

MiniMax
Китайская AI-компания MiniMax выпустила M2.7 — модель, которая, по заявлению разработчиков, принимала активное участие в собственном создании. Через автономные циклы оптимизации она улучшала процесс собственного обучения и показала конкурентные результаты на бенчмарках.
В ходе разработки M2.7 самостоятельно обновляла собственные хранилища знаний. Она строила десятки сложных компетенций внутри своей agent-инфраструктуры — системы, где модель действует как автономный агент с набором навыков. Также модель улучшала reward-based обучение — подход, при котором ИИ учится на основе системы поощрений и штрафов. Затем она использовала эти результаты для доработки собственного процесса обучения.
MiniMax называет M2.7 «первой моделью, глубоко участвующей в собственной эволюции». Компания описывает будущее, в котором саморазвивающийся ИИ «постепенно перейдёт к полной автономности». В таком сценарии ИИ будет координировать конструирование данных, обучение модели, inference-архитектуру (процесс генерации ответов), оценку и другие этапы без участия человека.
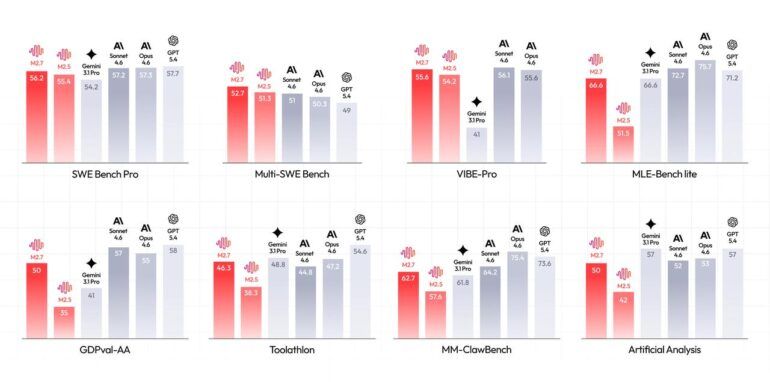
MiniMax M2.7 в сравнении с Sonnet 4.6, Opus 4.6, Gemini 3.1 Pro и GPT-5.4 по восьми бенчмаркам. M2.7 набирает близкие к лидирующим проприетарным моделям баллы в большинстве тестов. | Изображение: MiniMax
MiniMax — не единственная компания, идущая по этому пути. OpenAI недавно представила кодинговую модель GPT-5.3 Codex с аналогичными заявлениями об AI-assisted разработке. По словам OpenAI, команда Codex использовала ранние версии модели для поиска багов при обучении, управлении деплоем и оценке результатов тестирования. Разработчики признались, что были удивлены тому, насколько Codex ускорил собственный цикл разработки.
Более 100 автономных раундов оптимизации: что умеет саморазвивающийся AI
Чтобы довести самостоятельную оптимизацию до предела, MiniMax настроила внутреннюю версию M2.7 как research-agent систему. Она работала с различными проектными группами внутри компании. Агент выполнял задачи вроде поиска литературы, отслеживания экспериментов, отладки, анализа метрик и исправления кода — всё это в рамках ежедневного рабочего процесса внутренней RL-команды (RL — reinforcement learning, обучение с подкреплением). Люди вмешивались только на этапе критических решений. Модель покрывала от 30 до 50 процентов всего рабочего процесса.
