
Запуск больших языковых моделей в продакшене — это постоянный компромисс между производительностью и стоимостью. Speculative decoding (спекулятивное декодирование — метод, где маленькая модель угадывает токены для ускорения большой) — стандартный инструмент. В теории он ускоряет инференс. На практике часто не оправдывает ожиданий. Draft-модели (модели-черновики) устаревают, acceptance rate (доля угаданных токенов) деградирует, а офлайн-ретрейн слишком медленный и дорогой, чтобы успевать за живым трафиком. А что, если система могла бы непрерывно обучаться на лету — прямо из тех запросов, которые обрабатывает?
В прошлом году мы представили ATLAS — первый шаг к адаптивному спекулянту (draft-модели). Та работа заложила фундамент. Но цель всегда была полноценной автономной системой, замыкающей петлю между обслуживанием запросов и обучением.
Сегодня мы выпускаем Aurora — open-source фреймворк на основе RL (обучения с подкреплением). Он учится из реальных трейсов инференса и асинхронно обновляет спекулятора. Speculative decoding превращается из статичной настройки в динамический самосовершенствующийся механизм (flywheel). Такая архитектура дает преимущества, труднодостижимые в стандартных пайплайнах: (1) устранение distribution mismatch (несоответствия распределений данных) с улучшением 1.25× поверх сильного