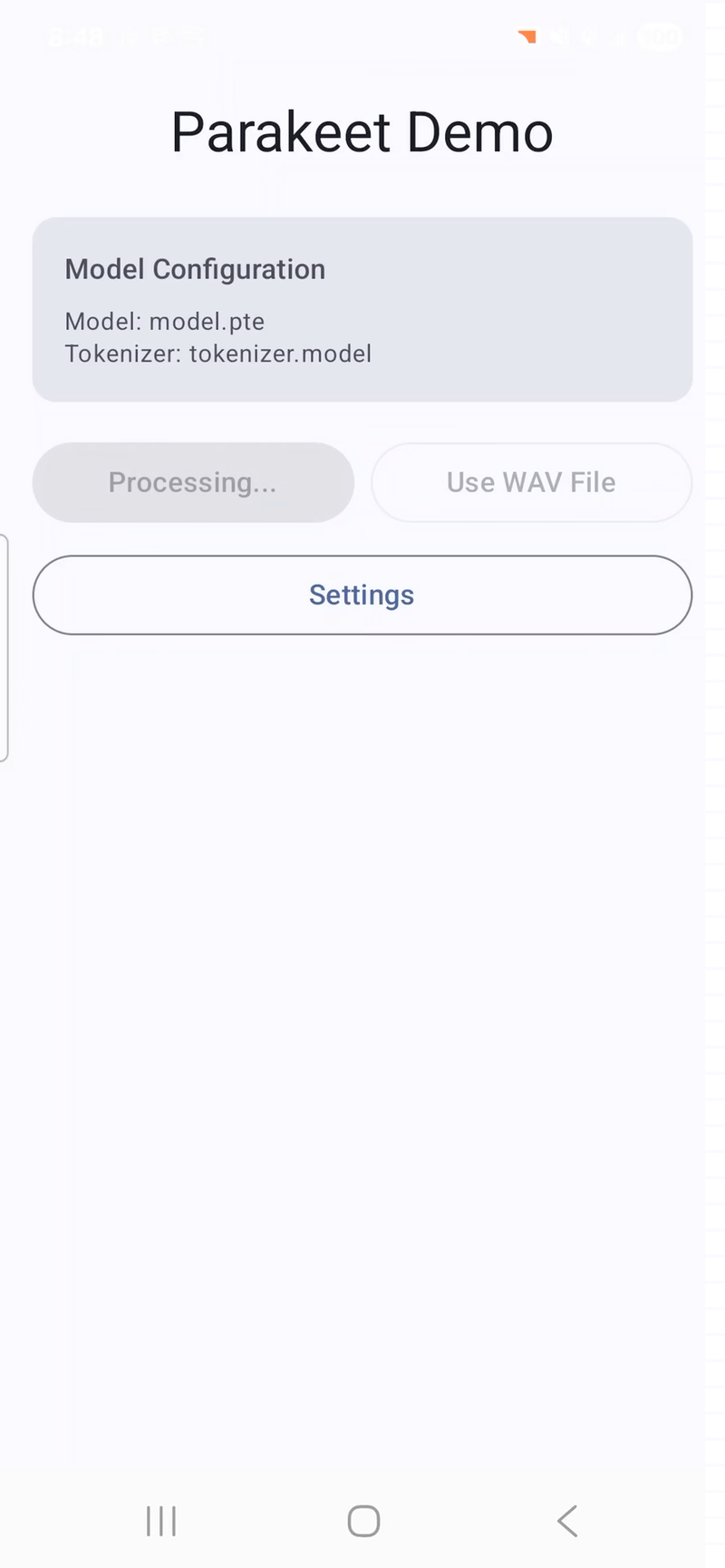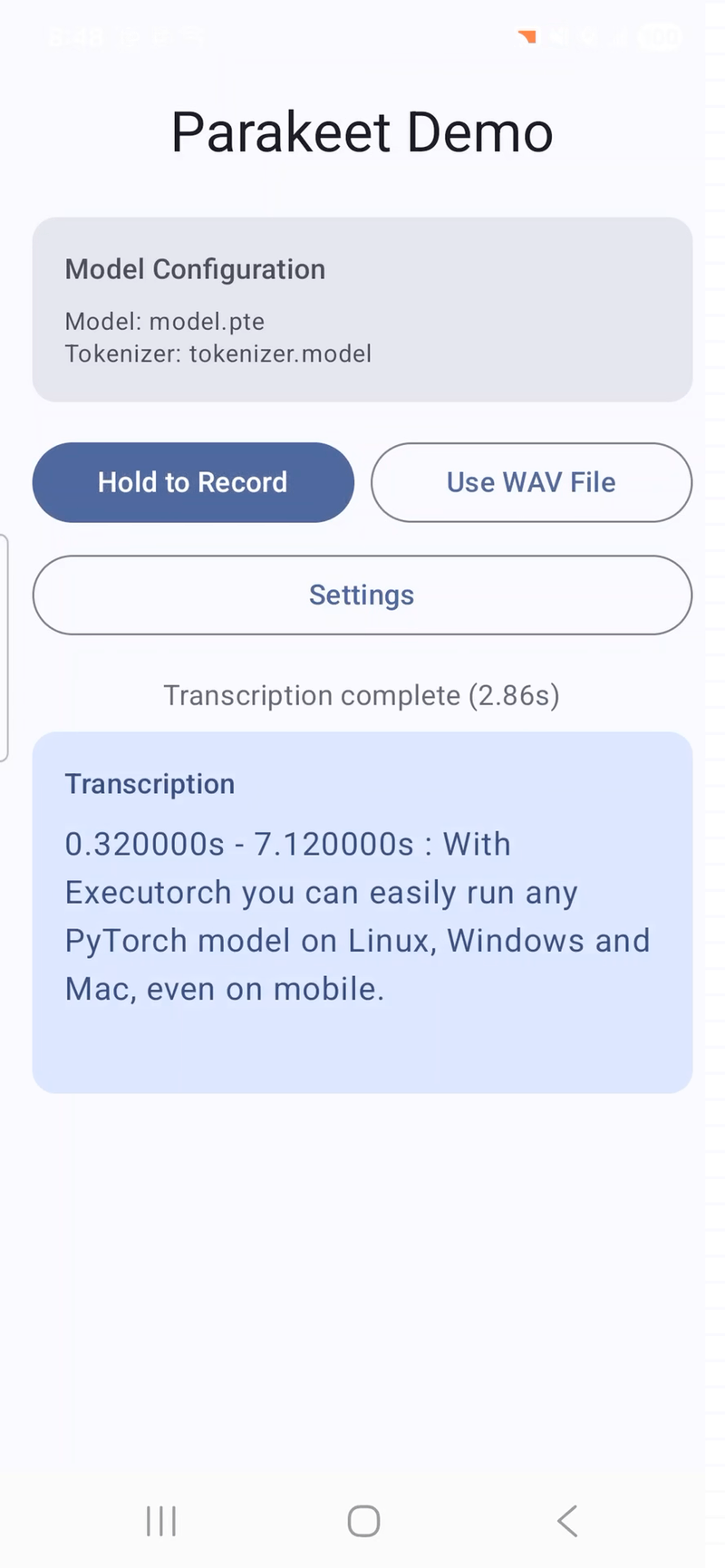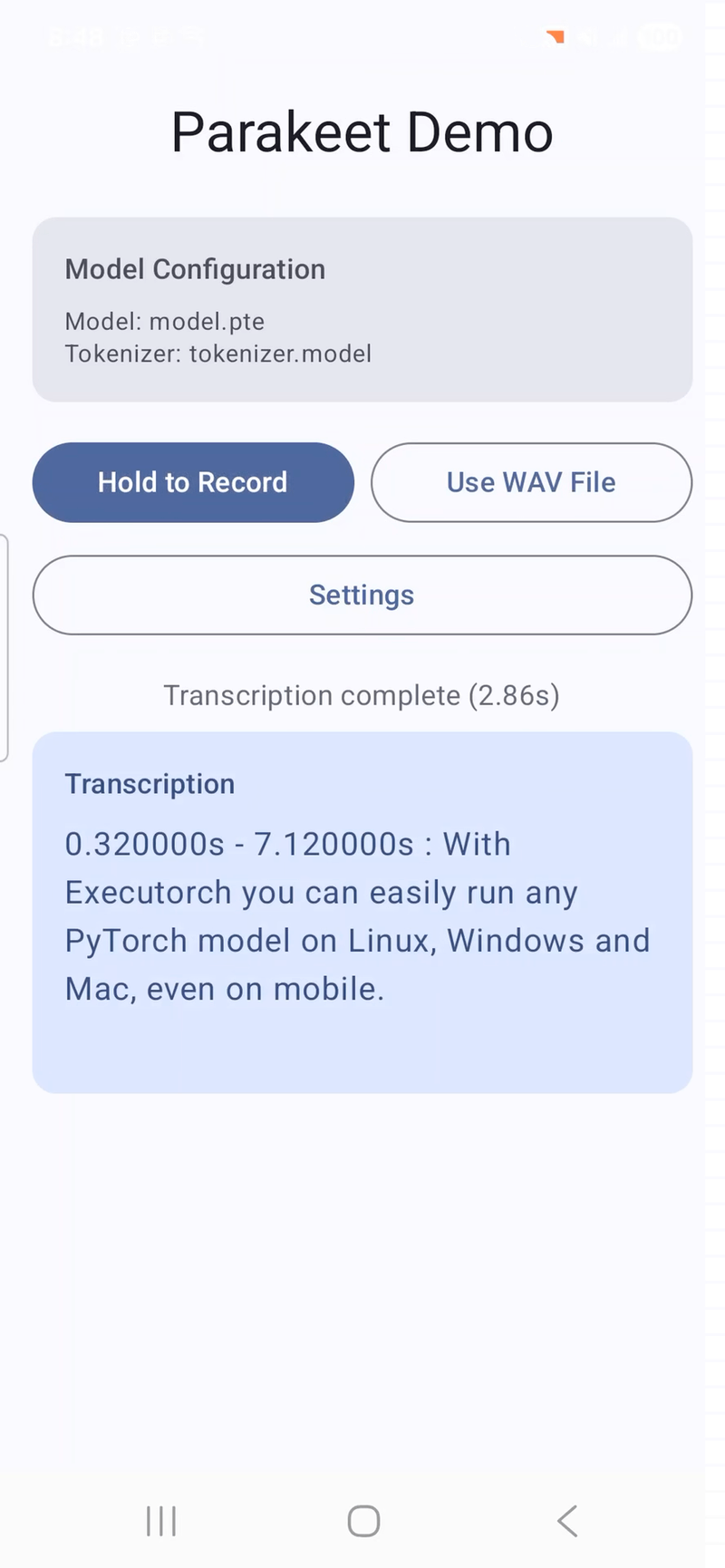
Голосовая транскрипция с таймстемпами на Android (Samsung Galaxy S24) на базе ExecuTorch и Parakeet. Видео
Кейс из продакшена: LM Studio
LM Studio — популярное десктопное приложение для локального запуска LLM. Недавно они добавили голосовую транскрипцию в свой продукт на базе ExecuTorch с моделью Parakeet TDT. Транскрипция доступна через UI (пользовательский интерфейс) приложения. API-эндпоинт (точка доступа для программного вызова) появится в ближайшее время. Это позволит разработчикам интегрировать локальное распознавание речи в свои рабочие процессы. ExecuTorch был выбран за кроссплатформенность и конкурентную производительность. Деплой (развертывание) идёт на macOS (Metal Performance Shaders) и Windows (CUDA) с одной и той же модели и одного C++-слоя приложения.

