
Я немного опоздал с обзором этой модели, но успел подумать о том, какие оси реально важны для агентов. Традиционные бенчмарки сводят производительность модели к одной цифре — корректности. Так было всегда: это просто, быстро и удобно для оценки. Это же совет я даю тем, кто создаёт свои бенчмарки — нужен один интерпретируемый номер. Через год-два это, вероятно, всё ещё будет правдой, и бенчмарки для агентов станут лучше. Но пока они не отражают того, что мы чувствуем на практике. Агентные задачи — это всегда смесь корректности, удобства, скорости и стоимости. В итоге бенчмарки начнут оценивать каждое измерение отдельно.
На бумаге GPT 5.4 выглядит как очередное инкрементальное обновление. На практике — это заметный шаг вперёд по всем четырём параметрам. GPT 5.4 в Codex, постоянно в fast mode (режим ускоренной генерации) с высоким или максимальным уровнем reasoning effort (вычислительных усилий на рассуждение) — первый агент OpenAI, который реально справляется с большинством случайных задач, которые на него бросаешь.
Последние несколько месяцев я не погружался глубоко в разработку ПО. Большинство задач для агентов — небольшие проекты (не разовые, но такие, где я строю всё сам и управляю архитектурой неделями), анализ данных и исследовательские задачи. Когда работаешь в agent-native стиле (агент — основной инструмент работы, а не помощник), это означает кучу рутинных API, фоновых пакетов (установка и управление бинарниками LaTeX, ffmpeg, инструменты конвертации мультимедиа и т. д.), git-операции, файловый менеджement, поиск. До GPT 5.4 я регулярно спотыкался об агентов OpenAI — смерть от тысячи порезов. Это ощущалось как rage quit: втягиваешься в работу с GPT 5.2 Codex, а он падает на git-операции, и приходится перезапускать (или просить Claude помочь). Эти острые углы исчезли.
Другой, менее очевидный сдвиг в удобстве GPT 5.4 — главная причина, по которой OpenAI вернулась в гонку агентов — модель просто ощущается «правильной». Я отделяю это от рутинных задач, о которых писал выше. Здесь дело в том, как продукт — то есть модельная обвязка (программная оболочка вокруг модели: интерфейс, логика запросов, отображение результатов) — подаёт выходы модели, запросы и всё остальное пользователю. Насколько легко в это погрузиться. Это всегда была главная сильная сторона Claude и ключ к его астрономическому росту. Claude не просто полезен — в нём есть шарм и развлекательная ценность, заставляющая новичков остаться. У GPT 5.4 это тоже появилось, но фундаментальные сильные стороны Claude всё равно делают его более «тёплым».
Claude — сверхумная модель с характером, с умением сформулировать мысль в споре, иногда что-то забывающая. Модели OpenAI в Codex ощущаются скрупулёзными, чуть холодными, но глубоко механическими. Я бы использовал Claude для задач, где нужно мнение, а GPT 5.4 — чтобы прогнать через него безумно конкретный TODO-лист. Instruction following (точность выполнения инструкций) у GPT 5.4 настолько точный, что после долгой работы с Claude мне приходится переучиваться взаимодействию с моделью. Claude в некоторых доменах отлично понимает твоё намерение. GPT 5.4 просто делает то, что ты сказал. Это две очень разные философии «какой должна быть лучшая модель для агента». Claude скорее привлечёт новичков, а GPT 5.4 — опытного координатора агентов, который хочет натравить свою AI-армию на распределённые задачи.
Если отбросить шарм и вкус, по многим параметрам удобства OpenAI сейчас впереди. Приложение Codex привлекательное — я пользуюсь им не всегда, но иногда он меня реально цепляет. Подозреваю, что в том, как выглядят такие приложения, нас ждёт серьёзная инновация. Лично я ожидаю, что в итоге они станут похожи на Slack — когда несколько агентов общаются друг с другом под моим присмотром.
OpenAI также нативно предоставляет fast mode для моделей по подписке с очень щедрыми лимитами. Я давно на тарифе Claude за $100/месяц и ChatGPT за $200/месяц. С Codex в fast mode и xhigh reasoning effort я ни разу не приблизился к лимитам, тогда как лимиты Claude иногда пробиваю. В этом наверняка есть модельная причина. В большинстве релизных постов OpenAI показывает, что каждая итерация модели использует меньше токенов для достижения пиковых результатов на бенчмарках. Это мера эффективности reasoning. Именно к такой многомерной картине бенчмарков мир и движется.
Вот график от Cursor, к сожалению, без всех уровней reasoning effort для GPT 5.4, но он подтверждает этот тезис в сторонней оценке. Чего не хватает всем семействам моделей — так это скорости и цены (как показателя общего объёма вычислений) для достижения результата.
