
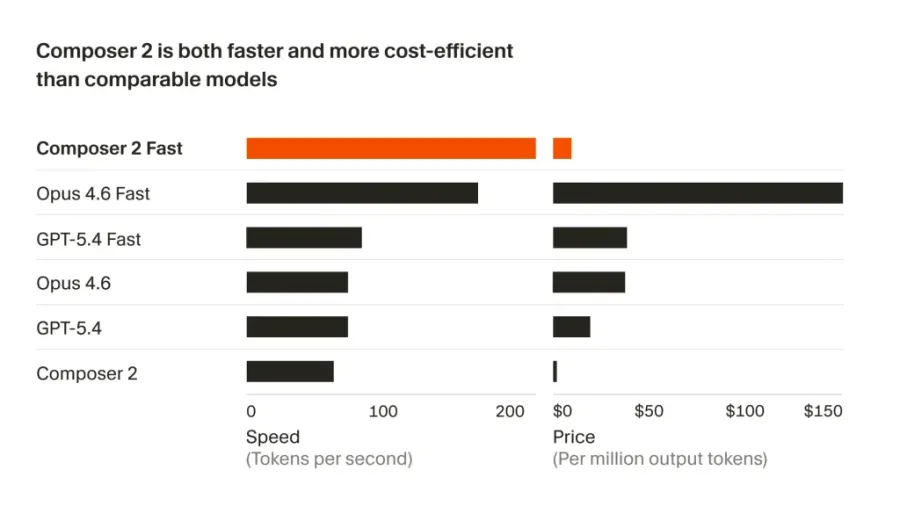
Cursor выпустил Composer 2 — третье поколение собственной модели для написания кода. На ключевых бенчмарках она обходит Claude Opus 4.6 от Anthropic, при этом цена в разы ниже.
Новая модель стоит от $0.5 за миллион входных токенов (единиц текста, обрабатываемых моделью) и $2.5 за миллион выходных. По умолчанию используется быстрый режим. Он стоит дороже — $1.5/$7.5 за миллион входных и выходных токенов соответственно. При этом уровень интеллекта модели не снижается, она работает быстрее.
Для сравнения: Opus 4.6 стоит $5/$25, а GPT-5.4 от OpenAI — $2.5/$15.
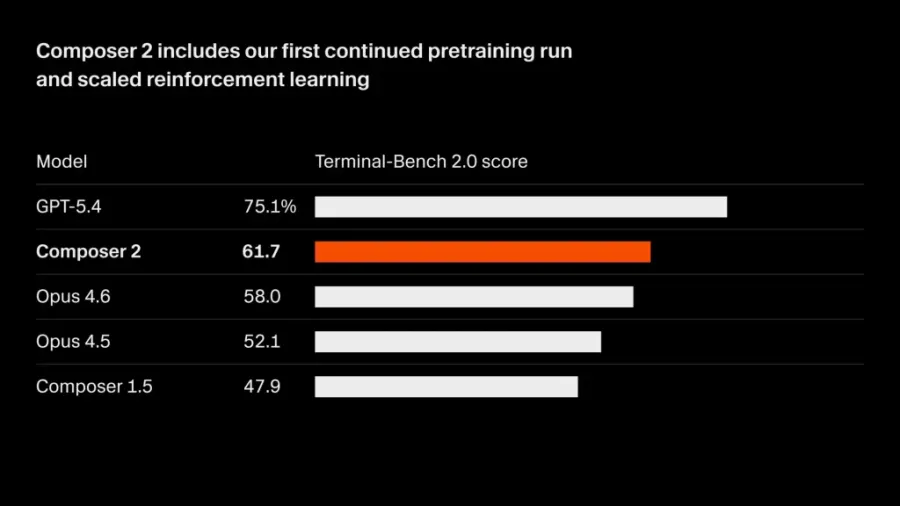
На Terminal-Bench 2.0 — бенчмарке, измеряющем, насколько хорошо AI-агенты справляются с реальными инженерными задачами в терминале, — модель набирает 61.7%. Claude Opus 4.6 показывает 58.0%. GPT-5.4 пока впереди с результатом 75.1%. Cursor сокращает отставание от конкурентов с каждой версией.
Cursor не привязан к одной LLM-модели, поэтому разработчик сам выбирает, что использовать. Есть также Auto mode. В этом режиме Cursor автоматически подбирает оптимальную модель, балансируя между интеллектом, скоростью и стоимостью.
