
После пары месяцев задержек и слухов DeepSeek наконец выпустила долгожданную DSV4. Это первое крупное обновление архитектуры с декабря 2024 (V3) и января 2025 (R1). Семейство выводит DeepSeek в один ряд с Kimi K2.6 — текущим лидером среди открытых моделей — и Xiaomi Mimo 2.5, выпущенной двумя днями ранее.
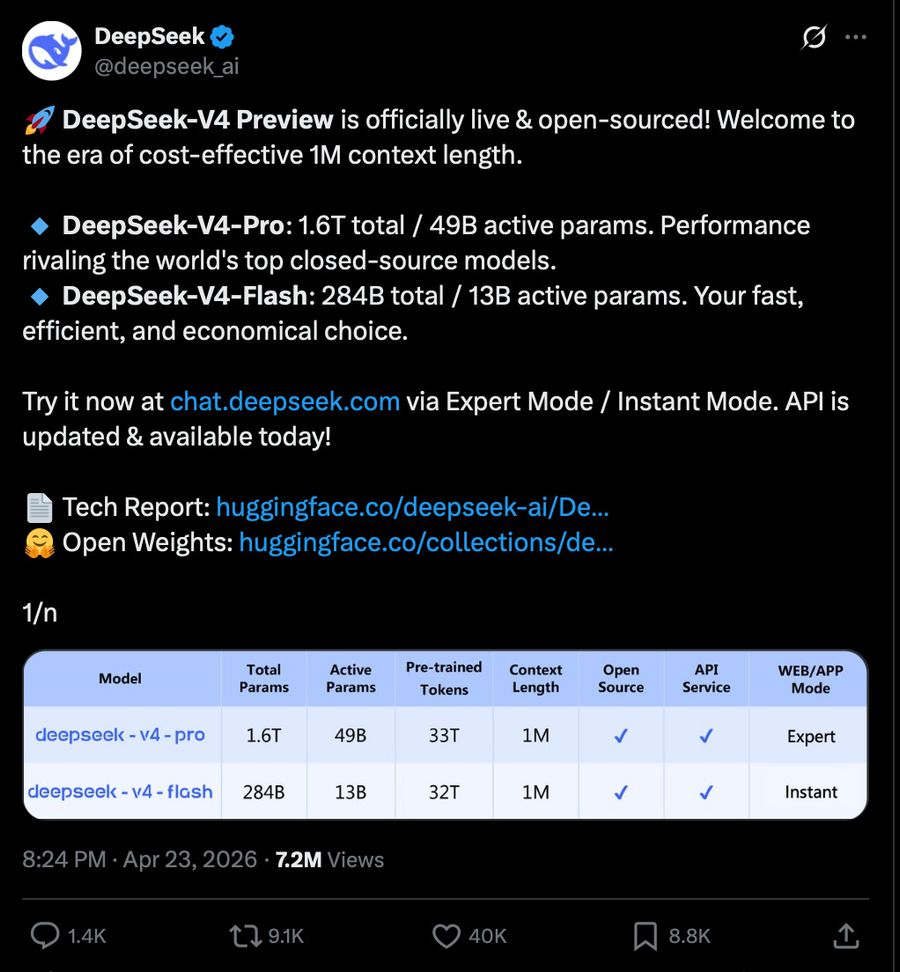
DSV4 — модель уровня Gemini 3.1 / GPT 5.4 / Opus 4.6. Это MOE-архитектура (Mixture of Experts — только часть параметров активна на каждый токен) на 1.6T параметров. Модель обучена на 32T токенов с использованием FP4 (формат чисел с 4-битной точностью). Контекст — 1M токенов, обеспечивается новыми механизмами Compressed Sparse Attention (CSA) и Heavily Compressed Attention (HCA). Для DeepSeek редкость — одновременно выпущены и Base, и Instruct-версии. Это закладывает фундамент для возможного «DeepSeek R2», хотя reasoning-режим уже встроен.
