
Anthropic официально выпустила Claude Opus 4.7 — новую флагманскую модель линейки Opus. OpenAI в тот же день выпустила GPT-Rosalind и обновлённый Codex с удачным computer use (управление компьютером через интерфейс), но главный релиз четверга бесспорно за Anthropic. Слухи ходили минимум неделю — реальность даже немного превзошла ожидания.
Ключевая картина:
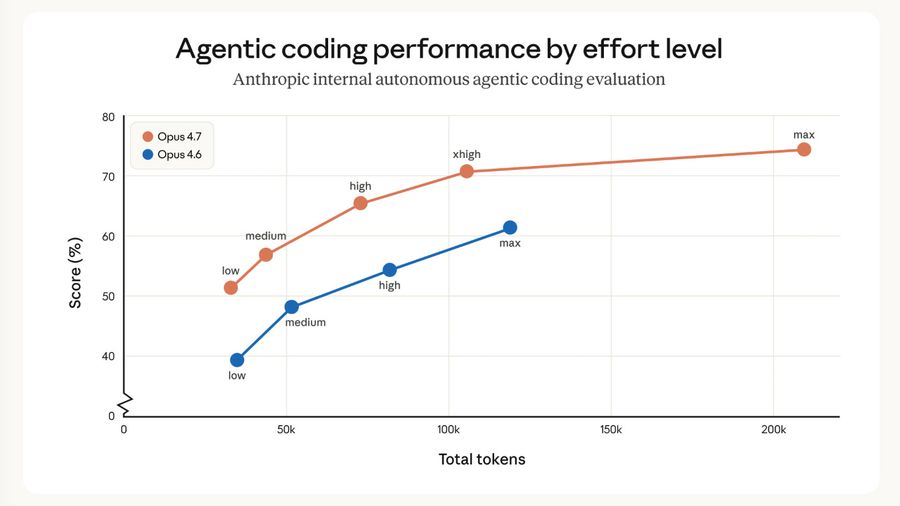
Суть проста: 4.7-low надёжно лучше 4.6-medium, 4.7-medium надёжно лучше 4.6-high, 4.7-high обходит 4.6-max. Новый уровень xhigh стал дефолтом в Claude Code. Новый tokenizer (алгоритм разбиения текста на токены) может увеличивать расход токенов на 35%. Но общая эффективность reasoning (цепочки логических рассуждений) настолько выросла, что суммарный расход токенов снизился до 50% относительно аналогичных конфигураций 4.6. Настоящая проверка — вырастет ли SWE-Bench Pro на 11 пунктов в ваших реальных задачах.
Вторая ключевая особенность, которую надо видеть самому, — substantially better vision. Opus 4.7 принимает изображения до 2 576 px по длинной стороне (~3,75 мегапикселя), более чем в три раза больше предыдущих моделей Claude. Это открывает множество мультимодальных сценариев: computer-use агенты, читающие плотные скриншоты, извлечение данных из сложных диаграмм, задачи с pixel-perfect референсами.
Что именно выпустили
Anthropic позиционирует Opus 4.7 как модель, лучше 4.6 во всём: длинные задачи, кодинг, следование инструкциям, самопроверка, computer use, интеллектуальная работа. Цены не изменились: $5 / $25 за миллион input/output токенов.
Официальный фокус — три поведенческих улучшения: лучше справляется с длинными задачами, точнее следует инструкциям, сильнее верифицирует ответ перед выдачей.
Доступность:
- Claude platform / app — сразу после релиза.
- Claude Code — поддержка с первого дня,
xhighкак уровень reasoning по умолчанию. - Публичная бета task budgets (бюджетов токенов на задачу),
/ultrareviewв Claude Code, расширенный доступ к Auto mode для Claude Code Max.
Новый уровень reasoning
Появился xhigh — между high и max. Claude Code теперь использует его по умолчанию для Opus 4.7.
Vision и computer use
- Изображения до 2 576 px по длинной стороне (~3,75 MP) — в три раза больше прежнего лимита.
- Меньше даунскейлинга высокоразрешительных изображений.
- Улучшен «вкус» при генерации UI/слайдов/документов.
- Напрямую связано с лучшим computer use и workflows со скриншотами.
Новый tokenizer и экономика токенов
Opus 4.7 использует другой tokenizer, чем 4.6. Один и тот же вход может превращаться в 1,0–1,35× больше токенов в зависимости от типа контента. Это вызвало дискуссию: новый base model (базовая модель без дополнительной настройки)? midtraining (этап дообучения)? дистилляция (перенос знаний от большей модели к меньшей) Mythos?
