
Alibaba выпустила Qwen3.5-Omni — omnimodal-модель (работает с текстом, изображениями, аудио и видео как с единым потоком). По заявлению разработчиков, она обходит Gemini 3.1 Pro по аудиозадачам, а заодно приобрела неожиданный навык: генерацию кода из голосовых команд и видеороликов.
Новое поколение серии Qwen выходит в трёх Instruct-вариантах (версиях, настроенных на выполнение инструкций) — Plus, Flash и Light. Модель поддерживает контекст до 256 000 токенов. По данным команды Qwen, за один раз она обрабатывает более десяти часов аудио и свыше 400 секунд 720p-видео при одном кадре в секунду. Qwen3.5-Omni изначально предобучена как omnimodal-модель на более чем 100 млн часов аудиовизуальных данных. Помимо текста, модель генерирует голосовой ответ.
Qwen3.5-Omni-Plus показывает state of the art на 215 аудиобенчмарках
Команда Qwen утверждает, что версия Plus устанавливает новый state of the art (лучший на текущий момент результат) на 215 аудио- и аудиовизуальных подзадачах. Это охватывает три аудиовизуальных бенчмарка, пять аудиобенчмарков, восемь бенчмарков по распознаванию речи, 156 задач перевода для конкретных языков и 43 задачи распознавания по языкам. Qwen3.5-Omni-Plus, как сообщается, обходит Gemini 3.1 Pro от Google в общем понимании аудио, рассуждениях, распознавании, переводе и диалоге. В общем аудиовизуальном понимании модель показывает parity (работает на равных) с Gemini 3.1 Pro.
 Qwen3.5-Omni-Plus лидирует или наравне с Gemini 3.1 Pro по аудиовизуальным бенчмаркам. Наибольший отрыв — в детальном описании аудиовизуального контента (Omni-Cloze). | Изображение: Qwen
Qwen3.5-Omni-Plus лидирует или наравне с Gemini 3.1 Pro по аудиовизуальным бенчмаркам. Наибольший отрыв — в детальном описании аудиовизуального контента (Omni-Cloze). | Изображение: Qwen
В цифрах: Qwen3.5-Omni-Plus набрал 82.2 в аудиопонимании (MMAU) против 81.1 у Gemini 3.1 Pro. Разрыв ещё заметнее в понимании музыки (RUL-MuchoMusic) — 72.4 против 59.6. На диалоговом бенчмарке VoiceBench модель набрала 93.1 против 88.9 у Gemini. Визуальные и текстовые возможности соответствуют отдельным текстовым моделям Qwen3.5 аналогичного размера.
В синтезе речи команда Qwen сравнивает модель с ElevenLabs, Gemini 2.5 Pro, GPT-Audio и Minimax. На сложном тестовом наборе «seed-hard» Qwen3.5-Omni-Plus достигает word error rate (коэффициент ошибок в словах) 6.24. GPT-Audio — 8.19, Minimax — 8.62, ElevenLabs — 27.70. При клонировании голосов на 20 языках модель показывает word error rate 1.87 и cosine similarity (косинусное сходство — мера похожести векторов) 0.79.
Распознавание речи выросло с 11 до 74 языков
По сравнению с предшественником Qwen3-Omni команда радикально расширила языковую поддержку. Распознавание речи теперь охватывает 74 языка и 39 китайских диалектов — всего 113 языков и диалектов. Предыдущая версия поддерживала лишь 11 языков и 8 китайских диалектов. Голосовой вывод доступен на 36 языках и диалектах. В арсенале 55 голосов — включая пользовательские, сценарно-специфичные, диалектные и мультиязычные варианты.
 Qwen3.5-Omni-Plus лидирует в большинстве категорий синтеза речи, с наибольшим преимуществом в мультиязычном клонировании голоса. | Изображение: Qwen
Qwen3.5-Omni-Plus лидирует в большинстве категорий синтеза речи, с наибольшим преимуществом в мультиязычном клонировании голоса. | Изображение: Qwen
На датасете Fleurs для распознавания речи (топ-60 языков) Qwen3.5-Omni-Plus достигла word error rate 6.55 против 7.32 у Gemini 3.1 Pro. Для китайских диалектов вроде кантонского разрыв колоссальный: 1.95 против 13.40. Контекстное окно тоже серьёзно выросло — с 32 000 до 256 000 токенов.
ARIA решает проблему с голосовым выводом в реальном времени
Архитектура по-прежнему следует паттерну thinker-talker (подход «мыслитель-говорун»). Thinker анализирует мультимодальный ввод и генерирует текст, а talker превращает его в контекстуальную речь. Оба компонента теперь работают на гибридной attention-MoE-архитектуре. Она объединяет механизм внимания (attention) и смесь экспертов (MoE — архитектура, где для каждой задачи активируется только часть параметров). Предшественник использовал чистую архитектуру MoE.