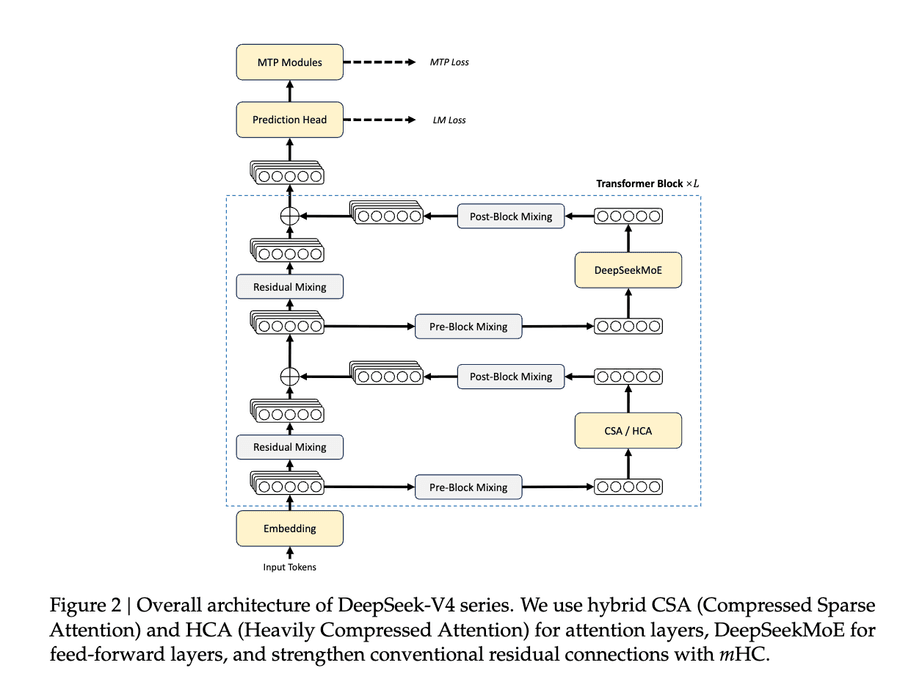
Технические детали
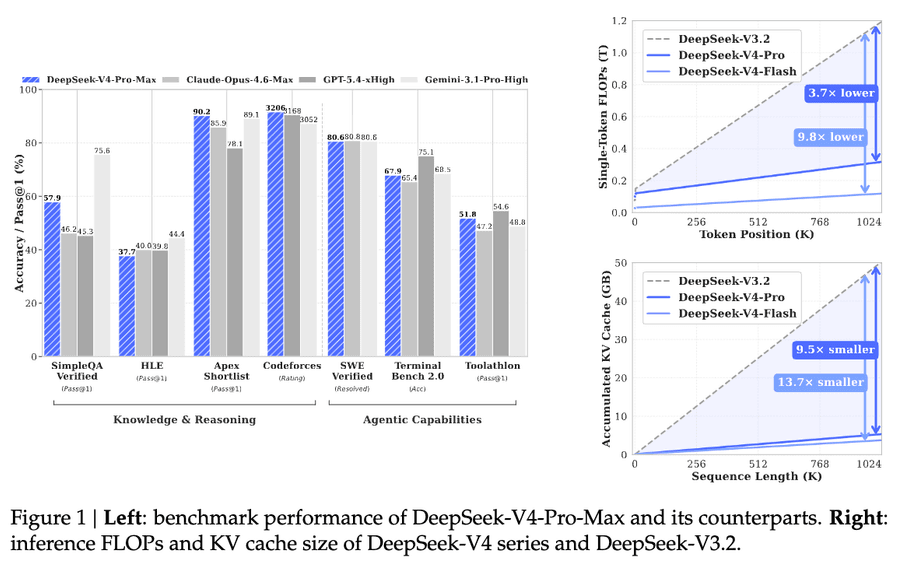
Технический отчёт на 58 страниц содержит детали обучения и инференса. Включает улучшения из статьи о Manifold Constrained Hyper-Connections (mHC), продолженное использование Moonshot Muon и впечатляющую оптимизацию внимания. CSA/HCA на 1M токенов требуют лишь 27% вычислений (FLOPs) и 10% KV-кэша (кэш ключей и значений механизма внимания) по сравнению с DeepSeek-V3.2:
Две модели
- V4 Pro: 1.6T общих параметров / 49B активных
- V4 Flash: 284B общих / 13B активных
Контекст
1M токенов (рост с 128K у V3.2) — главный технический результат релиза.
