
Следующее поколение роботов — от гуманоидов до беспилотных автомобилей — зависит от обучающих данных с высокой степенью достоверности и пониманием физики. Без репрезентативных и разнообразных датасетов системы не получают должной подготовки. Они плохо обобщают, не справляются с вариациями реального мира и ведут себя непредсказуемо в пограничных случаях. Сбор масштабных реальных данных дорог, требует много времени и часто упирается в физические ограничения.
Ознакомьтесь с NVIDIA Cosmos Cookbook — там есть пошаговые воркфлоу, технические рецепты и примеры для сборки, адаптации и деплоя Cosmos WFM.
NVIDIA Cosmos решает эту проблему, ускоряя разработку world foundation model (WFM — базовые модели, которые понимают и предсказывают физические законы окружающего мира). В основе платформы — Cosmos WFM. Они ускоряют synthetic data generation (создание искусственных обучающих данных) и служат фундаментом для пост-тренинга предметных и задачно-ориентированных моделей physical AI (ИИ, взаимодействующего с физическим миром). Разбираемся в свежих обновлениях Cosmos WFM, их ключевых возможностях и том, как с ними работать.
Обновления Cosmos World Foundation Models
Cosmos WFM развиваются быстро. Спустя год после запуска ключевые обновления включают:
- Cosmos Transfer 2.5 — более быстрая и масштабируемая аугментация (расширение разнообразия) данных из симуляций и 3D-пространственных входов. Обеспечивает большее разнообразие окружений, освещения и сцен.
- Cosmos Predict 2.5 — улучшенная генерация long-tail-сценариев (редких и нетипичных ситуаций) для последовательностей до 30 секунд. При пост-тренинге на проприетарных или предметных данных точность вырастает до 10×. Поддерживает multiview-выходы (изображения с нескольких камер), произвольные раскладки камер и альтернативные policy-выходы (предсказания действий агента) вроде симуляции действий.
- Cosmos Reason 2 — продвинутое физическое мышление ИИ с улучшенным пространственно-временным пониманием и точностью по таймстемпам. Добавлено детектирование объектов с 2D/3D-локализацией по точкам и координатам bounding boxes (прямоугольных рамок вокруг объектов). Добавлены объяснения и метки рассуждений. Поддержка длинного контекста расширена до 256K входных токенов.
Cosmos Transfer: физически корректные фотореалистичные видео
Cosmos Transfer генерирует высокодетализированные мировые сцены из структурированных входов. Модель обеспечивает точное пространственное выравнивание и компоновку сцены.
На архитектуре ControlNet (модуля управления генерацией по заданным условиям) модель сохраняет знания претрейна и выдаёт структурированные, консистентные результаты. Spatiotemporal control-карты динамически выравнивают синтетические и реальные представления. Это даёт точный контроль над композицией сцены, расположением объектов и динамикой движения.
Входы:
- Структурированные визуальные или геометрические данные: карты сегментации, карты глубины, карты границ, ключевые точки движения человека, LiDAR-сканы, траектории, HD-карты и 3D-bounding boxes (прямоугольные рамки вокруг объектов в 3D-пространстве).
- Ground truth-аннотации (эталонные разметки): высокоточные референсы для точного выравнивания.
Выход: Фотореалистичные видеопоследовательности с контролируемой раскладкой, расположением объектов и движением.


Рис. 1. Слева — виртуальная симуляция (ground truth), созданная в NVIDIA Omniverse. Справа — фотореалистичная трансформация через Cosmos Transfer
Ключевые возможности:
- Масштабируемая генерация фотореалистичных синтетических данных, согласующихся с реальной физикой.
- Контроль взаимодействий объектов и компоновки сцены через структурированные мультимодальные входы.
Cosmos Transfer для контролируемых синтетических данных
С помощью генеративных AI API и SDK NVIDIA Omniverse ускоряет физическую симуляцию ИИ. Разработчики используют Omniverse, построенный на OpenUSD (открытом формате описания 3D-сцен), для создания 3D-сцен, точно имитирующих реальный мир для обучения и тестирования роботов и беспилотников. Эти симуляции служат ground truth-видео для Cosmos Transfer в связке с аннотациями и текстовыми инструкциями. Модель повышает фотореализм, варьируя окружение, освещение и визуальные условия. В результате генерируются масштабируемые и разнообразные состояния мира.