офлайн-бейзлайна; (2) снижение затрат за счёт отказа от масштабных пайплайнов сбора активаций (промежуточных данных слоёв сети); (3) algorithm-agnostic фреймворк, совместимый с будущими спекуляторами; (4) поддержка разнообразных пользовательских запросов.
По результатам экспериментов Aurora даёт дополнительное ускорение 1.25× поверх хорошо обученного, но статичного спекулятора на популярных моделях (Qwen3 и Llama3).
Код для воспроизведения результатов статьи открыт, мы приветствуем контрибьюшен от сообщества.
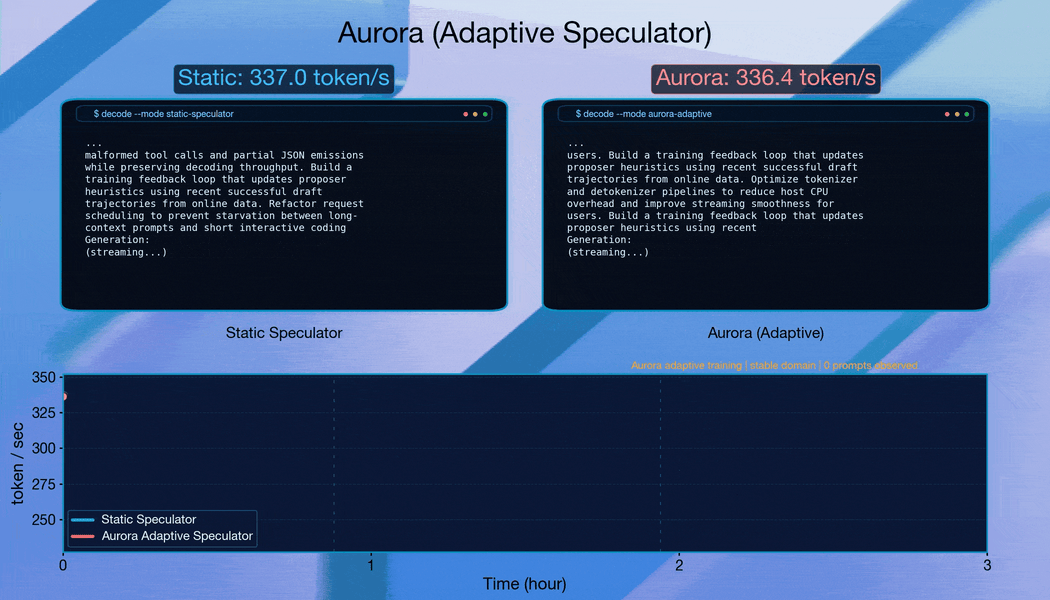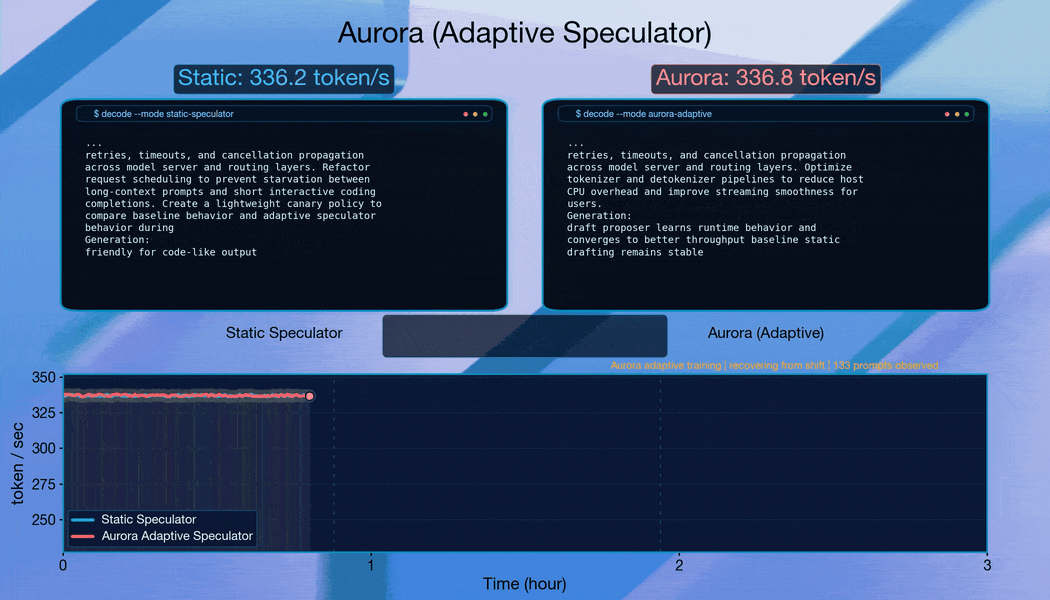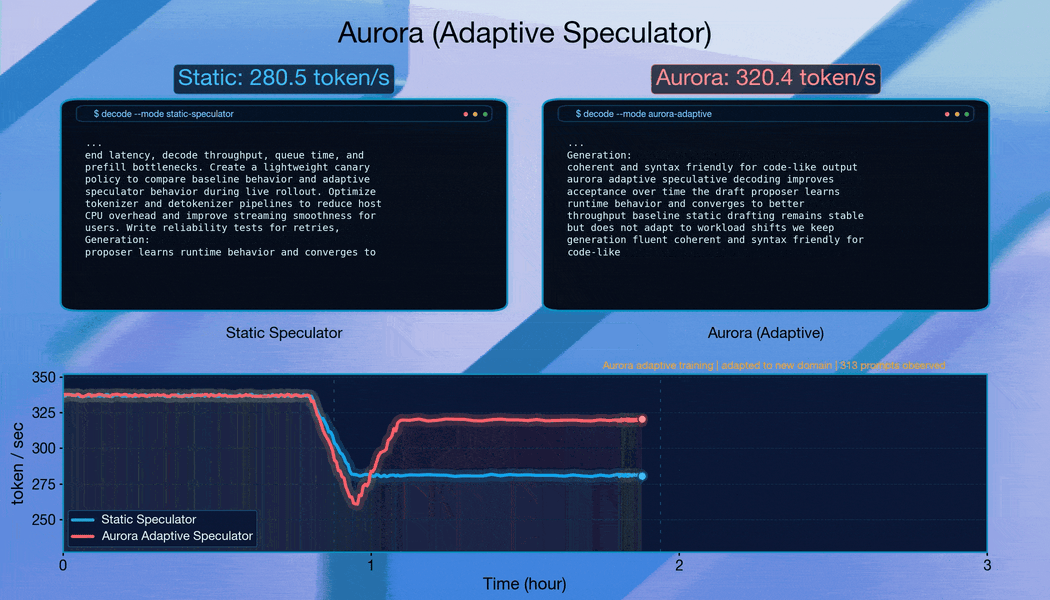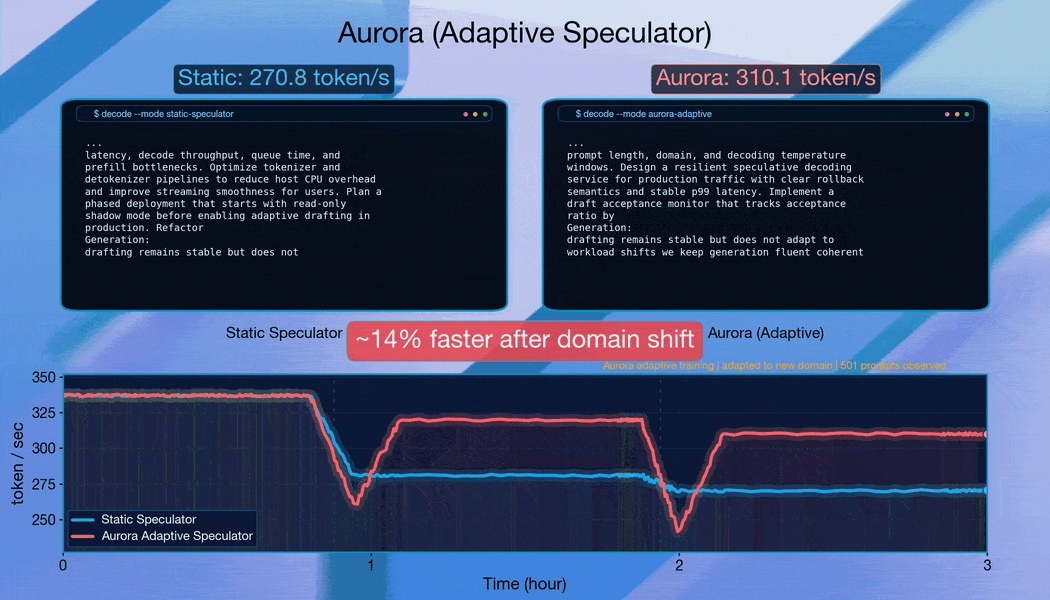
Сквозная пропускная способность при разных размерах батча
MiniMax M2.5 (FP8, lookahead 5):
| BS | Config | OTPS Mean | OTPS P50 | OTPS P05 | OTPS P95 | Speedup | Acc Len |
|---|---|---|---|---|---|---|---|
| 1 | w/o spec | 147.06 | 146.45 | 140.46 | 154.72 | — | — |
| 1 | w/ spec | 240.39 | 226.57 | 186.98 | 325.36 | 1.63× | 2.41 |
| 8 | w/o spec | 109.41 | 106.49 | 99.56 | 126.57 | — | — |
| 8 | w/ spec | 160.95 | 157.42 | 123.72 | 207.04 | 1.47× | 2.40 |
| 16 | w/o spec | 93.12 | 89.56 | 82.64 | 113.29 | — | — |
| 16 | w/ spec | 134.70 | 129.95 | 100.97 | 179.02 | 1.45× | 2.40 |
| 32 | w/o spec | 80.44 | 77.57 | 71.77 | 96.84 | — | — |
