
Семейство мультимодальных моделей Gemma 4 от Google DeepMind доступно на Hugging Face — с поддержкой ваших любимых агентов, движков инференса и библиотек для файн-тюнинга 🤗
Это не просто ещё одна модель. Она полностью открыта под лицензией Apache 2. Качество входит в число лучших по соотношению качества к размеру (Парето-фронт на LMArena). Модель поддерживает мультимодальность, включая аудио. А её размеры позволяют запускать её везде — вплоть до работы прямо на устройстве (on-device), без облачного сервера. Gemma 4 берёт наработки из предыдущих поколений и заставляет их работать как единое целое. На превью-чекпоинтах мы были впечатлены настолько, что нам было трудно найти хорошие примеры для файн-тюнинга — модели и так слишком хороши из коробки.
Мы вместе с Google и сообществом обеспечили поддержку повсюду: transformers, llama.cpp, MLX, WebGPU, Rust — называйте что угодно. Эта статья покажет, как работать с Gemma 4 через любимый инструмент.
Что нового в Gemma 4?
Как и Gemma-3n, Gemma 4 принимает на вход изображения, текст и аудио, а генерирует текстовые ответы. Текстовый декодер основан на архитектуре Gemma с поддержкой длинных контекстных окон. Визуальный энкодер похож на тот, что в Gemma 3, но с двумя ключевыми улучшениями: переменное соотношение сторон и настраиваемое количество image-токенов (токенов, в которые кодируется изображение). Это позволяет найти баланс между скоростью, памятью и качеством. Все модели поддерживают изображения (или видео) и текст, а компактные варианты (E2B и E4B) — ещё и аудио.
Gemma 4 выпускается в четырёх размерах, каждый — в base- и instruction-версиях:
| Модель | Размер параметров | Контекст | Чекпоинты |
|---|---|---|---|
| Gemma 4 E2B | 2.3B активных, 5.1B с эмбеддингами | 128k | base, IT |
| Gemma 4 E4B | 4.5B активных, 8B с эмбеддингами | 128k | base, IT |
| Gemma 4 31B | 31B dense (все параметры активны) | 256K | base, IT |
| Gemma 4 26B A4B | Mixture-of-Experts (MoE), 4B активных / 26B всего | 256K | base, IT |
Архитектура и возможности
Gemma 4 сочетает проверенные компоненты из предыдущих версий и других открытых моделей, отбрасывая сложные или недоказанные решения вроде Altup. Результат — архитектура с высокой совместимостью между библиотеками и устройствами. Она эффективно поддерживает длинный контекст и agentic-сценарии (где модель действует как автономный агент). Также архитектура хорошо подходит для квантизации.
При таком наборе свойств dense-модель на 31B набирает ориентировочно 1452 на LMArena (только текст). MoE-модель на 26B набирает 1441 при всего 4B активных параметров 🤯. Для контекста: это примерно на уровне GLM-5 или Kimi K2.5, но с ~30-кратным преимуществом в эффективности по количеству параметров. Мультимодальность работает сопоставимо хорошо — по крайней мере, в наших субъективных тестах.
Основные архитектурные особенности Gemma 4:
- Чередующиеся слои внимания: local sliding-window (ограниченное окно по соседним токенам) и global full-context (полный контекст). Компактные dense-модели используют окно в 512 токенов, крупные — 1024.
- Конфигурация Dual RoPE: стандартный RoPE (метод кодирования позиций токенов) для sliding-слоёв, пропорциональный RoPE для global-слоёв — для работы с длинным контекстом.
- Per-Layer Embeddings (PLE): вторая таблица эмбеддингов, которая подаёт небольшой residual-сигнал в каждый слой декодера.
- Shared KV Cache: последние N слоёв переиспользуют key-value состояния из предыдущих слоёв, устраняя избыточные KV-проекции.
- Визуальный энкодер: обученные 2D-позиции и многомерный RoPE. Сохраняет оригинальное соотношение сторон и кодирует изображения в разный бюджет токенов (70, 140, 280, 560, 1120).
- АудиоЭнкодер: conformer в стиле USM (Universal Speech Model от Google) с той же базовой архитектурой, что и в Gemma-3n.
Per-Layer Embeddings (PLE)
Одна из самых примечательных особенностей в компактных моделях Gemma 4 — Per-Layer Embeddings (PLE), впервые появившаяся в Gemma-3n. В стандартном трансформере каждый токен получает один вектор эмбеддинга на входе. На этой начальной репрезентации строится весь residual stream (основной поток данных между слоями). Эмбеддинг вынужден «упаковать» всё, что может понадобиться модели. PLE добавляет параллельный путь conditioning (подачи дополнительного контекста) с меньшей размерностью рядом с основным residual stream.