Масштаб обучения
32–33T токенов, ~20 токенов на параметр. Оценка вычислений предобучения — ~1×10²⁵ FLOPs.
Режимы работы
Три reasoning-режима, гибридная модель «thinking/non-thinking».
Архитектура длинного контекста
Гибридная система внимания:
- Shared KV-векторы — 2× сжатие KV
- c4a — ~4× сжатие
- c128a — ~128× сжатие
- Top-k sparse attention по сжатым токенам
- Sliding window на 128 токенов
- 1M контекст = 9.62 GiB на последовательность (bf16) — в 8.7× меньше, чем 83.9 GiB у V3.2
- FP4-индексный кэш + FP8 attention-кэш дают ещё ~2× сокращение
Итого: ~10× сжатие KV cache.
Квантование и формат
Чекпоинт — FP4 + FP8 смешанная точность:
- MoE-эксперты в FP4
- Attention / norm / router в FP8
- Полная модель помещается на один узел 8×B200
Инференс и железо
- На Blackwell Ultra V4 Pro выдаёт 150+ TPS на пользователя для agentic-воркфлоу (задач, где модель действует как автономный агент)
- Дневная поддержка через vLLM на H200, MI355, B200, B300, GB200/300
- V4 Flash запускается на Mac с 256GB RAM, опубликованы MLX-кванты
- Важно: llama.cpp / Ollama / LM Studio пока не поддерживают tensor parallel (разделение вычислений между несколькими GPU) — для серьёзного multi-GPU serving нужен vLLM
Лицензия и цены
MIT-лицензия. API от DeepSeek + быстрое подключение через Together, Baseten, Nous Research.
| Модель | Вход (за 1M токенов) | Выход (за 1M токенов) |
|---|---|---|
| V4 Pro | $1.74 | $3.48 |
| V4 Flash | $0.14 | $0.28 |
По данным Reuters, DeepSeek заявляла, что цены на Pro могут существенно снизиться. Это произойдёт, когда Huawei Ascend 950 supernodes масштабируются во второй половине года.
Бенчмарки
Синтез от Artificial Analysis:
- V4 Pro Max: 52 на Intelligence Index (+10 к V3.2 с 42) — #2 среди открытых после Kimi K2.6 (54)
- V4 Flash Max: 47 — уровень сильного Claude Sonnet 4.6
- GDPval-AA (agentic-задачи): V4 Pro: 1554 — лидирует среди открытых, впереди Kimi K2.6 (1484) и GLM-5.1 (1535)
- AA-Omniscience: V4 Pro: -10 (улучшение на 11 пунктов), но 94% галлюцинаций; Flash: 96%
- Стоимость прогона AA Index: Pro — $1,071 (190M выходных токенов), Flash — $113 (240M токенов). Низкая цена за токен не означает дешёвую задачу при высоком объёме генерации.
В Text Arena V4 Pro дебютировал на #2 среди открытых, с победой в категории «Медицина и здравоохранение». Thinking-вариант вошёл в топ-10 по математике и естественным наукам.
Противоречивая оценка уровня: от «~Opus 4.5» на SimpleBench до «точно лучше GLM-5.1, но не дотягивает до Opus 4.7 / GPT-5.4 / Gemini 3.1 Pro» в общем зачёте.