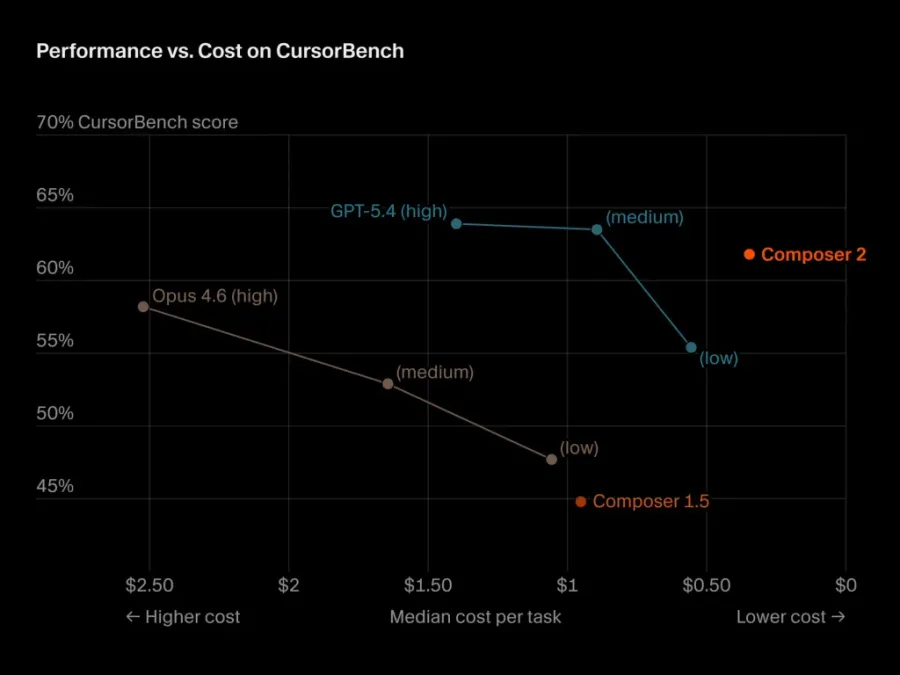
5 месяцев, 3 поколения
Composer 2 — уже третий релиз линейки с октября. Оригинальный Composer появился вместе с редизайном платформы 2.0 в октябре 2025 года. В феврале вышел Composer 1.5, и тогда он отставал от Opus 4.6 на Terminal-Bench 2.0 на 10%.
Предыдущие версии Composer применяли reinforcement learning (RL, обучение с подкреплением) к уже существующей базовой модели без изменения самой базы. Composer 2 — первый релиз, где Cursor провёл continuous pre-training (непрерывное дообучение на новых данных). Компания называет это «значительно более сильной основой для масштабирования RL».
Обучение модели сжимать собственную память
Главная техническая инновация новой модели — метод обучения, который Cursor называет «self-summarization» (самосжатие).
«Мы обучили Composer на длинных задачах через RL-процесс self-summarization. Сделав саммаризацию частью обучения, мы получили данные для обучения от последовательностей действий. Длина этих последовательностей значительно превышает максимальное контекстное окно модели», — пишут в компании.
Agentic coding (работа кода в режиме автономного агента) по своей природе генерирует длинные цепочки действий. Они быстро превышают контекстное окно — предел объема данных, который модель может удерживать в памяти за один раз. Традиционно эту проблему решают двумя способами. Либо создают текстовое резюме предыдущей работы модели. Либо используют скользящее контекстное окно, отбрасывая старые данные в пользу новых.
«У обоих подходов общий минус — модель может забыть критически важную информацию из контекста. Это снижает её эффективность на длинных задачах», — отмечает Cursor.
Подход Cursor называется compaction-in-the-loop reinforcement learning (сжатие внутри цикла обучения с подкреплением). Он встраивает саммаризацию напрямую в тренировочный цикл. Когда сгенерированный текст достигает порога по длине токенов, модель ставит себя на паузу. Она сжимает контекст примерно до 1 000 токенов — против 5 000 и более при традиционных методах.
RL-награда (сигнал поощрения в обучении с подкреплением) покрывает всю цепочку действий, включая шаги саммаризации. За счёт этого модель учится, какие детали сохранять, а какие отбрасывать.
По данным исследовательского поста Cursor, self-summarization снижает ошибки при сжатии контекста на 50%.