Для каждого токена PLE генерирует маленький специализированный вектор для каждого слоя. Он комбинирует два сигнала: компонент идентичности токена (из lookup-таблицы эмбеддингов) и контекстно-зависимый компонент (из обученной проекции основных эмбеддингов). Каждый слой декодера использует свой вектор для модуляции hidden states (внутренних представлений модели) через лёгкий residual-блок после внимания и FFN (полносвязного слоя). Это даёт каждому слою собственный канал для получения токен-специфичной информации именно тогда, когда она становится релевантной. Не требуется запихивать всё в один начальный эмбеддинг.
Поскольку размерность PLE значительно меньше основной hidden size, это добавляет содержательную специализацию по слоям при скромных затратах параметров. Для мультимодальных входов (изображения, аудио, видео) PLE вычисляется до того, как soft-токены (токены-заменители для немодальных данных) сливаются в последовательность эмбеддингов. Это нужно, потому что PLE опирается на token ID, которые теряются, когда мультимодальные признаки заменяют плейсхолдеры. Мультимодальные позиции используют pad token ID, получая нейтральные per-layer-сигналы.
Shared KV Cache
Shared KV cache — оптимизация по эффективности, снижающая и вычисления, и потребление памяти при инференсе. Последние num_kv_shared_layers слоёв не вычисляют собственные key- и value-проекции (линейные преобразования для механизма внимания). Вместо этого они переиспользуют K и V тензоры из последнего non-shared слоя того же типа внимания (sliding или full).
На практике это минимально влияет на качество, но существенно экономит память и вычисления при генерации с длинным контекстом и на устройстве.
Мультимодальные возможности
В тестах Gemma 4 продемонстрировала обширные мультимодальные возможности из коробки. Точный тренировочный микс нам неизвестен, но модель успешно справлялась с OCR, speech-to-text, детекцией объектов и pointing (указанием на объекты координатами). Также поддерживаются текстовый и мультимодальный function calling, reasoning, автодополнение и исправление кода.
Ниже — примеры инференса на моделях разных размеров. Попробуйте демо и поделитесь результатами в комментариях!
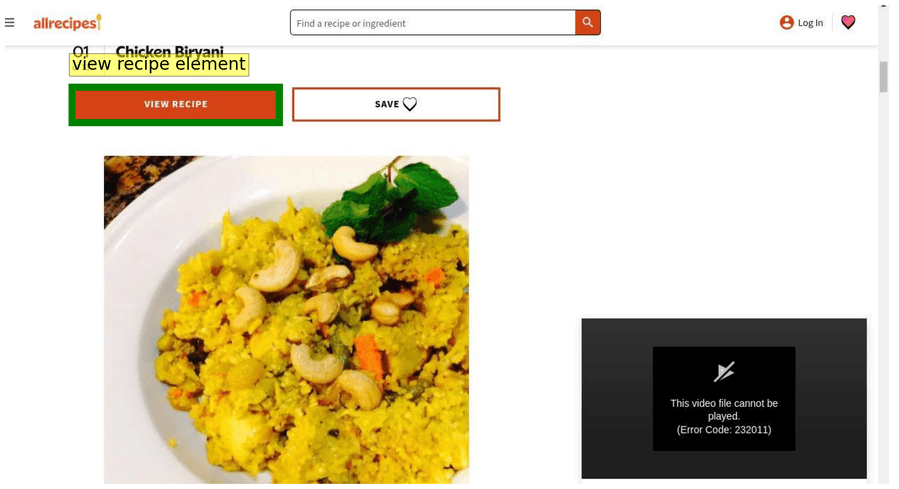
Детекция объектов и pointing
Детекция GUI-элементов
Тестируем Gemma 4 на обнаружении GUI-элементов и pointing на разных размерах. Промпт: «What’s the bounding box for the “view recipe” element in the image?»
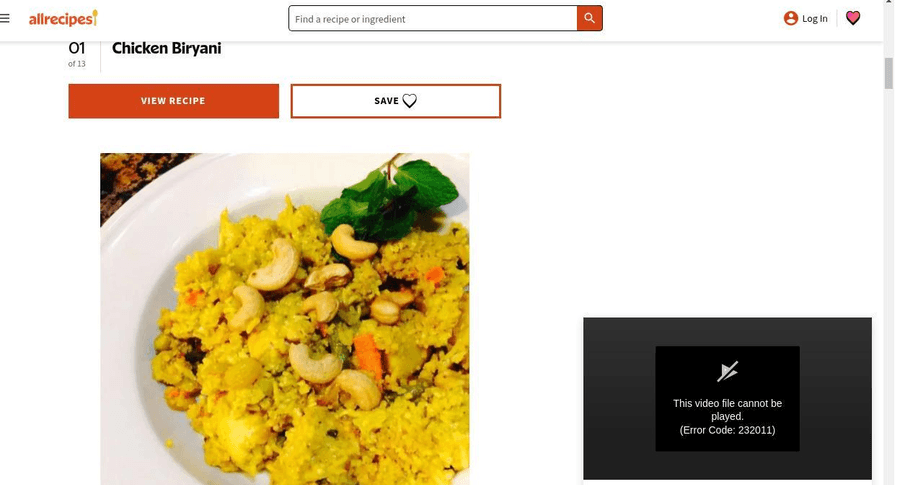
С таким промптом модель нативно отвечает в JSON с обнаруженными bounding boxes — без специальных инструкций или constrained generation (генерации с ограничениями на формат вывода). Координаты относятся к размеру изображения 1000×1000, относительно входных размеров.
