
Представляем Nemotron 3 Nano 4B — самый компактный представитель семейства Nemotron 3. Модель построена на гибридной архитектуре Mamba-Transformer (комбинации рекуррентных слоёв и механизма внимания). Она оптимизирована для эффективности и точности в определённых задачах, задавая новый стандарт для лёгких SLM (small language models — небольших языковых моделей). Модель доступна на всех платформах с GPU NVIDIA. Она хорошо следует инструкциям и работает с инструментами, потребляя минимум видеопамяти (VRAM).
При 4 млрд параметров модель компактна для запуска на edge-устройствах (периферийных устройствах для обработки данных локально) — NVIDIA Jetson (Jetson Thor / Jetson Orin Nano), а также на NVIDIA DGX Spark и RTX GPU. Это обеспечивает быстрый отклик, конфиденциальность данных и гибкое развёртывание при низких затратах на инференс (выполнение модели).
Nemotron 3 Nano 4B — первая модель, специально оптимизированная для on-device развёртывания (непосредственно на устройстве). Она создана для работы локальных диалоговых агентов на GeForce RTX, Jetson и Spark. Модель достигает SOTA-результатов (State-of-the-Art — лучших на текущий момент) по нескольким ключевым метрикам для продакшена на edge:
- Следование инструкциям (IFBench, IFEval): SOTA в своём классе размеров
- Игровой агент / интеллект (Orak): SOTA в своём классе размеров
- Эффективность VRAM (пиковое потребление памяти): минимальный объём в классе при разных настройках ISL/OSL (длине входной и выходной последовательности — *1)
- Латентность: минимальный TTFT (время до первого токена) в классе при высоких настройках ISL (*1)
(*1) Бенчмарки эффективности замерялись на RTX 4070 с использованием Llama.cpp и Q4_K_M-квантованных (сжатых до 4 бит) версий моделей.
Кроме того, модель хорошо работает с инструментами и редко генерирует неверные факты (галлюцинирует). Это делает её сильным кандидатом для edge-сценариев.
Nemotron 3 Nano 4B получена из Nemotron Nano 9B v2 с помощью фреймворка Nemotron Elastic. Прунинг (обрезка параметров) и дистилляция (перенос знаний от большой модели к маленькой) позволили сохранить сильные рассуждающие способности. Дополнительный пост-тренинг на данных Nemotron 3 Post-training научил модель решать задачи даже без явного chain-of-thought (пошагового рассуждения в тексте).
Как open-source модель, она позволяет экосистеме кастомизировать, файн-тюнить (дообучать) и оптимизировать её под конкретные предметные области.
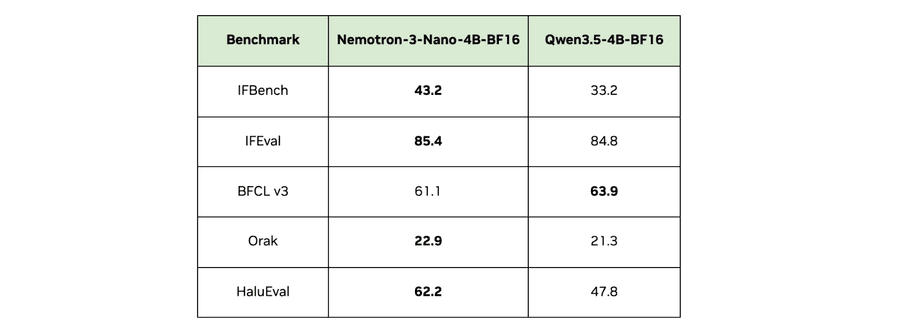
Для бенчмарка Orak модели оценивались на тактических играх: Super Mario, Darkest Dungeon и Stardew Valley.