Такой воркфлоу ускоряет создание качественных обучающих датасетов. Он также обеспечивает эффективный перенос ИИ-агентов из симуляции в реальный мир (sim-to-real перенос).
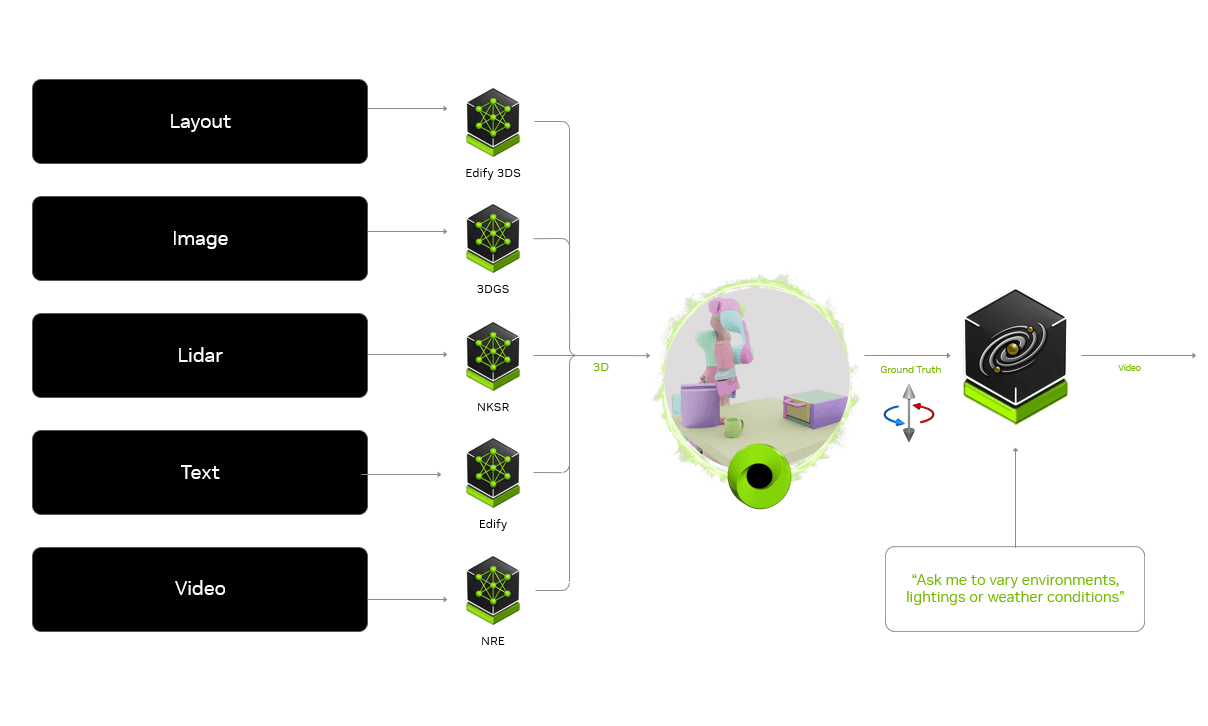
Рис. 2. Генеративные API и SDK в NVIDIA Omniverse обеспечивают ground truth-симуляцию для Cosmos Transfer

Рис. 3. Фотореалистичное видео, сгенерированное Cosmos Transfer
Cosmos Transfer ускоряет робототехническую разработку. Модель обеспечивает реалистичное освещение, цвета и текстуры в Isaac GR00T Blueprint для генерации манипуляционных движений и Omniverse Blueprint для симуляции беспилотных автомобилей при варьировании погодных и экологических условий. Такие данные критичны для пост-тренинга policy-моделей (моделей, определяющих действия агента). Они обеспечивают плавный sim-to-real перенос и поддерживают обучение perception-ИИ (моделей визуального восприятия) и специализированных роботизированных моделей вроде GR00T N1.