Парсим bounding boxes из возвращённого JSON: json\n[\n {"box_2d": [171, 75, 245, 308], "label": "view recipe element"}\n]\n
E2B
E4B
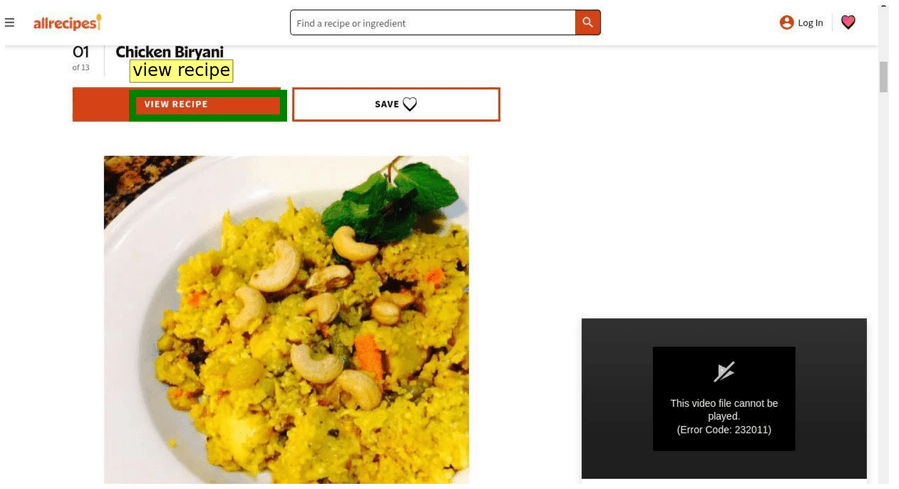
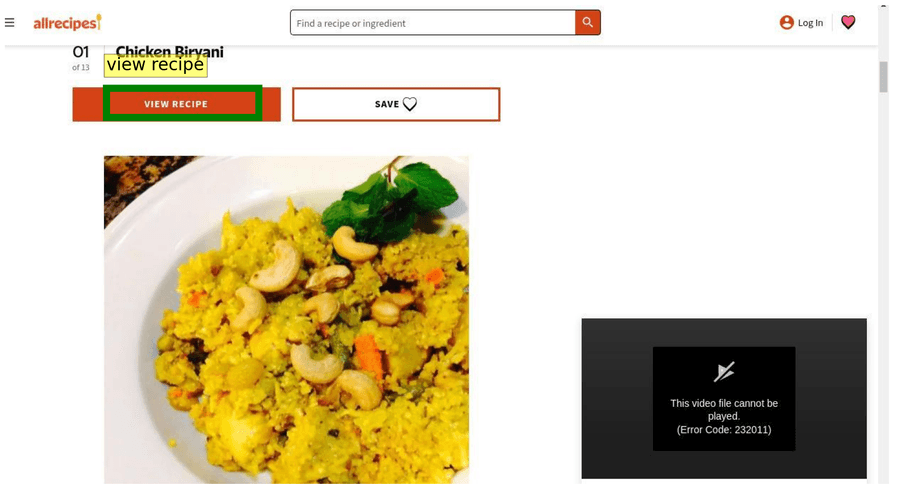
26/A4B
31B
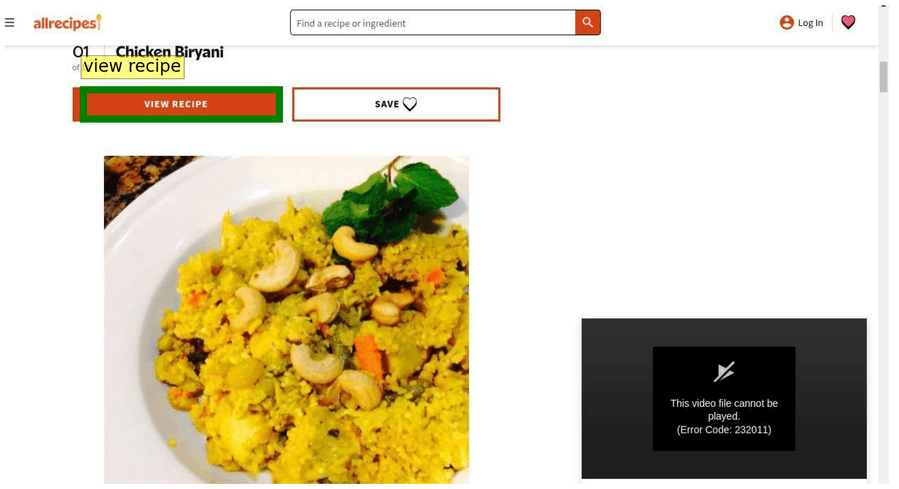
Детекция объектов
Просим модели обнаружить повседневные объекты — в данном случае велосипед — и сравниваем результаты. Как и ранее, парсим bounding box из JSON и переводим в координаты изображения.