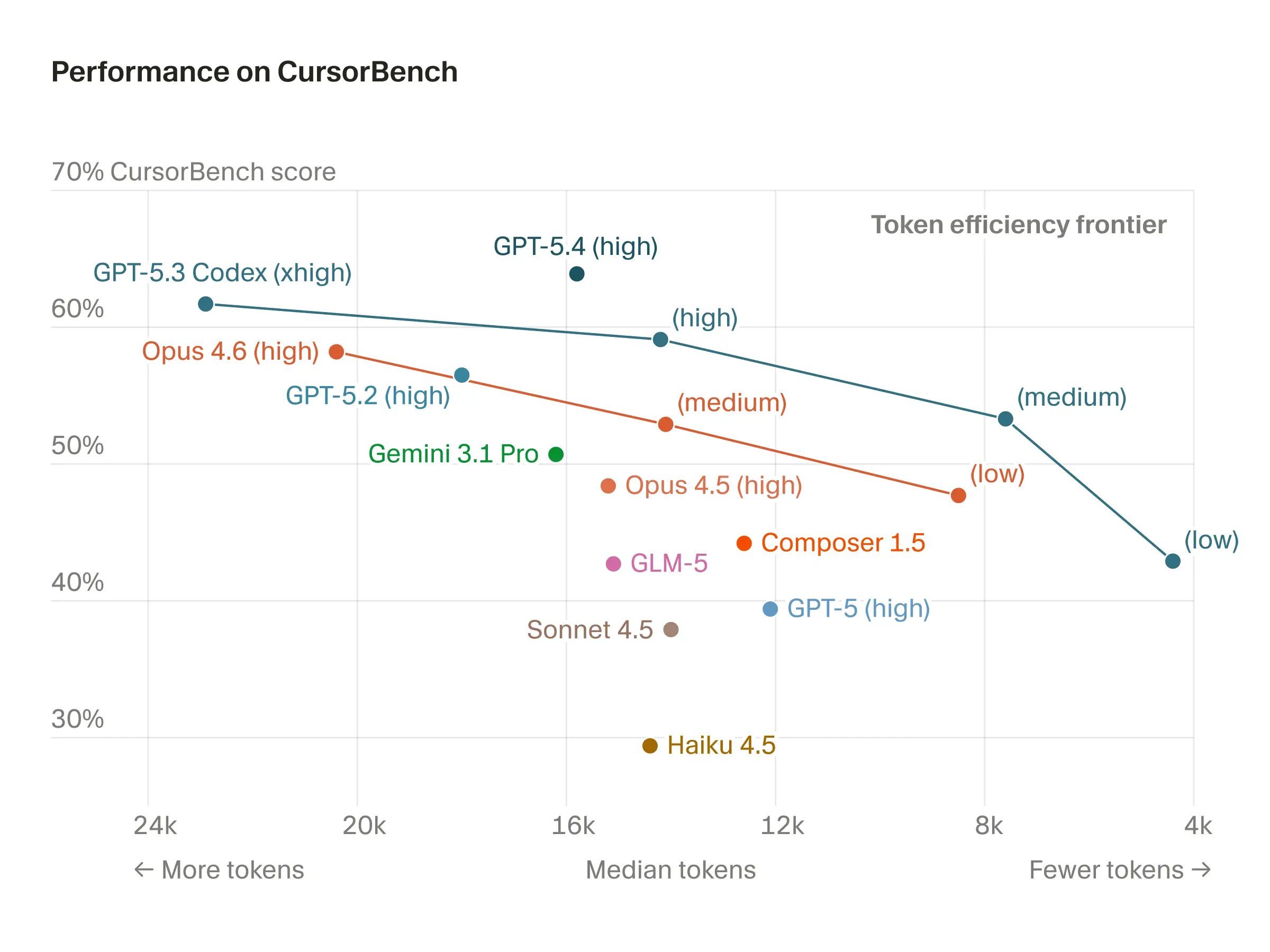
Последнее преимущество GPT 5.4 — и агентных моделей OpenAI вообще — значительно лучшее управление контекстом. При регулярном использовании я чувствую, что ни разу не упёрся в стену контекста и не испытал контекстной тревоги. Та самая эффективность reasoning, о которой я подозреваю выше, позволяет модели извлечь гораздо больше из изначально пустого контекстного окна. А когда GPT 5.4 делает compact (встроенное сжатие контекста), это почти незаметно.
Единственная проблема, с которой я сталкиваюсь и у Claude Opus 4.6, и у GPT 5.4 — лёгкая забывчивость. Если дать модели несколько задач в одном сообщении вне режима планирования, она часто часть из них теряет. Иногда кажется, что модель глючит и пытается решить предыдущую задачу вместо текущей. Не уверен, что именно — модель или обвязка — является точной причиной. Но иногда мне нравится ставить в очередь несколько сообщений, пока модель работает, чтобы уточнить задачу. Сейчас это обычно приводит к рискованным результатам, за исключением простейших случаев.
В последнее время я активно использую и GPT, и Claude — чаще по настроению — и делаю больше, чем когда-либо. Прямая интеграция GPT 5.4 Pro с Codex, скажем как \ultrathink, стала бы серьёзным конкурентным преимуществом для OpenAI. Эти модели невероятны.
В целом GPT 5.4 — это агентная модель, которая привносит куда больше простоты, удобства и «агентности» в уже очень сильную программную базу GPT 5.3 Codex. Это большой шаг, и я невероятно взволнован тем, какая из двух компаний выпустит обновление следующей. На бумаге — лучший код на пике, выше скорость, лучше управление контекстом, щедрее лимиты — всё это показывает, насколько нюансированным стал выбор модели. Но я по-прежнему чуть больше наслаждаюсь Claude в вещах, которые никогда не проявятся на бенчмарках. Именно поэтому утром я ввожу в терминал claude, а не codex.