| 32 | w/ spec | 120.67 | 115.04 | 92.49 | 162.77 | 1.50× | 2.45 |
OTPS = output tokens-per-second. Тестовый датасет (198 примеров).
Qwen3-Coder-Next-FP8 (lookahead 5):
| BS | Config | OTPS Mean | OTPS P50 | OTPS P05 | OTPS P95 | Speedup | Acc Len |
|---|---|---|---|---|---|---|---|
| 1 | w/o spec | 195.21 | 195.23 | 194.75 | 195.75 | — | — |
| 1 | w/ spec | 375.49 | 350.37 | 251.92 | 574.03 | 1.92× | 3.05 |
| 8 | w/o spec | 160.08 | 157.69 | 155.81 | 175.40 | — | — |
| 8 | w/ spec | 279.09 | 250.65 | 188.27 | 414.05 | 1.74× | 3.10 |
| 16 | w/o spec | 138.70 | 137.92 | 130.05 | 150.44 | — | — |
| 16 | w/ spec | 221.56 | 202.96 | 143.80 | 323.54 | 1.60× | 2.96 |
| 32 | w/o spec | 117.50 | 114.36 | 108.95 | 130.10 | — | — |
| 32 | w/ spec | 184.23 | 166.56 | 124.03 | 278.96 | 1.57× | 3.00 |
OTPS = output tokens-per-second. Тестовый датасет (198 примеров).
1. Почему стандартный пайплайн «обучи, затем обслуживай» не работает
Офлайн-тренировка спекулятора удобна организационно, но в продакшене создаёт проблемы, ограничивающие её эффективность. Традиционный пайплайн — улица с односторонним движением: он ведёт к устаревшим моделям и отрыву от реальной производительности.
Традиционный speculative decoding следует линейному статичному потоку, который деградирует со временем. Aurora предлагает цикличный, непрерывно адаптивный подход.