Пайплайн обучения Nemotron 3 Nano 4B
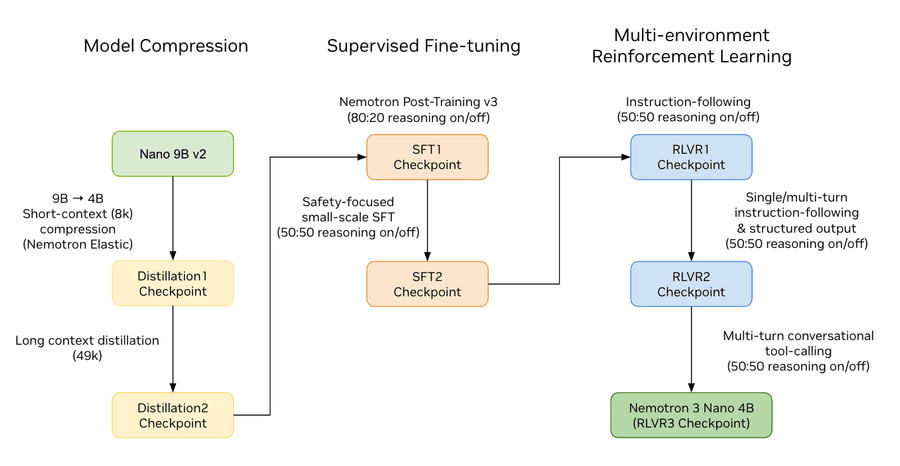
Сжатие 9B → 4B через Nemotron Elastic
Вместо обучения с нуля или раздельных этапов обрезки и дистилляции, Nemotron Elastic применяет структурированный прунинг под управлением router’а (специальной сети-маршрутизатора). Роутер обучается вместе с моделью. Он использует вспомогательную функцию потерь (auxiliary loss), которая учитывает размер целевой student-модели и функцию потерь дистилляции знаний. Это позволяет получить оптимальную student-модель за долю стоимости полного предобучения или классического сжатия.
Как роутер решает, что обрезать
Nemotron Elastic использует end-to-end (сквозное) обучаемый роутер. Он выполняет нейроархитектурный поиск (подбор оптимальной структуры) по нескольким осям сжатия параллельно с дистилляцией. Для Nano 4B фреймворк работал с одним ограничением — целевые 4 млрд параметров. Задача роутера — определить, какие оси обрезать и насколько, чтобы уложиться в бюджет.
Роутеру были доступны четыре оси прунинга:
- Mamba heads — сокращение числа SSM-голов (блоков модели состояний)
- Hidden dimension (размерность эмбеддинга) — сужение ширины векторных представлений модели
- FFN channels — обрезка промежуточных нейронов в MLP-слоях (полносвязных слоях)
- Depth (глубина) — удаление целых слоёв сети
Для каждой оси ширины роутер получал предварительные данные о важности компонента. Каналы, головы и нейроны сортировались по activation-based importance scores (оценкам важности на основе активаций). Для глубины использовалась нормализованная MSE-ранжировка (по среднеквадратичной ошибке). Каждый слой итеративно удалялся, и замерялось влияние на output logits (сырые выходные предсказания) полной модели. Так получался обоснованный порядок важности слоёв. Подробнее — в статье про Nemotron Elastic.
При целевом бюджете в 4B параметров роутер сошёлся к следующим решениям:
| Ось | Nemotron Nano 9B v2 (родитель) | Nemotron 3 Nano 4B |
|---|---|---|
| Depth | 56 слоёв (27 Mamba, 4 attention, 25 MLP) | 42 слоя (21 Mamba, 4 attention, 17 MLP) |
| Mamba heads | 128 | 96 |
| FFN intermediate dim | 15680 | 12544 |
| Embedding dim | 4480 | 3136 |
Двухэтапная дистилляция для восстановления точности
После определения архитектуры сжатая модель переобучается через knowledge distillation (дистилляцию знаний) от замороженной родительской модели на 9B. Процесс восстановления точности состоит из двух этапов:
- Этап 1 — Дистилляция с коротким контекстом (8K токенов): модель обучается на 63 млрд токенов с окном 8K. Датасет — примерно 70% пост-тренинг данных и 30% предобучения из рецепта Nano v2. Этап критичен для первоначального восстановления точности.
