
Массовое распространение LLM и vision-language моделей (VLM — модели, работающие с текстом и изображениями) радикально изменило AI-приложения — от автоматизации рутины до генерации креативного контента. Современные AI-агенты решают всё более сложные задачи и работают со скриншотами, PDF, диаграммами, мемами и фотографиями — часто на разных языках. Но чем глубже модели интегрируются в критические процессы и интерфейсы, тем острее потребность в надёжных механизмах контент-безопасности.
Ранние модели безопасности работали только с текстом и обучались преимущественно на английских данных. Они плохо справлялись с мультиязычными промптами и упускали культурные нюансы. Чтобы закрыть этот пробел, NVIDIA создала мультимодальную и мультиязычную модель Nemotron 3 Content Safety. Она обучена на новом культурно-адаптированном мультиязычном датасете Nemotron Safety Guard Dataset v3 и показывает превосходные результаты на мультиязычных бенчмарках.
Почему мультимодальная безопасность важна
Мультимодальный ввод — например, текст вместе с изображением — создаёт серьёзные сложности для моделей безопасности. Смысл комбинации не равен сумме частей. Изображение кухонного ножа с подписью «отличный инструмент для готовки» безопасно. Но та же картинка с текстом «собираюсь использовать это, чтобы причинить вред» — явное нарушение, требующее немедленной модерации.
Мультимодальная и мультиязычная безопасность особенно сложна тем, что требует понимания культурного и лингвистического контекста. Модель должна не просто обрабатывать разные языки, но и распознавать, как язык и культура меняют статус безопасности пары «промпт — изображение». Например, изображение традиционного религиозного символа свастики с текстом о празднике абсолютно приемлемо в одной культуре (индийской). Но в другой языковой среде (немецкой) с её историческим контекстом та же комбинация может трактоваться как подстрекательство к ненависти. Чувствительность к таким нюансам критична для глобальных систем модерации.
Как работает модель
Nemotron 3 Content Safety построена на базе vision-language модели Gemma‑3 4B‑IT. Она обеспечивает сильное мультимодальное рассуждение, следование инструкциям, контекстное окно 128K и поддержку более 140 языков. NVIDIA дообучила эту базу через LoRA-адаптер (метод эффективного дообучения с минимальным изменением весов), добавив целевое поведение классификации безопасности без увеличения размера модели.
Когда пользователь передаёт текст, изображение или оба вместе, модель совместно кодирует визуальные и текстовые признаки и выдаёт краткое суждение о безопасности. Если включён ответ ассистента, модель оценивает всё взаимодействие целиком. Это позволяет отловить нарушения, которые возникают только из сочетания запроса, изображения и ответа.
Модель поддерживает два режима инференса:
- Базовый low-latency режим — бинарная классификация safe/unsafe для ввода пользователя и ответа ассистента:
User Safety: safe Response Safety: unsafe - Режим с категориями — помимо классификации выводит список нарушенных категорий безопасности, если они нужны downstream-приложению:
User Safety: safe Response Safety: unsafe Safety Categories: Violence, Criminal Planning/Confessions
Категории безопасности следуют таксономии Aegis AI Content Safety Dataset v2, которая близка к таксономии ML Commons. Это позволяет сравнивать открытые и закрытые guard-системы (модели-фильтры, защищающие от небезопасного контента).
Как строилась модель
Модель Nemotron 3 Content Safety создана на сильной мультимодально-мультиязычной базе и дообучена на культурно разнообразных мультиязычных датасетах с человеческой разметкой. В обучении использовались тексты, реальные изображения, скриншоты, документы и целевые синтетические примеры.
Общий набор обучающих данных состоит из четырёх компонентов:
- Мультиязычные данные по безопасности контента из Nemotron Content Safety Dataset v3. Англоязычные данные исключены — берётся «адаптированная» подкультурная часть. Данные сэмплируются с пропорциональным представлением всех категорий безопасности, а также safe и unsafe примеров.
- Мультимодальные данные безопасности, собранные и размеченные людьми из NVIDIA на английском языке, затем переведённые на несколько языков через Google Translate.
- Безопасные мультимодальные данные — изображения отсканированных документов, статей, графиков, диаграмм и промпты для извлечения информации из них, взятые из Nemotron VLM Dataset v2.
- Синтетические данные для увеличения разнообразия датасета.
Такой микс обеспечивает покрытие по языкам и доменам для различных категорий вреда: оскорбительный язык, причинение себе вреда, травля, нарушение приватности, jailbreak-паттерны (способы обойти ограничения модели), региональные политики безопасности. Все англоязычные текстовые данные переведены на 12 языков — английский, арабский, немецкий, испанский, французский, хинди, японский, тайский, нидерландский, итальянский, корейский и китайский. Примерно у 25% обучающих данных категории безопасности случайно удалялись вместе с флагом /no_categories — это учит модель пропускать генерацию категорий, когда флаг активирован.