E2B
E4B
26B/A4B
31B




Мультимодальное мышление и function calling
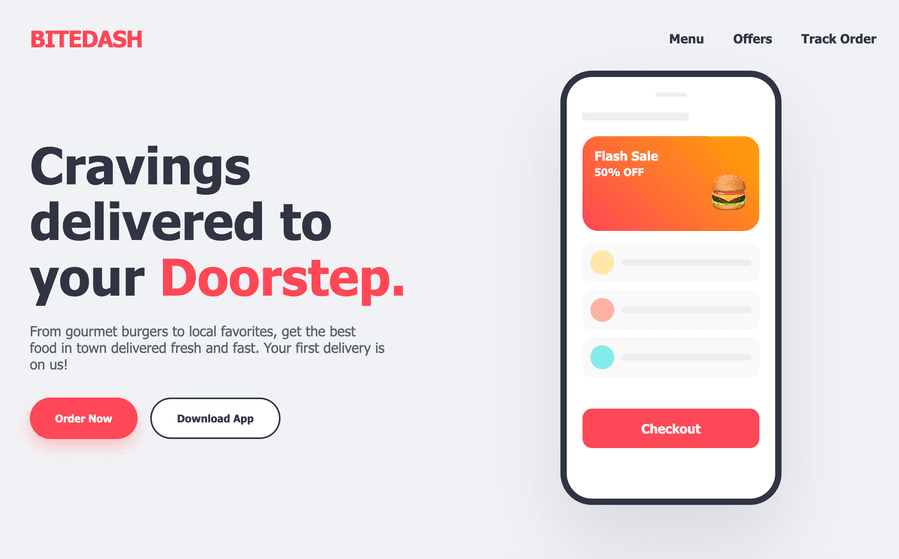
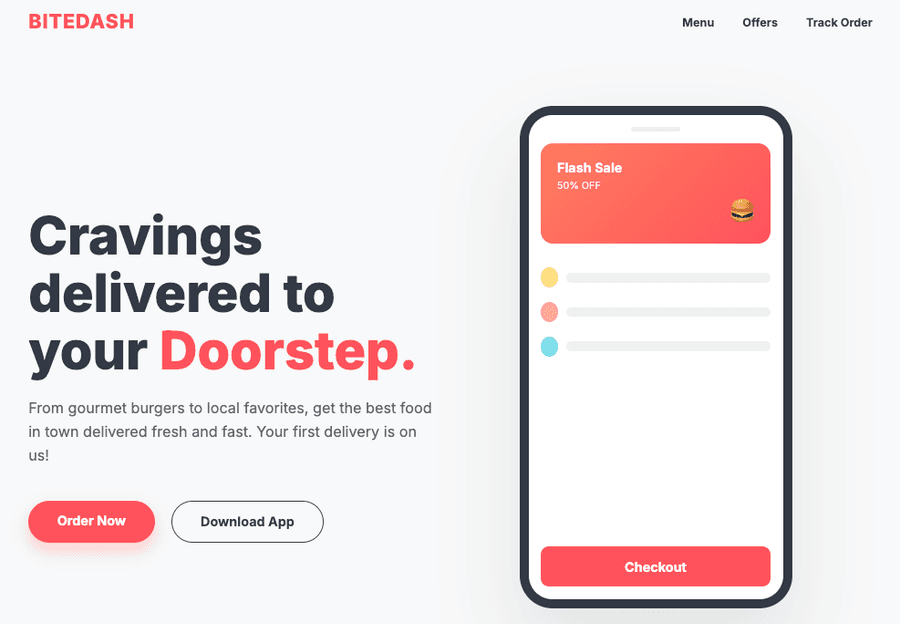
Просим Gemma 4 написать HTML-код для воссоздания страницы, сгенерированной в Gemini 3. Включаем thinking и задаём лимит в 4000 токенов.