Anthropic компенсировала рост расхода, повысив лимиты для всех подписчиков.
Бенчмарки
| Бенчмарк | Opus 4.7 | Дельта vs 4.6 |
|---|---|---|
| SWE-bench Pro | 64,3% | +11 п. |
| SWE-bench Verified | 87,6% | +7 п. |
| TerminalBench 2.0 | 69,4% | +4 п. |
| Document reasoning | 80,6% | с 57,1% |
| GDPval-AA | 1753 Elo | #1 |
| ARC-AGI-1 | 92% | — |
| ARC-AGI-2 | 75,83% | — |
Artificial Analysis зафиксировал Opus 4.7 как #1 на GDPval-AA с примерным 60% win rate против GPT-5.4.
Vals AI: #1 на Vals Index (71,4%), предыдущий максимум — 67,7%. Также #1 на Vibe Code Bench, Vals Multimodal, Finance Agent, Mortgage Tax, SAGE, SWE-Bench и Terminal Bench 2. На Vibe Code Benchmark модель набрала 71% — для сравнения, 4,5 месяца назад ни одна модель не пробивала 25%.
Отклик платформ
- Cursor: внутренний бенчмарк прыгнул с 58% до 70%.
- Notion: +14% на внутренних evaluations, при этом ошибки инструментов сократились втрое.
- GitHub: сообщил о схожих улучшениях, без конкретных цифр.
Независимая оценка от LlamaIndex
LlamaIndex провёл ParseBench-сравнение и получил более нюансированную картину:
| Метрика | Opus 4.6 | Opus 4.7 |
|---|---|---|
| Диаграммы | 13,5% | 55,8% |
| Форматирование | 64,2% | 69,4% |
| Содержание | 89,7% | 90,3% |
| Таблицы | 86,5% | 87,2% |
| Компоновка | 16,5% | 14,0% ↓ |
Jerry Liu из LlamaIndex отметил, что модель хороша с таблицами и диаграммами, но для OCR-подобных задач дороговата: ~7¢/страницу против ~1,25¢ в agentic-режиме (режиме работы через автономных агентов) и ~0,4¢ в cost-effective (экономичном режиме). Наглядный пример: общие возможности выросли, но для конкретных enterprise-пайплайнов специализированные стеки всё ещё могут быть выгоднее.
Что это за модель на самом деле
Слухов и интерпретаций много:
- «Это дистилляция Mythos» — интерпретация, не факт.
- «Это новый base model, потому что изменился tokenizer» — логично, но не подтверждено Anthropic.
- «Anthropic искусственно занизила кибер-возможности при обучении» — отчасти подтверждается system card (документом с оценкой рисков модели). Anthropic экспериментировала с дифференциальным снижением некоторых capabilities, но более широкие claims о «ослабленном Mythos» — это интерпретация.
- «Бенчмарки не передают масштаба, в реальном использовании огромный прыжок» — субъективно, но широко повторяется практиками.
- «System prompt лоботомировал модель» — жалоба на изменение поведения, не установленный факт.
Длинный контекст: проблема или нет?
Много пользователей пожаловались, что long-context производительность ухудшилась. Особенно на MRCR / needle-in-a-haystack (метрике поиска нужной информации в длинном тексте). Boris Cherny из Anthropic ответил, что MRCR выводится из использования. Эта метрика переоценивает distractor-stacking (приёмы добавления отвлекающего контента). А Graphwalks — лучшая метрика прикладного reasoning. По Graphwalks рост с 4.6 до 4.7: 38,7% → 58,6%.
Другие претензии
- Изменение tokenizer вызвало жалобы на то, что Opus стал потреблять значительно больше токенов при неизменных лист-ценах.
- В веб-версии Claude доступен только режим «Adaptive» или без-thinking — без принудительного включения reasoning. Для некодинговых задач это ощущается регрессом.
- Жалобы на новый system prompt, который меняет поведение модели не в лучшую сторону.
Как правильно работать с Opus 4.7
Тред Cat Wu из Anthropic — полезный операционный сигнал для инженеров:
- Делегируйте, не микроменеджьте — относитесь к модели как к инженеру, которому вы передали задачу, а не как к pair-programmer’у, за которым нужно следить.
- Выносите цель + ограничения + критерии приёмки наверх.
- Скажите модели, как верифицировать изменения — зашейте тестовые workflow в
claude.mdили skills.
Это прямо говорит о том, что Anthropic оптимизировала модель под автономные task loops, где центральное место занимает явная валидация.