Главное — не позиция в таблице, а архитектура
Значительная часть исследователей считает, что длинноконтекстная архитектура важнее, чем строчка в бенчмарках:
- Первый открытый метод, где длинный контекст и agentic post-training реально «встречаются»
- Ожидается, что другие открытые лаборатории переймут элементы архитектуры
- Технический отчёт назвали «одной из лучших статей года». На фоне скудного технического раскрытия у многих frontier-релизов (моделей на границе возможностей) это выделяется
Flash может быть важнее Pro для практики
- Flash@max ≈ Pro@high на reasoning-задачах
- Flash смещает границу цена/производительность
- Бенчмарки могут недооценивать «легитимный 1M контекст за копейки»
- Работает на 256GB Mac
Huawei Ascend и геополитика
Совместимость с Huawei CANN (программным стеком для чипов Huawei) — стратегический шаг. DeepSeek снижает зависимость от NVIDIA/CUDA. Ascend-чипы пока составляют четверть от объёмов H100, но это важная веха для технологического суверенитета Китая. Параллельно отмечается, что V4 косвенно подтверждает правильность roadmap NVIDIA по Blackwell/Rubin/HBM/interconnect.
Ограничения и нюансы
- По совокупной capability всё ещё позади закрытых frontier-моделей — особенно в науках, праве, медицине
- Reasoning RL (обучение с подкреплением для рассуждений) не сильно продвинулся относительно V3.2 Speciale
- Серверный инференс сложен: многие лаборатории обслуживают 20–30 tok/s с ограниченной конкурентностью
- Высокое потребление токенов — дешёвый за токен не значит дешёвый за задачу
- API DeepSeek не позволяет управлять сэмплером (механизмом выбора токенов при генерации)
- Архитектура настолько сложна, что большинство лабораторий не смогут её воспроизвести — спор о том, является ли это «демократизацией»
Три ключевых вывода
-
Длинный контекст в открытых весах — больше не маркетинг. V4 доказывает, что 1M контекст можно сделать операционно пригодным с конкретной KV-cache-инженерией и открытой поддержкой инференса.
-
Китайские лаборатории доминируют в верхнем эшелоне открытых моделей. Kimi, GLM, DeepSeek, а теперь MiMo — занимают верхние строчки.
-
Планка «открытости» поднялась с релиза чекпоинта до full-stack co-design (совместного проектирования всего стека). V4 обсуждается одновременно с vLLM, Blackwell, MLX-квантами, Mac-совместимостью, Ascend-кластерами и архитектурами кэша/памяти.
Инфраструктура и локальная экосистема
Hugging Face запустила ML Intern — open-source CLI «AI-интерн» для ML-работ. Умеет искать статьи, писать код, запускать эксперименты, работать с HF datasets/jobs, искать по GitHub. До 300 итераций.
Meta объявила о добавлении десятков миллионов ядер AWS Graviton для масштабирования Meta AI и agentic-систем на миллиарды пользователей.
В локальном стеке:
- Qwen3.6-27B через llama.cpp на MacBook Pro ощущается близким к Opus во многих coding-задачах
- Бесплатный CLI-агент на базе Pi + Ollama + Gemma 4 + Parallel web search MCP
- Nous/Hermes Agent v0.11.0 с переписанным React TUI, дашбордом, темами, новыми inference-провайдерами и поддержкой QQBot — быстро добавил поддержку DeepSeek V4 и GPT-5.5
- Нативный Linux sandbox для Deep Agents на базе bubblewrap + cgroups v2
Исследования
On-policy distillation token selection — метод дистилляции (переноса знаний от большой модели в меньшую), при котором только часть токенов несёт основной обучающий сигнал. Использование ~50% токенов повторяет или превосходит полное обучение при сокращении памяти на ~47%. Даже <10% токенов (фокус на confidently-wrong) почти дотягивается до полного обучения.
Google Research на ICLR:
- MesaNet — альтернатива transformer, линейный sequence layer, оптимизированный для in-context learning (обучения на примерах внутри промпта) при фиксированной памяти
- Демо «reasoning can lead to honesty»
MIT Hyperloop Transformers комбинируют циклические и обычные transformer-блоки. Используют ~50% меньше параметров при победе над обычными трансформерами на масштабах 240M / 1B / 2B.