Сайт, сгенерированный Gemini (эталон)
Страница, воспроизведённая Gemini
Код инференса
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/landing_page.png",
},
{"type": "text", "text": "Write HTML code for this page."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
enable_thinking=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=4000)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
result = processor.parse_response(generated_text)
print(result["content"])E2B
E4B
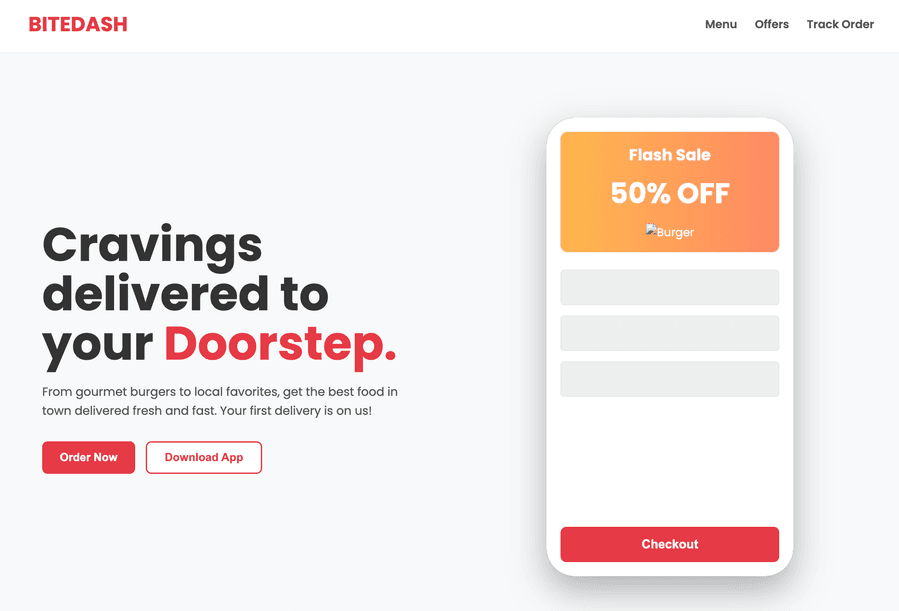
31B
26/A4B
Понимание видео
Компактные модели Gemma 4 могут принимать видео с аудио, а крупные — видео без аудио. Хотя модели не были явно дообучены на видео, они понимают видеоконтент в обоих режимах. Особенно сильна модель в аудио.
Код инференса
messages = [
{
"role": "user",
"content": [
{"type": "video", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/concert.mp4"},
{"type": "text", "text": "What is happening in the video? What is the song about?"},
],
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
load_audio_from_video=True, # отключите для крупных моделей
).to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
print(result["content"])| Модель | Результат |
|---|---|
| E2B (галлюцинация по аудио) | На видео запечатлено живое музыкальное выступление, вероятно, на крупном открытом фестивале или концерте. Сцена: большая сцена на открытом воздухе с осветительными конструкциями, крупными колонками и аудиторией на переднем плане. Исполнители: несколько музыкантов на сцене. В центре — солист/гитарист в синей рубашке и белых штанах. Атмосфера: энергичная и драматичная, с яркими прожекторами и значительным количеством сценического дыма. |
| E4B ✅ | На видео — живое выступление группы на сцене с яркими огнями и эффектами дыма, окружённой зрителями. Песня, судя по всему, о трудностях и разочаровании современной жизни — о чувстве застревания и сложности найти своё место в хаотичном, подавляющем мире. |
| 26/A4B (без аудио) ✅ | На видео — живое музыкальное выступление на открытом концерте или фестивале ночью. Солист в синей рубашке и белых штанах играет на акустической гитаре и поёт в микрофон. На экранах видно название «Estrella Damm». |
| 31B (без аудио) ✅ | Музыкант выступает на сцене во время концерта, играя на акустической гитаре и поя в микрофон. Одет в синюю рубашку и белые штаны. Сцена наполнена атмосферным дымом и освещена яркими синими и белыми огнями. Видны барабанщик и клавишник. |
Подписи к изображениям
Все чекпоинты отлично справляются с детальными подписями к сложным сценам. Промпт: «Write single detailed caption for this image.»

