
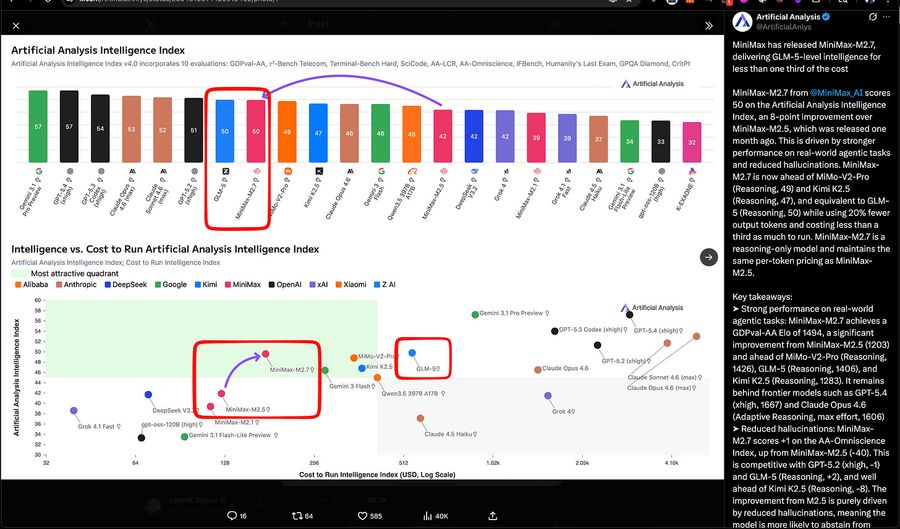
Прошло меньше двух месяцев с IPO MiniMax и публикации первых финансовых результатов. Компания снова в заголовках — на этот раз с MiniMax 2.7. Яркая новость на фоне перетасовки в линейке Qwen. По качеству модель догоняет GLM-5 от Z.ai — прошломесячного SOTA (лучшего результата) среди открытых весов (публично доступных параметров модели). Но главная история здесь об эффективности (зелёный квадрант на графике Artificial Analysis):
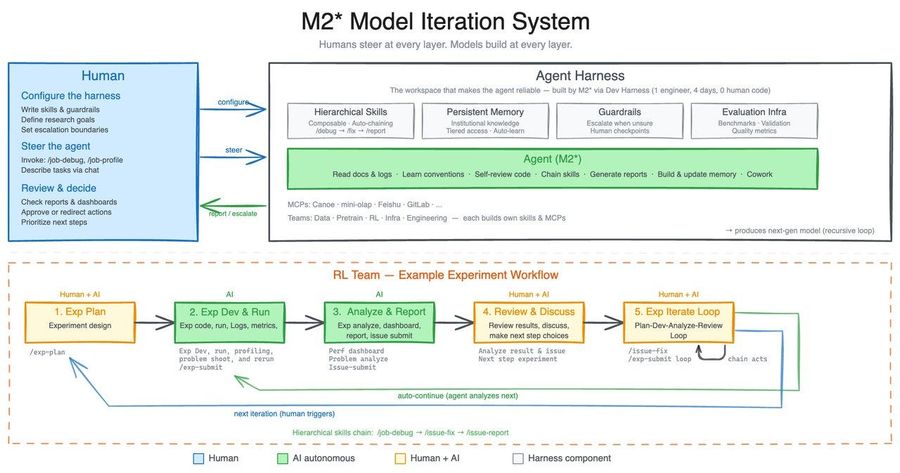
Команда называет это «ранними признаками самоэволюции» — «наша первая модель, глубоко участвующая в собственной эволюции». Это отсылает к Autoresearch Карпати. Сами разработчики ограничиваются заявлением, что «M2.7 способна обработать 30–50% рабочего процесса»:
Кроме того, MiniMax сообщает о работе над мультиагентным сотрудничеством («Agent Teams»). Компания следует за Anthropic и OpenAI в применении моделей к финансовым задачам. А также запускает OpenRoom — open-source демо для развлекательных сценариев.