Tool Attention Is All You Need — заявляет 95% сокращение tool-токенов (47.3k → 2.4k на ход) через динамическое гейтирование (управление потоком данных) и ленивую загрузку схем.
StructMem — структурированная память для долгогоризонтных агентов. HorizonBench — бенчмарк для персонализации со сдвигающимися предпочтениями пользователя.
GPT-5.5 и coding-агенты
OpenAI выпустила GPT-5.5 и GPT-5.5 Pro в API с окном контекста 1M токенов. Мгновенно появился в Cursor, GitHub Copilot, Codex, OpenRouter, Perplexity, Devin, Droid, Fleet, Deep Agents.
Результаты:
- #1 на CursorBench: 72.8%
- #1 на Terminal-Bench: 82.7
- Perplexity Computer: 56% меньше токенов на сложных задачах
- GPT-5.5 medium стал сильнейшей non-thinking моделью на LisanBench с 45.6% меньшим числом токенов при более высоких баллах
Пользователи отмечают улучшенное качество кода и эффективность по токенам: менее многословный, менее «защитный» код. Cursor также выпустил /multitask — асинхронные субагенты и multi-root workspaces.
Растёт акцент на лимиты и экономику, а не на маржинальные различия в качестве. Usage caps теперь важнее мелких дельт между frontier-моделями.
Рынок, финансирование и политика
- Google планирует инвестировать до $40B в Anthropic
- Cohere и Aleph Alpha объявили канадско-немецкое партнёрство по суверенному AI — enterprise-уровень с фокусом на приватность
- ComfyUI привлёк $30M при оценке $500M, сохраняя open-local-позиционирование
- Mechanize привлёк $9.1M при оценке $500M post-money
- Arcee AI наняла Cody Blakeney на позицию Head of Research с фокусом на открытые американские frontier-модели
- OpenAI объявила Bio Bug Bounty для GPT-5.5
- Anthropic запустила Project Deal — маркетплейс, где Claude вёл переговоры от лица сотрудников, обнажив асимметрию качества модели и политические вызовы
Креативный AI и мультимодальность
GPT Image 2 + Seedance 2 workflows продолжают привлекать внимание: high-fidelity image→video пайплайны. Через экспериментальный API уже доступны 2K/4K изображения.
Kling анонсировал нативный 4K-вывод и конкурс коротких метражей на $25k.
Примечательный нюанс: GPT Images 2.0 корректно отрисовал валидное состояние кубика Рубика — задача, которая неожиданно трудна для генеративных моделей.
Экосистема: что обсуждают
Qwen 3.6 27B стал одним из главных хитов среди локальных моделей. На Agentic Index от Artificial Analysis сравнялся с Claude Sonnet 4.6, обойдя Gemini 3.1 Pro Preview, GPT 5.2/5.3 и MiniMax 2.7. Запускается на RTX 3090 + RTX 5070 Ti (40GB VRAM, Q8, 170K контекст). Однако часть сообщества скептична — возможен «benchmaxxing» (оптимизация результатов под бенчмарки в ущерб реальным задачам). Сравнение 35B-A3B и 27B dense для кода показало, что 27B даёт более точные результаты, несмотря на меньшую скорость (18 vs 72 TPS на MacBook Pro M5 MAX).
DS4-Flash vs Qwen3.6 — Flash обходит Qwen по LiveCodeBench и HLE, но при 284B против 27B разница не так велика. Это поднимает вопросы об эффективности.
DeepEP V2 и TileKernels — DeepSeek выпустила инструменты для оптимизации параллелизации. TileKernels, если заявленное линейное масштабирование подтвердится, удваивает скорость при удвоении вычислительных ресурсов.
Ценообразование V4 Flash вызвало споры. При линейном масштабировании по параметрам V4 Flash ($0.14/$0.28 за 284B) дороже, чем V3.2 ($0.26/$0.38 за 671B). Но относительно конкурентов (Minimax 2.7 в 3× дороже, Qwen ещё дороже) Flash выглядит очень выгодно. Ожидается, что масштабирование Ascend 950 supernodes позволит DeepSeek ещё снизить цены.