Такой подход обеспечивает генерализацию одновременно по модальностям и языкам — то, с чем аналогичные guard-модели справляются плохо.
Генерация синтетических данных (SDG)
Синтетические данные дополняли человеческие источники несколькими способами:
- Увеличение разнообразия ответов — генерация с разных LLM или промптинг модели на роль определённой персоны.
- Перефразирование ответов для большей культурной релевантности.
- Перефразирование человеческих промптов с изменением диалекта или тона английского.
- Создание jailbreak-промптов или изображений.
- Генерация разнообразных типов отказов.
SDG оказалась особенно полезна для получения специфичных данных, которые трудно собрать от людей. Например, случаев, когда безопасные вводы (промпт и изображение) приводят к небезопасному ответу. В пайплайн SDG были интегрированы открытые модели: Mixtral 8x 22B, Gemma 3-27B и Microsoft Phi-4.
Важно: синтетические данные составляют лишь около 10% обучающего датасета. Основную массу дают источники с участием людей — вручную написанные промпты и реальные изображения.
Бенчмарки
Nemotron 3 Content Safety оценивалась на устоявшихся открытых мультимодальных и мультиязычных бенчмарках: Polyguard, RTP-LX, VLGuard, MM SafetyBench и Figstep. Они покрывают сценарии, с которыми сталкиваются реальные агенты — смешанноязычные диалоги, скриншоты с встроенным текстом, визуально обусловленные риски и случаи, когда смысл меняется только при совместном рассмотрении текста и изображения.
По этим бенчмарках модель показывает лидирующую в индустрии точность для своего размера. В тестах на мультимодальный вредоносный контент она достигла в среднем 84% accuracy, обойдя сопоставимые открытые модели безопасности.
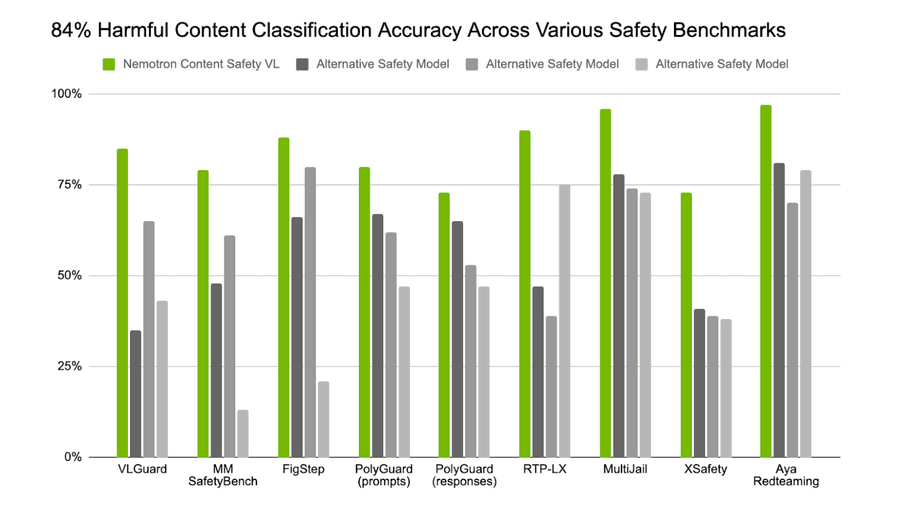
Рис.: Точность Nemotron 3 Content Safety (harmful F1 score) в сравнении с альтернативными моделями на мультимодальных мультиязычных бенчмарках.
Это преимущество сохраняется и в мультиязычной оценке. Модель держит стабильную точность по всем 12 языкам, включая те, где многие системы безопасности резко деградируют. Это отражает как качество мультиязычных обучающих данных, так и способность модели интерпретировать встроенный в изображения текст на разных языках. Кроме того, модель демонстрирует сильную zero-shot генерализацию на других языках — португальском, шведском, русском, чешском, польском и бенгальском (работу на языках, на которых модель не обучалась).