Код инференса
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "/img/uploads/bd6825664104dedec216dc7bdffee765.png"},
{"type": "text", "text": "Write single detailed caption for this image."},
],
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=512)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
result = processor.parse_response(generated_text)
print(result["content"])| Модель | Результат |
|---|---|
| E2B ✅ | Средний план запечатлел ветреную чайку, сидящую на каменном пьедестале на оживлённой европейской площади. Справа доминирует величественное классическое здание с орнаментными колоннами. На заднем плане — низкое светлое здание, зелёная листва и черепичная крыша. Спереди видна часть современной автобусной остановки с указателями маршрутов. |
| E4B ✅ | Одинокая чайка сидит на сером каменном пьедестале в оживлённой европейской пьяцце. Историческое великолепие классического здания доминирует справа, контрастируя с более современной малоэтажной архитектурой на заднем плане под ярким туманным небом. |
| 26B/A4B ✅ | Общий план показывает бело-коричневую чайку на сером пилоне в Венеции, Италия. Чайка смотрит влево. Позади — светло-серое двухэтажное здание с тёмными окнами. Справа — большое белое здание с колоннами и резьбой. Небо ясное, светло-голубое. |
| 31B ✅ | Снимок сверху под углом показывает бело-серую чайку на сером бетонном пилоне в Венеции. Оранжевый клюв слегка приоткрыт. На заднем плане — несколько зданий: длинное низкое белое, зелёные деревья, красное с черепицей, и крупное белокаменное с колоннами и скульптурами. В левом нижнем углу — жёлтый автобус с надписью «Ferrovia». |
Вопросы-ответы по аудио
Модели обучены отвечать на вопросы о речи в аудио. Музыка и немузыкальные звуки не входили в тренировочные данные.
Код инференса
messages = [
{
"role": "user",
"content": [
{"type": "audio", "url": "https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/obama_first_45_secs.mp3"},
{"type": "text", "text": "Can you describe this audio in detail?"},
],
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
output = model.generate(
**inputs,
max_new_tokens=1000,
do_sample=False,
)
print(processor.decode(output[0], skip_special_tokens=True))| Модель | Результат |
|---|---|
| E2B | Это личное размышление. Говорящий рассказывает о своём прощальном обращении к нации, которое он произнёс в Чикаго. Он выражает благодарность за разговоры с американским народом — в гостиных, школах, на фермах, заводах, в закусочных и на военных аутпостах. |
| E4B | Аудиофрагмент речи, где оратор произносит прощальное обращение к нации из Чикаго. Говорящий вспоминает своё время в должности, выражая благодарность за разговоры с американцами в различных обстановках. Тон — рефлексивный и appreciative. |
Пример транскрипции:
Код инференса
messages = [
{
"role": "user",
"content": [
{"type": "audio", "url": "https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/obama_first_45_secs.mp3"},
{"type": "text", "text": "Transcribe the audio?"},
],
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
output = model.generate(
**inputs,
max_new_tokens=1000,
do_sample=False,
)
print(processor.decode(output[0], skip_special_tokens=True))| Модель | Результат |
|---|---|
| E2B | This week I traveled to Chicago to deliver my final farewell address to the nation following in the tradition of presidents before me It was an opportunity to say thank you whether we’ve seen eye to eye or rarely agreed at all my conversations with you the American people in living rooms and schools at farms and on factory floors at diners and on distant military outposts all these conversations are what have kept me honest |
| E4B | This week I traveled to Chicago to deliver my final farewell address to the nation following in the tradition of presidents before me. It was an opportunity to say thank you. Whether we’ve seen eye to eye or rarely agreed at all, my conversations with you, the American people, in living rooms and schools, at farms and on factory floors, at diners and on distant military outposts, all these conversations are what have kept me honest. |
Мультимодальный function calling
Тестируем модель: просим узнать погоду в месте, показанном на изображении.
Код инференса
import re
WEATHER_TOOL = {
"type": "function",
"function": {
"name": "get_weather",
"description": "Gets the current weather for a specific location.",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "The city name"},
},
"required": ["city"],
},
},
}
tools = [WEATHER_TOOL]
messages = [
{"role": "user", "content": [
{"type": "image", "image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/thailand.jpg"},
{"type": "text", "text": "What is the city in this image? Check the weather there right now."},
]},
]
inputs = processor.apply_chat_template(
messages,
tools=[WEATHER_TOOL],
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
enable_thinking=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=1000)
input_len = inputs.input_ids.shape[-1]
generated_text_ids = output[0][input_len:]
generated_text = processor.decode(generated_text_ids, skip_special_tokens=True)
result = processor.parse_response(generated_text)
print(result["content"])| Модель | Результат |
|---|---|
| E2B | Модель анализирует изображение, идентифицирует архитектуру как характерную для Юго-Восточной Азии (вероятно, Wat Arun или аналогичное сооружение), определяет город как Бангкок и вызывает get_weather(city="Bangkok") |
| E4B | Модель распознаёт тайскую архитектуру (chedi/prang), предполагает Бангкок на основе визуальных признаков и формирует корректный tool call: get_weather(city="Bangkok") |
| 31B | Модель определяет prangs как характерные для королевских храмовых комплексов Бангкока (Wat Phra Kaew или Wat Pho), идентифицирует город и вызывает get_weather(city="Bangkok") |
| 26/A4B | Модель распознаёт башни Grand Palace или Wat Phra Kaew в Бангкоке, подтверждает локацию и вызывает get_weather(city='Bangkok') |
Разворачивайте где угодно
Gemma 4 получила поддержку с первого дня (day-0) в множестве open-source движков инференса. Мы также публикуем ONNX-чекпоинты, runnable на различных аппаратных бэкендах — для edge-устройств (телефонов, IoT) и браузеров.