Как запустить Cosmos Transfer 2.5
- Для инференса — руководство по инференсу.
- Для пост-тренинга на проприетарных или предметных данных — руководство по пост-тренингу.
- Пошаговые воркфлоу и технические рецепты — в NVIDIA Cosmos Cookbook.
Cosmos Predict: генерация будущих состояний мира
Cosmos Predict WFM моделирует будущие состояния мира в формате видео по мультимодальным входам: тексту, видео и парам «начальный — конечный кадр». Модель построена на transformer-архитектуре, которая улучшает временную консистентность и интерполяцию кадров.
Ключевые возможности:
- Генерация реалистичных состояний мира напрямую из текстовых промптов.
- Предсказание следующих состояний по видеопоследовательностям — заполнение пропущенных кадров или продолжение движения.
- Мультикадровая генерация между начальным и конечным изображением — создание полной, плавной последовательности.
Cosmos Predict WFM даёт прочный фундамент для обучения downstream-моделей (моделей, построенных поверх базовой) в робототехнике и беспилотных автомобилях. Модель можно пост-тренировать на генерацию действий вместо видео для policy modeling (моделирования действий агента). Либо адаптировать для визуально-языкового понимания и создания кастомных perception-моделей.
Как запустить Cosmos Predict 2.5
- Для инференса — руководство по инференсу.
- Для пост-тренинга на проприетарных или предметных данных — руководство по пост-тренингу.
- Пошаговые воркфлоу и технические рецепты — в NVIDIA Cosmos Cookbook.
Cosmos Reason: восприятие, рассуждение и интеллектуальный ответ
Cosmos Reason — полностью кастомизируемая мультимодальная модель рассуждений. Она создана для понимания движения, взаимодействий объектов и пространственно-временных связей. Модель использует chain-of-thought (CoT — пошаговые рассуждения). Она интерпретирует визуальный вход, предсказывает исходы на основе промпта и поощряет оптимальное решение. В отличие от текстовых LLM, она базирует рассуждения на реальной физике. Модель генерирует понятные, контекстно-зависимые ответы на естественном языке.
Вход: Видеонаблюдения и текстовый запрос или инструкция. Выход: Текстовый ответ, сгенерированный через долгогоризонтные CoT-рассуждения.
Ключевые возможности:
- Понимает, как объекты двигаются, взаимодействуют и меняются во времени.
- Предсказывает и поощряет следующее лучшее действие на основе входного наблюдения.
- Непрерывно уточняет принятие решений.
- Заточена под пост-тренинг для построения perception AI и embodied AI-моделей (ИИ, встроенного в физическое тело).
Пайплайн обучения
Cosmos Reason обучается в три этапа. Каждый из них усиливает способность рассуждать, предсказывать и реагировать в реальных сценариях.
-
Претрейн: Vision Transformer (ViT — архитектура для обработки изображений) обрабатывает видеокадры в структурированные эмбеддинги (векторные представления). Затем они выравниваются с текстом для общего понимания объектов, действий и пространственных связей.
-
Supervised fine-tuning (SFT — дообучение с учителем): Специализирует модель на физическом рассуждении на двух уровнях. Общий файн-тюнинг улучшает языковое заземление (связь текста с визуальными объектами) и мультимодальное восприятие на разнообразных видео-текстовых датасетах. Дообучение на данных physical AI заостряет навык рассуждений о реальных взаимодействиях. Модель учится поведению объектов — как их использовать, как разворачиваются многошаговые задачи. Также изучается spatial feasibility (пространственная осуществимость) — умение отличать реалистичное размещение от невозможного.