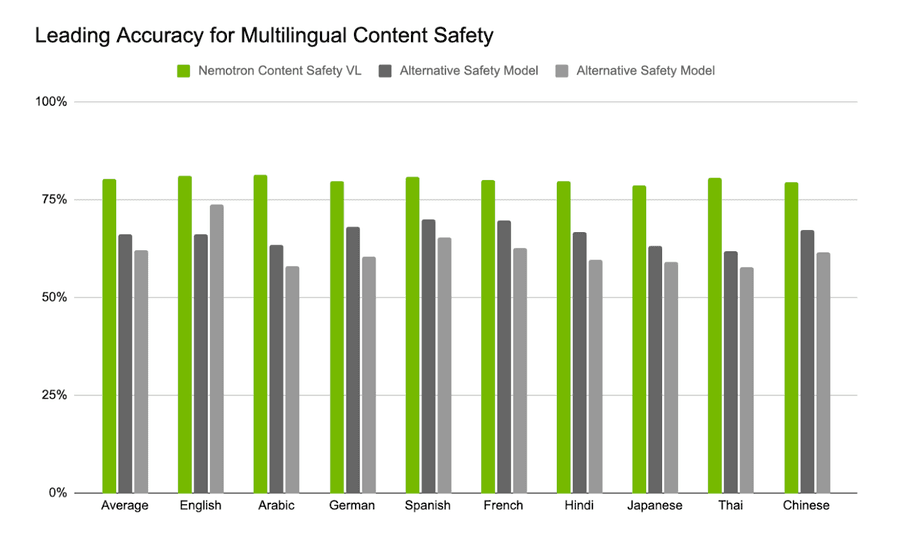
Рис.: Точность Nemotron 3 Content Safety в сравнении с альтернативными моделями по 12 языкам.
Для агентных систем одной точности недостаточно — проверки безопасности не должны тормозить цикл агента. Nemotron 3 Content Safety оптимизирована под low-latency инференс и показывает примерно вдвое меньшую задержку по сравнению с более крупными мультимодальными моделями безопасности по среднему, медианному и P99 (99-й перцентиль задержки) значениям. Это позволяет использовать её в реальном времени внутри planning-циклов, tool-calling и интерактивных приложений — даже на GPU с 8+ ГБ VRAM.
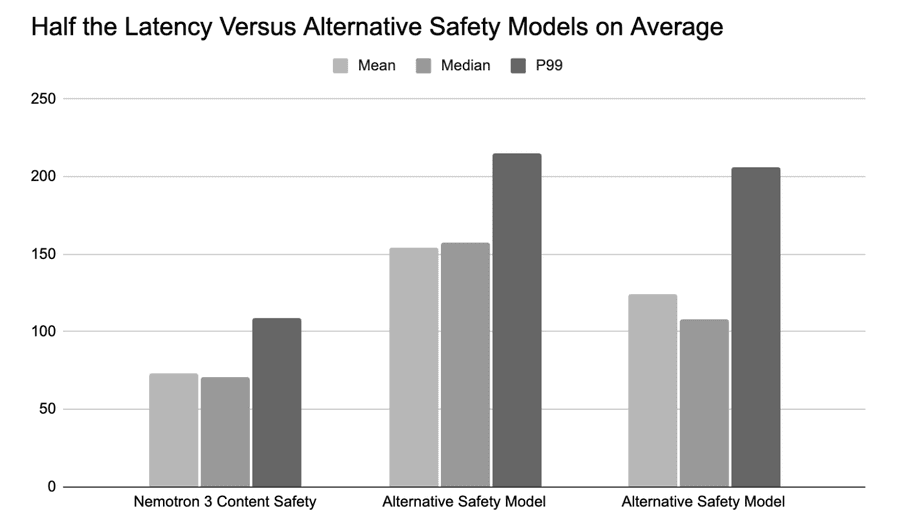
Рис.: Примерно вдвое меньшая задержка в среднем по сравнению с альтернативными моделями.
В совокупности бенчмарки показывают модель, которая точная, мультиязычная, мультимодальная и достаточно быстрая для реального развёртывания внутри AI-агентов и критичных к безопасности процессов.
Начало работы
Модель Nemotron 3 Content Safety доступна на Hugging Face, что упрощает добавление мультимодальной и мультиязычной безопасности в агентные AI-приложения. Разработчики могут загрузить модель через стандартные интерфейсы transformers или vLLM и запускать проверки безопасности по тексту, изображениям или обоим вместе.
Модель можно развернуть внутри агентного цикла для синхронной модерации, использовать в batch-пайплайнах для проверки документов и изображений или интегрировать как слой безопасности в кастомные сервисы — обеспечивая точную real-time модерацию для глобальной пользовательской базы.
В апреле модель также станет доступна как готовый к продакшену NVIDIA NIM — упакованный, защищённый и GPU-оптимизированный inference-микросервис. Он позволяет обойтись без низкоуровневой настройки model serving и быстрее выводить надёжные масштабируемые AI-фичи в продакшен.