LM Studio использует ExecuTorch для кроссплатформенной on-device транскрипции
Присоединяйтесь
Эти базовые примеры реализации — стартовые точки. Ландшафт голосовых моделей, которые мы хотим поддерживать, значительно шире. Qwen3-ASR, Kyutai Hibiki-Zero, Kokoro TTS, SAM-3-Audio, Liquid LFM2.5-Audio — всё это PyTorch-нативные модели и естественные кандидаты для интеграции с ExecuTorch. Нам нужна помощь сообщества:
- Используйте ExecuTorch для голосового инференса в своих фреймворках и приложениях.
- Контрибьютьте новые модели — выберите голосовую модель, экспортируйте её, напишите слой приложения и откройте PR (запрос на слияние кода). Живой перевод, улучшение речи, детекция wake word (стартового слова активации), шумоподавление, text-to-speech (синтез речи из текста). Архитектура готова ко всему.
- Контрибьютьте бэкенды и платформы — помогите закрыть оставшиеся пробелы и улучшить производительность на разных железах.
ExecuTorch — это не только про голос. Это та же платформа, которая питает on-device LLM, vision-модели (компьютерное зрение) и мультимодальный AI.
Начните строить: Документация ExecuTorch | Репозиторий ExecuTorch | Примеры ExecuTorch | ExecuTorch Discord
Благодарности
Эта работа была бы невозможна без поддержки и ключевых контрибьюций участников команды PyTorch: Bilgin Cagatay, Tanvir Islam, Hamid Shojanazeri, Siddartha Pothapragada, Jack Khuu, Kaiming Cheng, Nikita Shulga, Angela Yi, Bin Bao, Shangdi Yu, Sherlock Huang, Yanan Cao, Digant Desai, Anthony Shoumikhin, Mark Saroufim, Chris Gottbrath, Joe Spisak, Jerry Zhang, Supriya Rao.
Отдельное спасибо Patrick von Platen из Mistral AI за создание модели Voxtral Realtime, её open-source-релиз, а также за ревью и тестирование нашего интеграционного кода.