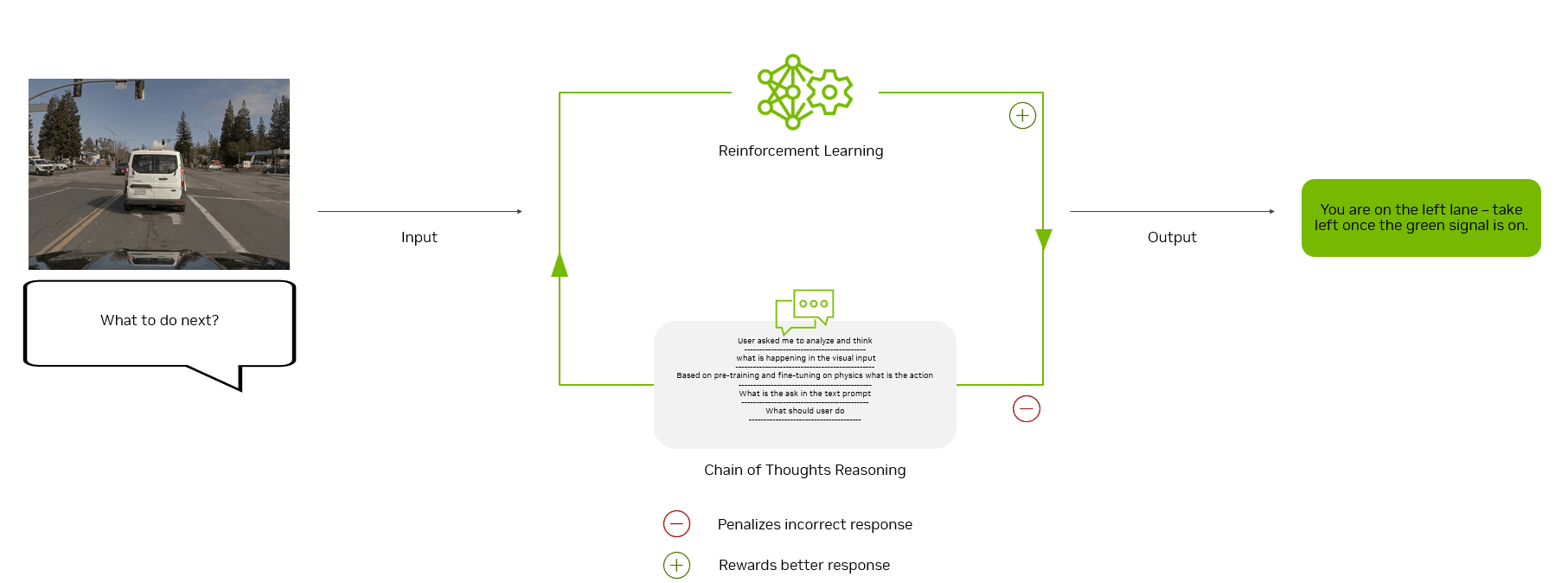
Рис. 4. Цикл reinforcement learning непрерывно улучшает модель через позитивную и негативную обратную связь
Reinforcement learning (RL): Модель оценивает различные пути рассуждений и обновляется только при появлении лучшего решения через пробы и reward-обратную связь. Вместо размеченных человеком данных используются rule-based-награды (награды на основе заданных правил):
- Распознавание сущностей: поощряется точная идентификация объектов и их свойств.
- Пространственные ограничения: штрафуются физически невозможные размещения, подкрепляются реалистичные позиции объектов.
- Временные рассуждения: поощряется корректное предсказание последовательностей на основе причинно-следственных связей.
Как запустить Cosmos Reason 2
- Для инференса — руководство по инференсу.
- Для пост-тренинга на проприетарных или предметных данных — руководство по пост-тренингу.
- Пошаговые воркфлоу и технические рецепты — в NVIDIA Cosmos Cookbook.
Начните работу
- Cosmos Cookbook — пошаговые воркфлоу, технические рецепты и примеры для сборки, адаптации и деплоя Cosmos WFM.
- Новые открытые модели и датасеты Cosmos — на Hugging Face и GitHub, либо попробуйте модели на build.nvidia.com.
- Присоединяйтесь к сообществу в Cosmos Discord-канале.
- Уже используете Cosmos? Узнайте, как внести свой вклад.
- Посмотрите ключевой доклад GTC от основателя и CEO NVIDIA Дженсена Хуанга и изучите сессии, посвящённые Cosmos.