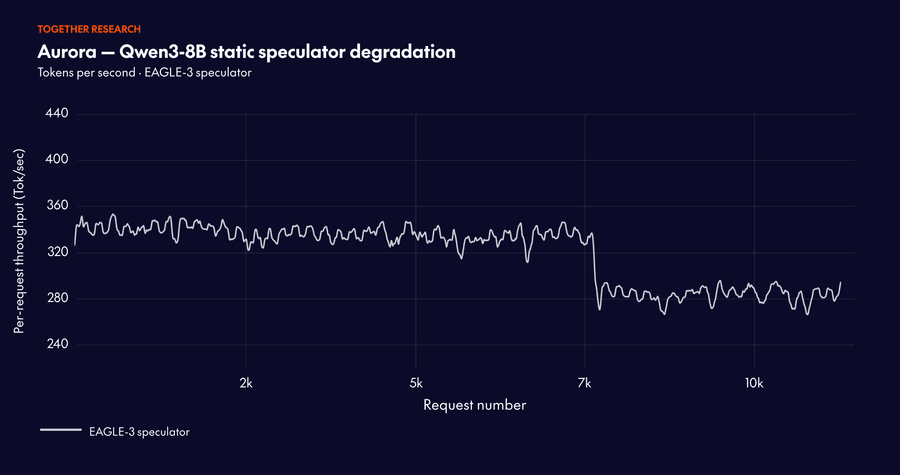
Верификатор движется, а драфтер отстаёт. Продакшен-модели меняются — ради качества, безопасности, экономии или миграции на другое железо. Спекулятор обновляется гораздо медленнее, устаревает, и качество спекуляции падает.
Офлайн-пайплайны дистилляции дороги. Сбор активаций и replay-пайплайны для тренировки драфтера затратны при масштабировании. На продакшен-масштабах объем хранилища достигает петабайтов. Растут расходы на память, сеть и операционную сложность. Aurora снижает эту нагрузку, обучаясь прямо из трейлов обработки запросов.
Acceptance rate — это не реальное ускорение. Офлайн-тренировка может оптимизировать долю принятых токенов в лаборатории. Но реальное ускорение зависит от стека: ядер (kernels), числовой точности (FP8/FP4), батчинга, планирования и поведения железа. Лучший драфтер офлайн — не обязательно лучший онлайн. Большинство команд обучает несколько драфтеров, но в итоге выбирает только один. Aurora позволяет напрямую сравнивать ускорение, потому что работает онлайн.
Эти проблемы показывают, что speculative decoding нельзя рассматривать просто как задачу обучения («обучи лучший драфтер»). Это совместная задача обучения и обслуживания.
2. Ключевая идея: serve-to-train flywheel на базе RL
Aurora превращает speculative decoding в flywheel (маховик: система обслуживания сама питает систему обучения). Вместо того чтобы считать спекулятора статичным артефактом, система непрерывно учится на каждом обработанном запросе.

Система построена вокруг двух развязанных компонентов. Inference Server запускает движок speculative decoding (на базе SGLang или vLLM) с целевой моделью и draft-моделью. Для каждого запроса драфтер предлагает последовательность токенов. Верификатор затем проверяет её параллельно. Результаты — и принятые, и отвергнутые токены, включая скрытые состояния (hidden states) для EAGLE-тренировки — стримятся в распределенный буфер данных. Training Server работает асинхронно. Он забирает батчи тренировочных данных из буфера, делает обновления градиентов на копии драфтера и периодически горячей заменой (hot-swap) возвращает улучшенные веса в inference server без прерывания сервиса.
Дизайн опирается на две продакшен-реальности. Во-первых, реальная цель — serving efficiency: латентность, пропускная способность и стоимость токена в рамках SLO (целевых показателей надежности). Во-вторых, синхронизация должна быть отложенной и ненавязчивой. Частый сброс весов вызывает инвалидацию кэша и скачки задержки (jitter). Чтобы сделать архитектуру надежной, мы переформулируем онлайн-тренировку спекулятора как асинхронную задачу обучения с подкреплением (RL).