transformers
Gemma 4 имеет первоклассную поддержку в transformers с первого дня 🤗. Интеграция позволяет использовать модель с bitsandbytes, PEFT и TRL. Убедитесь, что у вас последняя версия:
pip install -U transformersПростейший способ инференса с компактными моделями — через any-to-any pipeline:
from transformers import pipeline
pipe = pipeline("any-to-any", model="google/gemma-4-e2b-it")Передавайте изображения и текст:
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/thailand.jpg",
},
{"type": "text", "text": "Do you have travel advice going to here?"},
],
}
]
output = pipe(messages, max_new_tokens=100, return_full_text=False)
output[0]["generated_text"]
# Based on the image, which appears to show a magnificent, ornate **Buddhist temple or pagoda**...Для видео с аудио используйте аргумент load_audio_from_video:
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/rockets.mp4",
},
{"type": "text", "text": "What is happening in this video?"},
],
}
]
pipe(messages, load_audio_from_video=True)На нижнем уровне загрузите модель через AutoModelForMultimodalLM — это особенно удобно для файн-тюнинга. Встроенный chat template корректно форматирует входы. Обязательно используйте его, чтобы избежать тонких ошибок при ручной сборке.
Код инференса
from transformers import AutoModelForMultimodalLM, AutoProcessor
model = AutoModelForMultimodalLM.from_pretrained("google/gemma-4-E2B-it", device_map="auto")
processor = AutoProcessor.from_pretrained("google/gemma-4-E2B-it")
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/rockets.mp4",
},
{"type": "text", "text": "What is happening in this video?"},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Llama.cpp
Gemma 4 из коробки поддерживает изображение + текст в llama.cpp! Это открывает доступ через любимые локальные приложения: llama-cpp server, lmstudio, Jan, а также через coding-агентов вроде Pi — на бэкендах Metal, CUDA и других.
Установка:
brew install llama.cpp # MacOS
winget install llama.cpp # WindowsЗапуск сервера, совместимого с OpenAI API (замените схему квантизации на нужную):
llama-server -hf ggml-org/gemma-4-E2B-it-GGUF:Q4_K_MПодробнее о комбинации llama.cpp с разными агентами. Все GGUF-чекпоинты — в этой коллекции.
Подключение к локальному агенту
Мы убедились, что новые модели работают локально с агентами openclaw, hermes, pi и open code — всё благодаря llama.cpp. Запустите локальный сервер:
llama-server -hf ggml-org/gemma-4-26b-a4b-it-GGUF:Q4_K_MДля hermes:
hermes modelДля openclaw:
openclaw onboardДля pi — определите ~/.pi/agent/models.json:
{
"providers": {
"llama-cpp": {
"baseUrl": "http://localhost:8080/v1",
"api": "openai-completions",
"apiKey": "none",
"models": [
{
"id": "ggml-org-gemma-4-26b-4b-gguf"
}
]
}
}
}Для open code — определите ~/.config/opencode/opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8080/v1"
},
"models": {
"gemma-4-<size>-it": {
"name": "Gemma 4 (local)",
"limit": {
"context": 128000,
"output": 8192
}
}
}
}
}
}transformers.js
transformers.js позволяет запускать Gemma 4 прямо в браузере. Подробности о text-only, image+text, audio+text инференсе — в модельной карте. Готовое демо — здесь.
MLX
Полная мультимодальная поддержка Gemma 4 доступна через open-source библиотеку mlx-vlm. Пример описания изображения:
pip install -U mlx-vlmmlx_vlm.generate \
--model google/gemma-4-E4B-it \
--image https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg \
--prompt "Describe this image in detail"mlx-vlm поддерживает TurboQuant — точность на уровне несжатого baseline при ~4-кратном снижении потребления активной памяти и значительном ускорении. Это делает инференс с длинным контекстом практичным на Apple Silicon без потери качества:
mlx_vlm.generate \
--model "mlx-community/gemma-4-26B-A4B-it" \
--prompt "Your prompt here" \
--kv-bits 3.5 \
--kv-quant-scheme turboquantПримеры с аудио и подробности — в коллекции MLX.