MiniMax M2.7, Xiaomi MiMo-V2-Pro и растущий класс «самоэволюционирующих» моделей
-
MiniMax M2.7 — главная релизная новость. Компания позиционирует M2.7 как первую модель, «глубоко участвовавшую в собственной эволюции». Заявленные метрики: 56,22% на SWE-Pro, 57,0% на Terminal Bench 2, 97% следования навыкам по 40+ навыкам, паритет с Sonnet 4.6 на OpenClaw. Последующий тред уточняет, что внутренний harness (окружение исполнения: набор скриптов, eval-наборов и петель обратной связи вокруг модели) рекурсивно улучшал себя. Он собирал фидбек, строил eval-наборы, итерировал по навыкам/MCP, памяти и архитектуре (тред). MCP здесь — Model Context Protocol, стандарт подключения внешних инструментов к LLM. Третьи стороны подхватили нарратив о «самоэволюции», включая TestingCatalog и kimmonismus.
-
Artificial Analysis ставит M2.7 на границу «цена/качество». По данным Artificial Analysis, модель набирает 50 в Intelligence Index — на уровне GLM-5 (Reasoning). Цена — $0,30/$1,20 за 1M входных/выходных токенов. Полный прогон индекса стоит $176 — меньше трети от стоимости GLM-5. Также фиксируется GDPval-AA Elo 1494, что выше MiMo-V2-Pro (1426), GLM-5 (1406) и Kimi K2.5 (1283). Отмечается значительное снижение галлюцинаций по сравнению с M2.5. Модель быстро появилась в Ollama cloud, Trae, Yupp, OpenRouter, Vercel, Zo, opencode и kilocode.
-
Xiaomi MiMo-V2-Pro — серьёзная китайская reasoning-модель только по API. Artificial Analysis даёт ей 49 в Intelligence Index, контекст 1M токенов, цену $1/$3 за 1M токенов, GDPval-AA Elo 1426. Отмечается лучшая токен-эффективность по сравнению с конкурентами. Также зафиксирован относительно высокий AA-Omniscience (+5) за счёт низких галлюцинаций. Это следует за открытой MiMo-V2-Flash (309B параметров всего / 15B активных, лицензия MIT) — архитектурой MoE, где на каждый токен активна лишь часть параметров. V2-Pro пока доступна только по API.
-
Mamba-3 вышла и сразу обсуждается через призму гибридных архитектур. Cartesia представила Mamba-3 как SSM (State Space Model — архитектуру нейросети, альтернативную трансформерам). Модель оптимизирована для inference-нагруженных сценариев. Тестирование доступно от самой Cartesia (ссылка от Albert Gu). Ранние технические реакции сфокусировались не на standalone SSM, а на встраивании Mamba-3 в трансформерные гибриды. rasbt прямо предложил заменять Gated DeltaNet в гибридах следующего поколения вроде Qwen3.5 / Kimi Linear. JG_Barthelemy отметил гибридную интеграцию и «разблокировку Muon для SSM» (Muon — оптимизатор для обучения нейросетей).
Harness-инжиниринг, навыки, MCP и переход от «промптинга» к системному дизайну
-
Самый устойчивый тренд — harness engineering как реальный дифференциатор. Несколько постов утверждают, что узкое место больше не в базовой модели, а в среде исполнения вокруг неё. Интервью The Turing Post с Michael Bolin описывает кодирующих агентов как задачу инструментов, читаемости репозитория, ограничений и петель обратной связи — то, что многие теперь называют harness engineering. dbreunig делает похожий вывод о причинах, по которым команды остаются с DSPy. nickbaummann_ аргументирует, что GPT-5.4 mini важна именно потому, что дешёвые быстрые субагенты меняют то, что имеет смысл делегировать.
-
Навыки (Skills) закрепляются как общая абстракция в агентских стеках. Практический тред от mstockton описывает реальные паттерны использования SKILLS: прогрессивное раскрытие, инспекция трейсов (логов выполнения агента), дистилляция сессий, навыки с триггерами из CI и самоулучшающиеся навыки. RhysSullivan предлагает распространять навыки через MCP-ресурсы для решения проблем устаревания и версионирования. Аккаунт Claude Code от Anthropic уточняет, что навык — не просто текстовый сниппет, а папка со скриптами, ассетами и данными. Ключевое поле описания должно указывать, когда его активировать (твит).
