
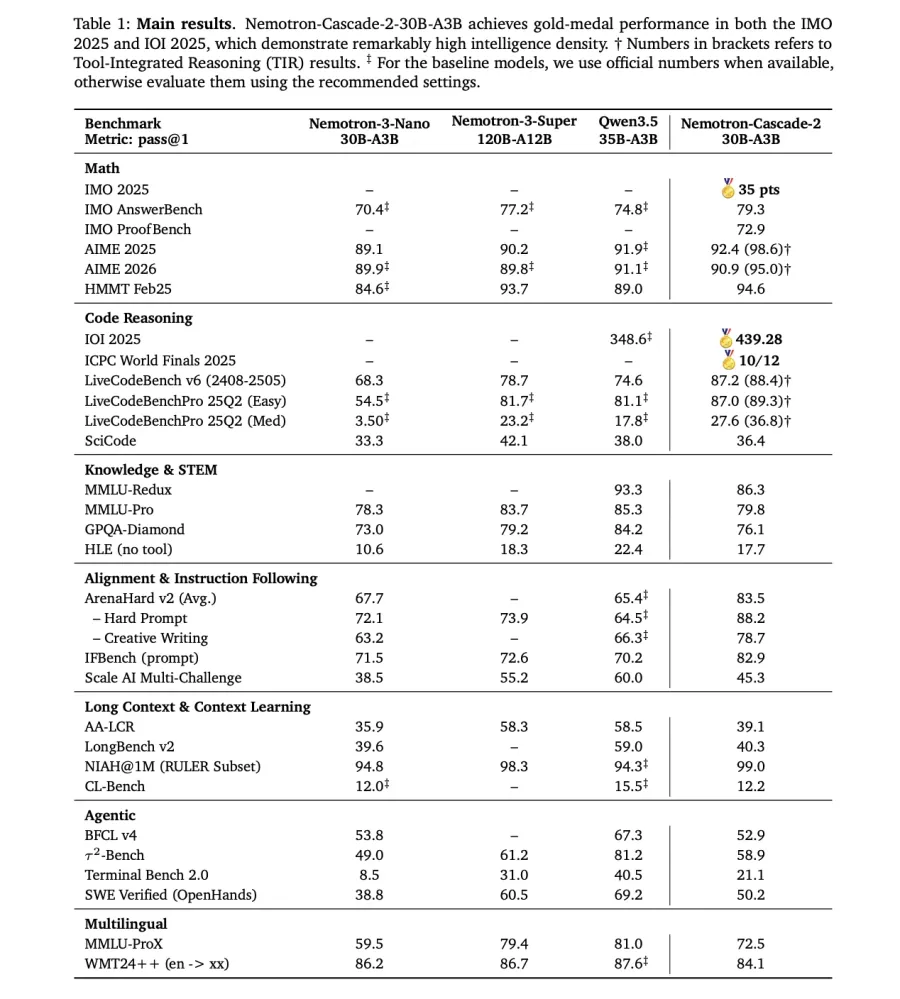
NVIDIA выпустила Nemotron-Cascade 2 — open-weight (с открытыми весами) 30B Mixture-of-Experts (MoE) модель с 3B активными параметрами. В архитектуре MoE только часть параметров активируется при каждом запросе, что экономит вычисления. Фокус модели — максимальная «плотность интеллекта»: продвинутые рассуждения при доле параметров от фронтальных (самых крупных флагманских) моделей. Nemotron-Cascade 2 стала второй open-weight LLM, достигшей уровня золотой медали на Международной математической олимпиаде (IMO) 2025 года. Также модель получила золотые медали на Международной олимпиаде по информатике (IOI) и финале мирового первенства ICPC.
Целевая производительность и осознанные компромиссы
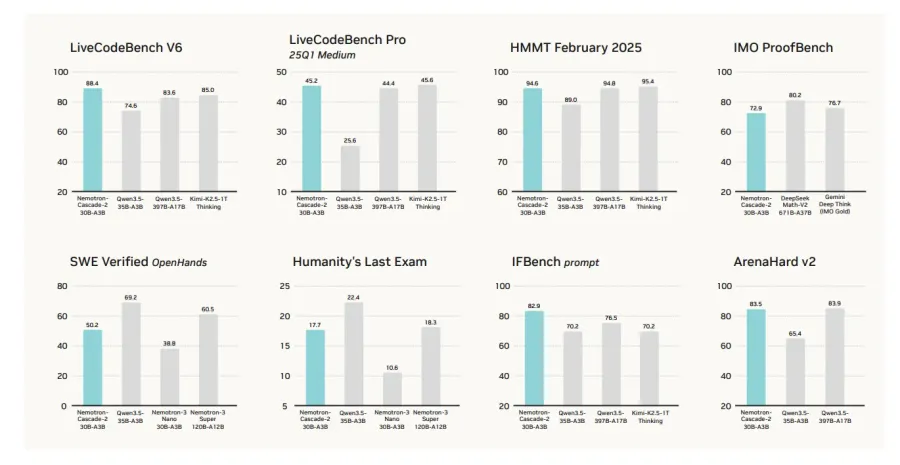
Главное преимущество Nemotron-Cascade 2 — специализированная производительность в математических рассуждениях, программировании, alignment (соответствии запросам пользователя) и следовании инструкциям. Модель достигает лучших результатов (state-of-the-art) в этих областях, но не побеждает по всем бенчмаркам.