- Этап 2 — Расширение контекста (49K токенов): для восстановления производительности на задачах, требующих длинных цепочек рассуждений, контекст расширяется до 49K. На этом этапе модель обучается на 150 млрд токенов.
Supervised Fine-Tuning (контролируемая донастройка)
SFT проводился в два этапа на релевантных подмножествах коллекции Nemotron-Post-Training-v3 с использованием Megatron-LM. Первый этап — обучение на смеси reasoning (логических) и non-reasoning данных по предметным областям: математика, код, наука, чат, следование инструкциям, агентные задачи. Второй этап — масштабное обучение для закрепления безопасного поведения.
Multi-environment Reinforcement Learning (обучение с подкреплением в нескольких средах)
После SFT модель проходит трёхэтапный RL-пайплайн (обучение с подкреплением) на NeMo-RL. Фокус — на следование инструкциям и tool-calling (вызов внешних инструментов) / агентное поведение:
- Этап 1 — single-turn (одноходовые) данные по следованию инструкций
- Этап 2 — среды NeMo-Gym для single-turn и multi-turn следования инструкциям, а также для структурированных выходов (JSON, XML)
- Этап 3 — предварительная версия Nemotron-RL-Agentic-Conversational-Tool-Use-Pivot-v1 для multi-turn (многоходового) диалогового tool-calling
Во всех трёх этапах RLVR (обучении с подкреплением на проверяемых наградах) использовалось соотношение reasoning и non-reasoning данных 50/50. При этом прогрессивно увеличивался KL-штраф (штраф за отклонение ответов от базовой модели).
Повышение эффективности за счёт квантования
Для edge-устройств важно дополнительное сжатие модели через квантование (снижение точности чисел). Nemotron 3 Nano 4B выпущена в форматах FP8 и Q4_K_M GGUF.
FP8. Post-Training Quantization (PTQ — квантование после обучения) применялось через библиотеку ModelOpt. Для калибровки использовалась выборка из 1K примеров SFT-датасета. Она нужна для оценки статистик активаций (промежуточных значений) и минимизации потерь точности. Вместо полного квантования сети применялась селективная стратегия. Self-attention слои (4 из 42) и 4 Mamba-слоя перед ними оставались в BF16. Это дало оптимальный баланс между точностью и эффективностью. Веса, активации и KV-Cache (кэш ключей и значений для ускорения генерации) квантуются в FP8. Слои Conv1D внутри Mamba-слоёв остаются в BF16. FP8-версия показала 100% медианное восстановление точности по целевым бенчмаркам относительно BF16. Также она дала до 1.8× улучшения по латентности и throughput (пропускной способности) на DGX Spark и Jetson Thor.
Q4_K_M GGUF. Широко распространённая 4-битная схема, дающая отличный баланс эффективности и точности. Также достигла 100% медианного восстановления точности.
GGUF-версия хорошо подходит для развёртывания на Jetson. На Jetson Orin Nano 8GB чекпоинт Q4_K_M через Llama.cpp выдаёт 18 токенов/с. Это до 2× выше throughput, чем у Nemotron Nano 9B v2. Это подчёркивает эффективность модели для edge-инференса во встроенном ИИ и робототехнике.
Попробуйте сейчас
Nemotron 3 Nano 4B доступна через различные движки инференса: Transformers, vLLM, TRT-LLM и Llama.cpp — покрывая широкий спектр edge-сценариев.
Для начала скачайте чекпоинты в репозиториях Hugging Face. Примеры использования для каждого движка есть в Model Card:
- https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-4B-BF16
- https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-4B-FP8
- https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-4B-GGUF
Для Jetson пошаговые инструкции и готовые команды — на странице модели Jetson AI Lab.
Также рекомендуем посмотреть NVIDIA In-Game Inferencing (NVIGI) SDK для ускорения инференса при одновременном запуске модели и тяжёлых графических нагрузок.