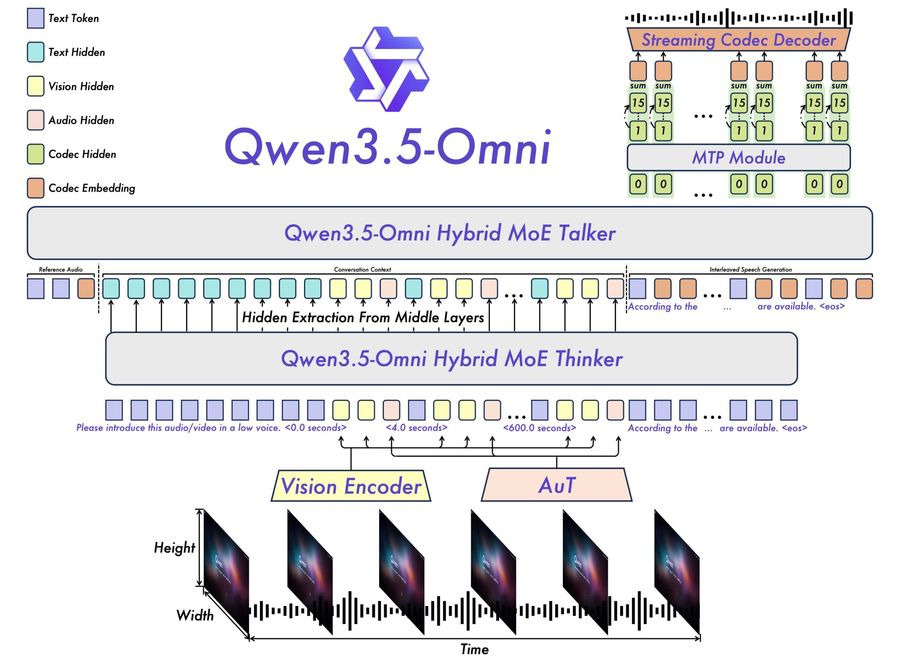 Архитектура thinker-talker Qwen3.5-Omni: thinker обрабатывает мультимодальный ввод, а talker генерирует чередующийся речевой вывод в реальном времени через ARIA. | Изображение: Qwen
Архитектура thinker-talker Qwen3.5-Omni: thinker обрабатывает мультимодальный ввод, а talker генерирует чередующийся речевой вывод в реальном времени через ARIA. | Изображение: Qwen
Главное техническое обновление — ARIA (Adaptive Rate Interleave Alignment). Механизм динамически выравнивает и чередует текстовые и голосовые токены. Команда Qwen создала его для решения известной проблемы голосового вывода в реальном времени. Текстовые и голосовые токены кодируются с разной скоростью. Из-за этого потоковые диалоги часто выдают пропущенные слова, ошибки произношения или искажённые числа. ARIA делает синтез речи естественнее и стабильнее без потери производительности в реальном времени. Предшественник использовал жёсткое соответствие 1:1 (маппирование) между текстовыми и аудиотокенами.
«Audio-visual vibe coding» проявился как emergent capability
При масштабировании omnimodal-обучения команда обнаружила неожиданную способность. Модель способна писать код напрямую из голосовых инструкций и видеоконтента — команда называет это «audio-visual vibe coding». Навык специально не тренировался. Он проявился как emergent capability (возникшая способность — навык, который появляется сам при масштабировании без целенаправленного обучения). В демо Qwen3.5-Omni-Plus собирает работающую игру «Змейка» по словесному описанию и видеоклипу.
Модель также описывает аудио- и видеоконтент с такой детализацией, что вывод читается как готовый сценарий. Она автоматически сегментирует контент, ставит точные до секунды таймкоды и даёт детальную информацию о персонажах, диалогах, звуковых эффектах и их взаимодействии. В одном демо модель разбирает трёхминутную сцену из документалки о львах покадрово — отмечает каждого спикера, каждый монтаж и каждый звук. В другом — сцены насилия в видеоиграх для контент-модерации, оформляя их в таблицу с таймкодами и уровнями риска.
Диалоги в реальном времени стали умнее: семантические прерывания и веб-поиск
Для разговоров в реальном времени Qwen3.5-Omni добавила несколько возможностей, которых не было у предшественника. «Семантическое прерывание» определяет, действительно ли пользователь хочет сказать что-то, и игнорирует фоновый шум или случайные вставки. Модель сама решает, нужен ли веб-поиск для актуального вопроса, и справляется со сложными function calls (вызовами внешних функций или API).
Пользователи могут настраивать голосовые параметры голосовыми командами. Громкость, темп и эмоциональность — всё меняется прямо посреди разговора. Клонирование голоса позволяет загрузить свой голос и использовать его как голос AI-ассистента. Все эти возможности доступны через real-time API.
Модель также доступна через Qwen Chat и Alibaba Cloud Model Studio. В отличие от предыдущих релизов — Qwen3-Omni и текстовых моделей Qwen3.5 — Alibaba пока не опубликовала веса модели и не назвала лицензию. На данный момент Qwen3.5-Omni доступна исключительно как API-сервис.
Релиз на фоне кадровой турбулентности и стремительного выхода моделей
Alibaba выпускает модели ударным темпом. Предшественник Qwen3.5-Omni — Qwen3-Omni — вышел всего в апреле 2025 года. Эта 30-миллиардная модель заявляла о топовых результатах на 32 из 36 аудио- и видеобенчмарков и отвечала на аудио-ввод за 211 миллисекунд. С тех пор Alibaba расширила серию текстовых моделей Qwen 3.5 до четырёх моделей. Флагманская Qwen3.5-397B-A17B работает на архитектуре mixture-of-experts. Она содержит 397 млрд общих и 17 млрд активных параметров.
Но такой темп совпал со сложным моментом. Главный AI-разработчик Alibaba Цзюньян Линь — человек, стоявший за всей серией Qwen — недавно неожиданно покинул компанию. За ним последовали и другие ключевые участники, включая руководителей направлений Qwen Coder, post-training (этап донастройки модели после базового обучения) и Qwen 3.5/VL (Vision-Language — моделей для работы с изображениями и текстом).
Уходы были спровоцированы внутренней реструктуризацией. Она поставила бы во главе направления исследователя, переманенного из команды Google Gemini. CEO Alibaba Эдди У отреагировал, объявив о создании нового «Foundation Model Task Force». Он подчеркнул, что разработка фундаментальных моделей остаётся «ключевым стратегическим приоритетом нашего будущего».