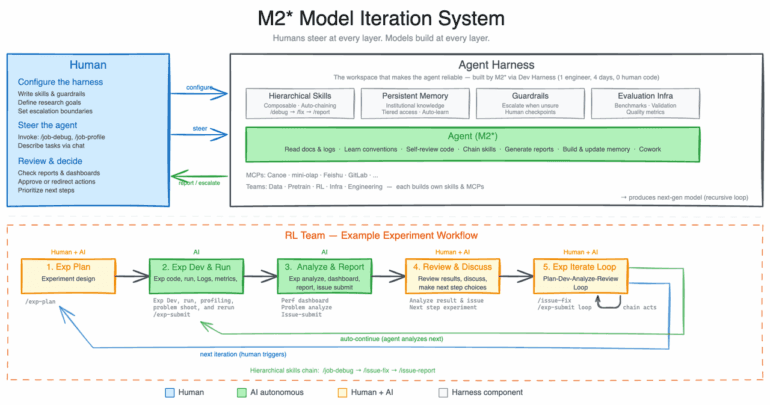
Как M2.7 разрабатывает себя: исследователи задают цели и ориентиры, затем AI-агент автономно берёт на себя большую часть процесса разработки. Пример рабочего процесса ниже показывает, как планирование экспериментов, изменение кода и оценка взаимно питают друг друга. | Изображение: MiniMax
В одном из экспериментов M2.7 полностью автономно оптимизировала кодинговую производительность модели во внутренней среде разработки за более чем 100 раундов. Каждый раунд включал: анализ ошибок, планирование изменений, доработку кода, тестирование результатов и решение — сохранить изменения или отбросить. По данным MiniMax, это дало прирост производительности на 30 процентов на внутренних оценочных наборах.
На 22 соревнованиях по машинному обучению из OpenAI MLE Bench Lite M2.7 показала средний процент получения медалей 66,6 по трём 24-часовым запускам. Это отставание от Opus 4.6 (75,7%) и GPT-5.4 (71,2%), но на уровне Gemini 3.1.
Важное уточнение: бенчмарки — полезный индикатор, но не обязательно отражают реальную производительность. Оценки на стандартизированных тестах могут существенно отличаться от того, как модель справляется с повседневными задачами. Результаты также сильно зависят от условий тестирования, форматирования промптов и оптимизации модели. Эти цифры лучше рассматривать как ориентировочные точки, а не как окончательную меру возможностей.
M2.7 держит уровень топовых западных моделей в кодинге и офисных задачах
По заявлениям MiniMax, M2.7 выдаёт результаты наравне с ведущими западными моделями на software engineering бенчмарках. На SWE-Pro она набрала 56,22% — сопоставимо с GPT-5.3-Codex. На VIBE-Pro, бенчмарке для полной сдачи проектов, — 55,6%. В реальных сценариях M2.7, как сообщается, сокращала время восстановления после сбоев продакшн-систем до менее трёх минут.
Для профессиональной офисной работы M2.7 набрала ELO-оценку 1 495 на бенчмарке GDPval-AA — высший результат среди open-weight моделей (моделей с открыто опубликованными весами). Модель выполняет многоуровневые правки в Word, Excel и PowerPoint с высокой точностью и соблюдает 97% правил по более чем 40 сложным наборам инструкций.
В качестве практического примера MiniMax приводит финансовый анализ TSMC: M2.7 самостоятельно прочитала годовые отчёты, построила модель прогноза продаж и оформила результаты в презентацию и исследовательский отчёт. Финансовые эксперты отметили, что результат уже годится как черновик.
Open-source демо: AI-взаимодействие в графической среде
Помимо продуктивных сценариев, MiniMax улучшила характерную согласованность и эмоциональный интеллект модели. Для демонстрации компания выпустила OpenRoom — open-source проект, переносящий AI-взаимодействие в графическую веб-среду, где персонажи проактивно взаимодействуют с окружением. M2.7 доступна через MiniMax Agent и API-платформу; в отличие от предыдущих версий, веса пока не опубликованы.
Юрген Шмидхубер заложил теоретическую базу саморазвивающегося AI ещё в 2003 году. Его концепция «Gödel Machine» описывала систему, которая модифицирует собственный код только при наличии формального доказательства пользы. Проекты вроде «Darwin-Gödel Machine» от Sakana AI и «Huxley-Gödel Machine» из лаборатории Шмидхубера в KAUST идут более прагматичным путём. В этих проектах AI-агенты итеративно модифицируют собственный код и отбирают лучшие варианты через эволюционный процесс.