Это не просто теоретическое удобство. Это прямое выравнивание тренировочного сигнала с реальной пользой при деплое, а не с офлайн-качеством имитации. Speculative decoding естественно ложится на логику RL:
| Speculative Decoding | RL Mapping |
|---|---|
| Draft Model | → Policy (π) |
| Target Verifier | → Environment |
| Accepted Tokens | → Positive Reward |
| Rejected Proposals | → Negative / Counterfactual Feedback |
В такой формулировке максимизация возврата (return) напрямую соответствует максимизации длины принятой последовательности. А значит — и ускорению декодирования. Тонкий, но мощный момент Aurora: система учится не только на принятых токенах. Acceptance loss (функция потерь имитации) использует cross-entropy на принятых токенах. Она побуждает драфтер воспроизводить верифицированные продолжения. Rejection loss (отбраковка, Discard Sampling) учит драфтер, чего не стоит предлагать, используя отвергнутые ветки как контрфактическую обратную связь.
Для эффективной обработки сложной ветвящейся структуры результатов используется Tree Attention (деревообразный механизм внимания). С помощью кастомной attention mask, учитывающей причинно-следственную структуру speculative tree, все ветки обрабатываются за один прямой и обратный проход (forward и backward pass) в батче.
3. Адаптация к distribution shift
Для проверки устойчивости Aurora мы симулировали реальный трафик потоком из 40 000 промптов по пяти доменам: математическое рассуждение, text-to-SQL, генерация кода, финансы и общая беседа. Такая композиция отражает реальные сценарии деплоя, где трафик разнообразен и распределение задач сдвигается. Мы оценили два паттерна трафика: (i) упорядоченные потоки, где запросы сгруппированы по домену для создания резкого сдвига распределения; (ii) перемешанные потоки, где промпты рандомизированы для аппроксимации стабильного трафика.
Когда запросы сгруппированы по домену, Aurora адаптируется непрерывно. Система восстанавливает долю принятых токенов примерно за 10 000 запросов после каждого сдвига. Это демонстрирует устойчивую онлайн-адаптацию.
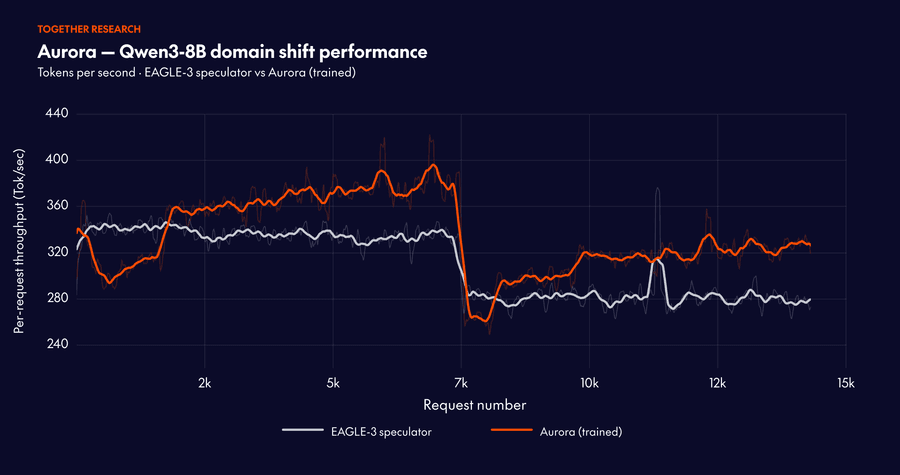
Стартуя с хорошо обученного спекулятора, Aurora даёт дополнительное ускорение 1.25× поверх статичного бейзлайна за счёт непрерывной адаптации. Это показывает, что преимущества Aurora наслаиваются поверх существующих инвестиций в офлайн-тренировку.
Результаты на перемешанном трафике особенно показательны. Онлайн-тренировка с нуля способна превзойти тщательно предобученный спекулятор. Длина принятой последовательности достигает 3.08. Это превышает и статичный бейзлайн (2.63), и бейзлайн «предобучен + дообучение» (2.99). Пропускная способность стабилизируется на 302.3 токена/с. Это бросает вызов устоявшемуся мнению, что speculative decoding требует масштабного офлайн-претрейна.
4. Заключение
Aurora — не просто очередной алгоритм speculative decoding. Это системный сдвиг. Он превращает его из статичной офлайн-задачи в динамический онлайн-процесс обучения.
Такой сдвиг открывает реальную обратную связь по полезности, адаптацию при сдвиге домена и снижение инфраструктурных затрат по сравнению с масштабными офлайн-пайплайнами дистилляции. Также он дает системный слой, совместимый с будущими алгоритмами спекуляторов. Именно поэтому правильная абстракция для speculative decoding — это не просто «лучше обучить драфтер» в изоляции, а единая петля обучения и обслуживания.