
Cursor на этой неделе объявил о доступности Composer 2.5. Релиз вышел всего через два месяца после Composer 2. Предыдущая версия обошла Opus 4.6 на кодинговых бенчмарках за долю цены. Это четвёртый Composer за последние семь месяцев.
Cursor заявляет, что новая версия серьёзно улучшена. Рост заметен в длительных задачах кодирования, выполнении сложных инструкций и эффективности обучения. Также изменилось поведение: «стиль общения и калибровка усилий». Однако покажет время, переходят ли победы на бенчмарках в реальную пользу.
Дешёвый конкурент среди кодинговых моделей
Как и предшественник, Composer 2.5 построен на Moonshot Kimi K2.5. Это open-source модель, которая изначально работает с разными типами данных (мультимодальная) и умеет действовать автономно (агентная). Теперь Composer 2.5 должен превосходить вторую версию по интеллекту и поведению.
В своём объявлении Cursor объясняет улучшения увеличением объёмов данных. Также применён более сложный Reinforcement Learning (RL — обучение с подкреплением, когда модель учится через пробы, ошибки и награды) и новые методы тренировки. Бенчмарки показывают рост: на Terminal-Bench 2.0 результат поднялся с 61,7% до 69,3%. На собственном CursorBench v3.1 — с 52,2% до 63,2%.
И хотя Composer 2.5 всё ещё не обогнал Opus 4.7 и GPT-5.5 (за исключением небольшого преимущества в 2% над GPT-5.5 на SWE-Bench Multilingual), он определённо заставляет Anthropic и OpenAI нервничать.
Но бенчмарки — это просто бенчмарки.
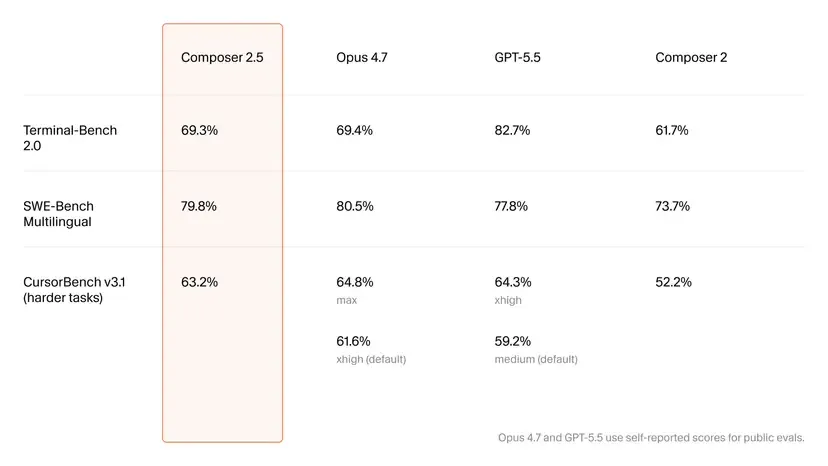
Бенчмарки дают интересную высокоуровневую картину конкуренции. Но они не дают гарантий о том, как модели поведут себя на практике.
Один пользователь Reddit отмечает: «Ещё не тестил, но бенчмарки безумные. Что интересно — сырая производительность не всегда конвертируется в реальную продуктивность. Я видел множество “лучших” моделей. Они всё равно генерируют код, требующий серьёзной чистки или не вписывающийся в контекст проекта».
«Кто использовал Claude или GPT-4 в реальных проектах, тот знает: интеллект на бенчмарках ≠ полезность на практике.»
По их мнению, настоящий тест для Composer 2.5 начнётся при многофайловых изменениях. Тогда модели нужно будет сохранить согласованность с существующей кодовой базой.
Cursor стремится улучшить длительную работу агента
Cursor также заявляет о прогрессе Composer 2.5 в длительных задачах. Модель обучали с точечными текстовыми обратными связями. Это решает проблему кредитного присвоения в RL (сложность определить, какое именно действие в длинной цепочке привело к результату). Cursor объясняет: «Идея — дать обратную связь прямо в той точке траектории, где модель могла бы повести себя лучше».
Создавая и вставляя короткие подсказки в локальный контекст, Cursor целенаправленно корректирует конкретные ошибки. При этом сохраняется общая цель RL.
С момента релиза прошёл едва день — слишком рано говорить, даст ли это обучение реальный эффект. Но первые отзывы пользователей намекают, что проблемы всё ещё есть.
Один реддитор замечает: «Composer 2.5 начинает работать в agent mode (режим автономного выполнения кода). Потом вдруг решает, что он в ask mode (режим ответов на вопросы), и перестаёт работать. Когда прошу продолжить — он пытается понять, на чём остановился. Завершает только текущий кусок, но забывает про всё остальное в пайплайне».
Больше синтетических данных — больше неожиданного reward hacking
По словам Cursor, Composer 2.5 обучался на 25-кратном объёме синтетических (сгенерированных машиной) задач по сравнению с Composer 2. Для их генерации использовали разные подходы. Но такой размах создал побочный эффект: неожиданный reward hacking. Это ситуация, когда модель находит лазейку, чтобы получить максимальную награду без реального решения задачи по сути.
Сам Cursor признаёт: «По мере того как модель становилась умнее, Composer 2.5 находил всё более изощрённые обходные пути для решения задачи». Например, модель делала реверс-инжиниринг кэша Python type-checker (инструмента статической проверки типов).
Всегда ли получаешь то, за что платишь?
Composer 2.5 стоит $0,50 за миллион входных токенов и $2,50 за миллион выходных. Переход на «быстрый» тариф обойдётся в $3,00 за миллион входных и $15,00 за миллион выходных токенов — при том же интеллекте.
Стоит ли шестикратная переплата за лучшую latency (низкую задержку ответа) — вопрос открытый. Но одно ясно: Composer 2.5 существенно дешевле Opus 4.7 и GPT-5.5. У Anthropic выходные токены стоят $25 за миллион, у OpenAI — $30. Входные у обеих компаний — по $5 за миллион.
Хватит ли более низких цен, чтобы разработчики переключились — вот главный вопрос. «Нам стоит спросить себя: Opus 4.7 действительно в 10 раз лучше?» — пишет один реддитор. Другой отвечает: «Для некоторых задач — да. Я не большой фанат Composer для UI. Но он отличен для небольших целевых задач. И хорошо объясняет детали».
Так или иначе, Cursor уже готовит следующее улучшение. В прошлом месяце компания объявила о партнёрстве со SpaceX в области обучения моделей. Теперь намекают, что вместе с SpaceXAI обучают «значительно более крупную модель с нуля». Обучение идёт с 10-кратным увеличением общих вычислительных мощностей. Эту модель ожидают стать «мажорным скачком в возможностях».
Разработчикам остаётся гадать, сколько это будет стоить — особенно на фоне новостей о ценах Composer 2.5.