Mistral.rs
mistral.rs — нативный Rust-движок инференса с поддержкой Gemma 4 с первого дня по всем модальностям (текст, изображение, видео, аудио). Встроены tool-calling и agentic-функционал. Установка:
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.sh | sh # Linux/macOS
irm https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.ps1 | iex # WindowsHTTP-сервер, совместимый с OpenAI:
mistralrs serve mistralrs-community/gemma-4-E4B-it-UQFF --from-uqff 8Или интерактивный режим:
mistralrs run -m google/gemma-4-E4B-it --isq 8 --image image.png -i "Describe this image in detail."
mistralrs run -m google/gemma-4-E4B-it --isq 8 --audio audio.mp3 -i "Transcribe this fully."Все модели — в этой коллекции. Инструкции по установке и инференсу — в модельных картах.
Файн-тюнинг
Gemma 4 идеально подходит для дообучения в любых инструментах и на любом бюджете.
Файн-тюнинг с TRL
Gemma 4 полностью поддерживается в TRL. К релизу TRL получил поддержку мультимодальных ответов от инструментов при взаимодействии со средами. Теперь модели могут получать от инструментов не только текст, но и изображения.
Чтобы продемонстрировать это, мы подготовили скрипт, где Gemma 4 учится водить машину в симуляторе CARLA. Модель видит дорогу через камеру, принимает решения и учится на результате. После обучения она стабильно перестраивается в ряды, обходя пешеходов. Подход работает для любой задачи, где модели нужно видеть и действовать: робототехника, веб-браузинг, интерактивные среды.
Начало работы:
# pip install git+https://github.com/huggingface/trl.git
python examples/scripts/openenv/carla_vlm_gemma.py \
--env-urls https://sergiopaniego-carla-env.hf.space \
https://sergiopaniego-carla-env-2.hf.space \
--model google/gemma-4-E2B-itФайн-тюнинг с TRL на Vertex AI
Мы также подготовили пример файн-тюнинга Gemma 4 с TRL на Vertex AI через SFT (supervised fine-tuning, дообучение на размеченных данных). Пример показывает, как расширить возможности function calling, заморозив при этом визуальную и аудио-башни (энкодеры изображений и аудио). Пример включает сборку кастомного Docker-контейнера с последними Transformers, TRL и поддержкой CUDA на Google Cloud. А также запуск через Vertex AI Serverless Training Jobs.
# pip install google-cloud-aiplatform --upgrade --quiet
from google.cloud import aiplatform
aiplatform.init(
project="<PROJECT_ID>",
location="<LOCATION>",
staging_bucket="<BUCKET_URI>",
)
job = aiplatform.CustomContainerTrainingJob(
display_name="gemma-4-fine-tuning",
container_uri="<CONTAINER_URI>",
command=["python", "/gcs/gemma-4-fine-tuning/train.py"],
)
job = job.submit(
replica_count=1,
machine_type="a3-highgpu-1g",
accelerator_type="NVIDIA_H100_80GB",
accelerator_count=1,
base_output_dir="<BUCKET_URI>/output-dir",
environment_variables={
"MODEL_ID": "google/gemma-4-E2B-it",
"HF_TOKEN": <HF_TOKEN>,
},
boot_disk_size_gb=500,
)Полный пример — в документации «Hugging Face on Google Cloud»: https://hf.co/docs/google-cloud/examples/fine-tune-gemma-4.
Файн-тюнинг с Unsloth Studio
Если вы хотите дообучать и запускать Gemma 4 через UI, попробуйте Unsloth Studio — работает локально или на Google Colab. Установка и запуск:
# install unsloth studio on MacOS, Linux, WSL
curl -fsSL https://unsloth.ai/install.sh | sh
# install unsloth studio on Windows
irm https://unsloth.ai/install.ps1 | iex
# launch unsloth studio
unsloth studio -H 0.0.0.0 -p 8888
# Найдите модель Gemma 4, например google/gemma-4-E2B-itЗатем выберите любую из моделей Gemma 4 на хабе.
Попробуйте Gemma 4
Мы подготовили демо для тестирования разных моделей: на базе transformers для E4B, 26B/A4B и dense-31B, а также WebGPU-демо на transformers.js 🚀
Благодарности
Интеграция Gemma 4 в open-source-экосистему — результат работы множества людей, а не только авторов этого поста. Без особого порядка: интеграция в transformers — заслуга Cyril, Raushan, Eustache, Arthur, Lysandre. transformers.js-интеграция и демо — Joshua. mistral.rs — Eric. Llama.cpp — Son. MLX — Prince. TRL — Quentin. SGLang transformers backend — Adarsh. Демо — Toshihiro. Эта работа была бы невозможна без значительного вклада Google — не только в саму модель, но и в её интеграцию в transformers для стандартизации. Open-source-экосистема стала богаче: теперь в ней есть по-настоящему способная, свободно лицензированная открытая модель.