
Китайская AI-компания Zhipu AI выпустила GLM-5V-Turbo — свою первую мультимодальную базовую модель для кодинга. Она обрабатывает изображения, видео и текст, а создана специально для агентных рабочих процессов (agent-воркфлоу).
Zhipu AI хочет закрыть разрыв между визуальным пониманием и генерацией кода. Вместо работы с одним текстом модель анализирует дизайн-макеты и генерирует исполняемый код напрямую из них. По заявлению компании, модель интегрируется в агенты вроде Claude Code и OpenClaw, замыкая полный цикл: «понять окружение → спланировать действия → выполнить задачу».
Контекстное окно — 200 000 токенов, максимальный вывод — 128 000 токенов. Поддерживаются режим пошагового рассуждения (thinking mode), потоковый вывод (streaming), вызов функций (function calling) и кэширование контекста.
Как зрение и код объединились в одной модели
Z.AI объясняет высокие результаты GLM-5V-Turbo улучшениями в четырёх областях: архитектура модели, методы обучения, построение данных и инструментарий.
Модель учится обрабатывать изображения и текст вместе с самого начала обучения, а не получает добавленный модуль распознавания изображений уже к готовой языковой модели. Для этого Z.AI разработала новый модуль кодирования изображений (vision encoder) под названием CogViT. Кроме того, во время инференса модель предсказывает несколько токенов одновременно, что ускоряет генерацию.
Обучение с подкреплением (reinforcement learning) оптимизирует модель более чем по 30 типам задач: STEM, привязка объектов к координатам на изображении (grounding), видео, GUI-агенты и кодинг-агенты. Это повышает устойчивость восприятия, рассуждений и агентного выполнения.
Видео: пример работы GLM-5V-Turbo
Для борьбы с нехваткой обучающих данных для агентов Z.AI построила многоуровневую контролируемую и верифицируемую систему данных. Агентные мета-навыки заложены ещё на этапе предобучения, чтобы усилить предсказание и выполнение действий на ранней стадии.
Новый мультимодальный набор инструментов (toolchain) расширяет возможности агента от чистого текста до визуального взаимодействия. Инструменты для рисования прямоугольных рамок вокруг объектов (баундинг-боксов), скриншотов и чтения сайтов — включая понимание изображений — замыкают цикл «восприятие → планирование → выполнение».
Сильные цифры в бенчмарках по кодингу и GUI-агентам
По данным Z.AI, GLM-5V-Turbo показывает лидирующие результаты в мультимодальных задачах кодинга и агентных сценариях. Модель хорошо справляется с генерацией кода по дизайну, визуальной генерацией кода, мультимодальным поиском и визуальным исследованием.
Она также выдаёт высокие оценки на AndroidWorld и WebVoyager — двух бенчмарках, тестирующих способность агента навигировать по реальным графическим интерфейсам (GUI).
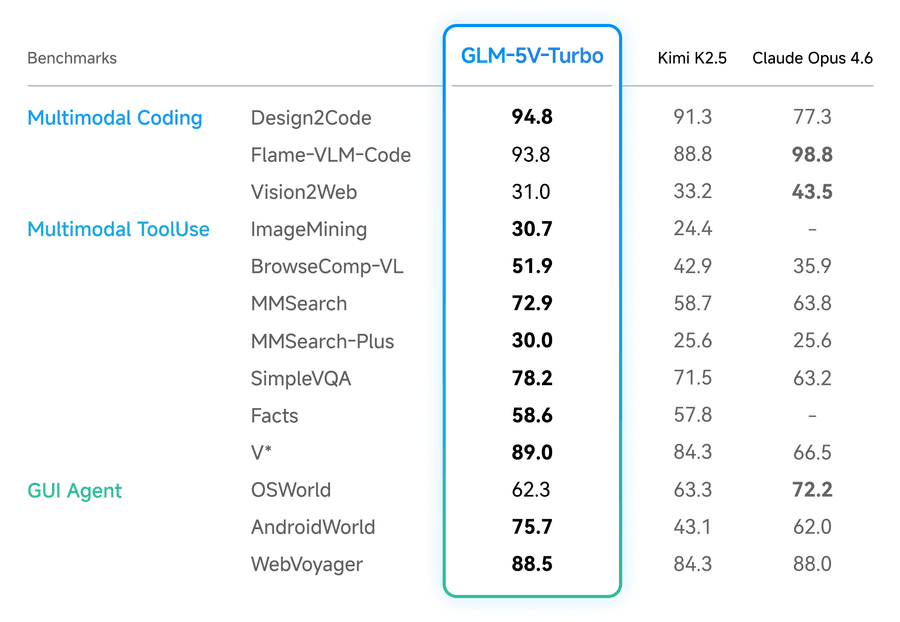
Z.AI заявляет, что GLM-5V-Turbo лидирует в большинстве категорий мультимодального кодинга и использования инструментов. Claude Opus 4.6 обходит её в отдельных бенчмарках, таких как Flame-VLM-Code и OSWorld. | Изображение: Z.AI
В задачах чисто текстового кодинга GLM-5V-Turbo, по утверждениям разработчиков, не теряет в качестве несмотря на добавленные визуальные возможности. Модель уверенно держится на трёх ядровых бенчмарках CC-Bench-V2 (backend, frontend, исследование репозитория). Она также набирает высокие баллы на PinchBench, ClawEval и ZClawBench, измеряющих качество выполнения задач. Независимая оценка пока отсутствует.