По сравнению с Qwen3.5-35B-A3B (февраль 2026) и более крупной Nemotron-3-Super-120B-A12B модель лидирует в нескольких категориях:
- Математические рассуждения: обходит Qwen3.5-35B-A3B на AIME 2025 (92.4 против 91.9) и HMMT Feb25 (94.6 против 89.0).
- Программирование: лидирует на LiveCodeBench v6 (87.2 против 74.6) и IOI 2025 (439.28 против 348.6+).
- Alignment и следование инструкциям: значительно выше на ArenaHard v2 (83.5 против 65.4+) и IFBench (82.9 против 70.2).
Техническая архитектура: Cascade RL и Multi-domain On-Policy Distillation (MOPD)
Рассуждения модели опираются на пост-тренировочный пайплайн. Исходной точкой стала базовая модель Nemotron-3-Nano-30B-A3B-Base.
1. Supervised Fine-Tuning (SFT)
На этапе SFT (обучения с учителем) команда NVIDIA использовала тщательно собранный датасет. Семплы упаковывались в последовательности до 256K токенов. Датасет включал:
- 1.9M трейзов Python-рассуждений (записей пошаговых решений) и 1.3M семплов вызова инструментов для соревновательного программирования.
- 816K семплов математических доказательств на естественном языке.
- Специализированный Software Engineering (SWE) бленд: 125K agentic-семплов (с автономными действиями модели) и 389K agentless-семплов (без автономных действий).
2. Cascade Reinforcement Learning
После SFT модель прошла Cascade RL — последовательное поэтапное обучение по доменам. Это предотвращает catastrophic forgetting (катастрофическое забывание, когда модель теряет старые навыки при обучении новым). Гиперпараметры настраиваются под конкретный домен и не дестабилизируют остальные. Пайплайн включает этапы instruction-following (IF-RL), мультидоменный RL, RLHF, long-context RL и специализированный Code/SWE RL.
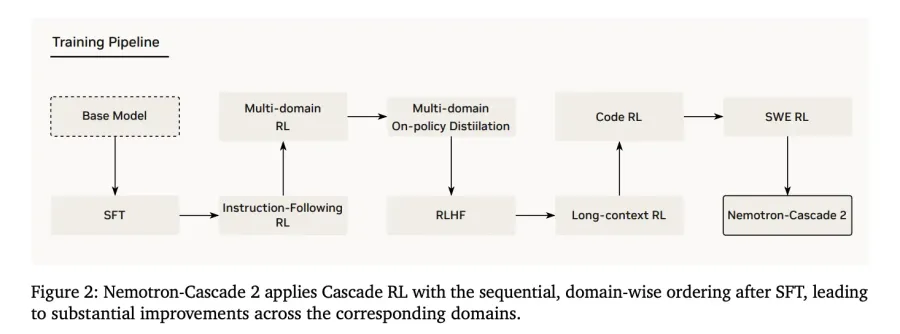
3. Multi-Domain On-Policy Distillation (MOPD)
Ключевая инновация Nemotron-Cascade 2 — интеграция MOPD в процесс Cascade RL. MOPD использует лучшие промежуточные «учительские» модели. Они уже получены из той же SFT-инициализации. Это обеспечивает плотное токен-уровневое преимущество дистилляции, которое определяется формально:
$$a_{t}^{MOPD}=log~\pi^{domain_{t}}(y_{t}|s_{t})-log~\pi^{train}(y_{t}|s_{t})$$
Исследователи выяснили, что MOPD существенно эффективнее по выборкам, чем sequence-level reward-алгоритмы (оценивающие весь ответ целиком), такие как Group Relative Policy Optimization (GRPO). Например, на AIME25 MOPD достигла уровня учителя (92.0) за 30 шагов. GRPO при том же числе шагов показала лишь 91.0.
Инференс и agentic-взаимодействие
Nemotron-Cascade 2 поддерживает два основных режима работы через chat template:
- Thinking Mode: запускается одиночным токеном
\nс последующим переводом строки. Активирует глубокое рассуждение для сложных математических и кодовых задач. - Non-Thinking Mode: активируется добавлением пустого блока
Для agentic-задач модель использует структурированный протокол вызова инструментов внутри системного промпта. Доступные инструменты перечислены в тегах <tools>. Модель выполняет вызовы, обёрнутые в теги $_$, что гарантирует верифицируемый feedback выполнения.
Сфокусировавшись на «плотности интеллекта», Nemotron-Cascade 2 показывает: специализированные рассуждения, ранее считавшиеся исключительной прерогативой фронтальных моделей (600B+ параметров), достижимы на масштабе 30B. Это стало возможным благодаря domain-specific reinforcement learning.