В текстовых бенчмарках по кодингу и агентным задачам Claude Opus 4.6 лидирует в целом, но GLM-5V-Turbo обходит свою текстовую версию GLM-5-Turbo и Kimi K2.5 в ряде категорий. | Изображение: Z.AI
Дизайн-макеты превращаются в рабочий фронтенд-проект
GLM-5V-Turbo нацелен на несколько конкретных сценариев использования. Модель принимает дизайн-макеты или референсные изображения и генерирует полный, запускаемый фронтенд-проект. Она восстанавливает структуру вайрфреймов (чертежей структуры страниц) и функциональность, стремясь к попиксельному совпадению (pixel-perfect) с высокоразмерными дизайн-макетами.
В связке с фреймворками вроде Claude Code модель занимается автономным GUI-исследованием: самостоятельно ищет целевые сайты, составляет карту переходов между страницами, собирает визуальные ассеты (изображения, иконки и другие ресурсы) и детали взаимодействия, затем пишет код на основе собранного. Z.AI называет это переходом от «воссоздания по скриншоту» к «воссозданию через автономное исследование».
Для дебаггинга модель делает скриншоты сломанных страниц, автоматически находит проблемы рендеринга — сдвиги layout’а, наложения компонентов, несовпадения цветов — и генерирует код исправлений. С интегрированным GLM-5V-Turbo OpenClaw также понимает структуру сайтов, GUI-элементы и диаграммы, что помогает ему решать более сложные задачи на стыке восприятия, планирования и выполнения.
Z.AI поставляет официальные скиллы (модули-навыки для агентов): создание текстовых описаний изображений (captioning), привязку текста к объектам на изображении (visual grounding), написание текстов по документам, скрининг резюме и генерацию промптов — всё доступно на ClawHub. Пока GLM-5V-Turbo доступен только как API на платформе Z.AI по цене $1,20 за миллион входных токенов и $4 за миллион выходных — столько же, сколько текстовый GLM-5-Turbo, и чуть дороже базового GLM-5. Открытые веса (исходные файлы модели) пока не анонсированы.
GLM-5-Turbo и GLM-5 подготовили почву
Недавно Z.AI выпустила GLM-5-Turbo — текстовую модель, созданную для агентного фреймворка OpenClaw. У неё улучшены вызовы инструментов (tool call), следование инструкциям, управление временными и долгосрочными (персистентными) задачами, а также выполнение длинных цепочек задач.
Вместе с ней Z.AI представила ZClawBench — сквозной бенчмарк (end-to-end) для агентных задач в экосистеме OpenClaw. Результаты показывают, что GLM-5-Turbo значительно превосходит предшественника GLM-5 и обходит Claude Opus 4.6, Gemini 3.1 Pro, MiniMax M2.5 и Kimi K2.5 в нескольких категориях. Использование скиллов в экосистеме OpenClaw за короткое время выросло с 26 до 45 процентов — Z.AI считает это признаком наблюдающегося роста модульных агентных систем.
До этого, в середине февраля, Zhipu AI выпустила GLM-5 — модель с открытым исходным кодом (open-source) на 744 миллиарда параметров под лицензией MIT. Компания заявляет, что она конкурирует с Claude Opus 4.5 и GPT-5.2 в задачах кодинга и агентных сценариях. На SWE-bench Verified GLM-5 набрала 77,8%, ненамного отстав от Claude Opus 4.5 с 80,9%. Модель также работает на китайских чипах от Huawei и других производителей наряду с GPU Nvidia — существенное преимущество при американских экспортных ограничениях.
Похожий подход использует Alibaba с моделью Qwen3.5-Omni — омнимодальной моделью (работающей со всеми типами данных одновременно), обрабатывающей текст, изображения, аудио и видео. Как и GLM-5V-Turbo, она генерирует код по визуальному вводу, но дополнительно принимает голосовые инструкции.