-
Открытые агентские стеки сходятся к формуле: модель + runtime + harness. Harrison Chase опубликовал разбор, где Claude Code, OpenClaw, Manus и прочие представляют одну и ту же декомпозицию: открытая модель + runtime + harness. Примеры — Nemotron 3, OpenShell от NVIDIA и DeepAgents. Связанные релизы инфраструктуры: LangSmith Sandboxes для безопасного исполнения кода, LangSmith Polly GA как внутрипродуктовый ассистент отладки и улучшения, а также новый гайд LangChain по production observability для агентов.
-
MCP набирает обороты, но появляется отторжение. Полезные релизы: open-source MCP-сервер от Google Colab, позволяющий локальным агентам управлять GPU-рантаймами Colab. Также — обновление Gemini API с поддержкой встроенных инструментов и кастомных функций в одном вызове. Параллельно виден скепсис. skirano прямо заявил: «MCP была ошибкой. Да здравствуют CLI». denisyarats иронизировал о «model cli protocol».
-
Параллельный тренд: агенто-нативные enterprise-приложения и «headless SaaS». ivanburazin описывает формирующуюся категорию headless SaaS (SaaS-продуктов без веб-интерфейса, доступных только через API). Это традиционный софт, перестроенный как агент-first API без человеческого UI. Тренд согласуется с релизами вроде AI-аналитика от Rippling и вебинаром Anthropic о Claude для Excel/PowerPoint. Также — с тезисом о том, что приложения для заметок с встреч становятся полноценными AI context/data-приложениями (zachtratar).
Инфраструктура, ядра и ко-дизайн «модель — система»
-
Attention Residual стал кейсом ко-дизайна инфраструктуры и модели. Несколько постов разобрали работу AttnRes от Kimi/Moonshot не просто как экзотическую архитектуру. Речь идёт о модификации механизма внимания, где остаточные связи вынесены за пределы стандартного слоя. bigeagle_xd акцентировал ко-дизайн исследований модели и инфраструктуры. ZhihuFrontier объяснил, почему полный attention residual нагружает pipeline parallelism (способ распределения вычислений модели между GPU). Причина — асимметричные паттерны коммуникации и памяти. Block Attention Residual плюс cross-stage caching восстанавливают симметрию. YyWangCS17122 усилил тезис: оптимизация GPU-ядер (программ для GPU), алгоритмически-системный ко-дизайн и числовая строгость — путь к production-ready большим моделям.
-
Упаковка кастомных ядер упрощается. ariG23498 отметил новую библиотеку
kernelsот Hugging Face. Она призвана сделать кастомные GPU-ядра более распространяемыми и простыми в интеграции через Hub. Цель — снизить боль от написания и дистрибуции fused-ядер (нескольких операций, объединённых в одну для ускорения) без необходимости каждой команде вручную реализовывать логику установки. -
Оптимизация inference остаётся темой первого порядка. Тот же тред о ядрах повторяет знакомый стек оптимизаций. Нужно закрывать idle-провалы между запусками ядер, фьюзить (объединять) операции через
torch.compileи падать на кастомные ядра только там, где это необходимо. На аппаратной стороне Stas Bekman заметил, что заявленная пропускная способность NVLink может вводить в заблуждение. Она не дуплексная в том смысле, в каком многие предполагают — не работает одновременно в обоих направлениях с полной скоростью. -
Вычислительные узкие места остаются upstream всего остального. kimmonismus утверждает, что EUV-станки ASML (оборудование для экстремальной ультрафиолетовой литографии — ключевой технологии производства чипов) и их узкие цепочки поставок могут ограничить производство примерно 100 станками в год к 2030 году. Это делает литографию важным потолком для AI-масштабирования в текущем десятилетии.
Документы, OCR, поиск и context engineering для реальных рабочих процессов
-
Document AI движется к end-to-end мультимодальным парсерам с grounding. Baidu представила Qianfan-OCR — 4B end-to-end модель для документного интеллекта. Она схлопывает извлечение таблиц, распознавание формул, понимание графиков и KIE (Key Information Extraction — извлечение структурированной информации) в один проход. Vik Paruchuri выпустил open-source Chandra OCR 2 с заявленными 85,9% на olmOCR bench, поддержкой 90+ языков и улучшенной работой с layout, рукописным текстом, математикой, формами и таблицами при размере 4B. На стороне платформ LlamaIndex и jerryjliu0 подчёркивают, что production документные агенты нуждаются не только в конвертации в Markdown. Им необходимы определение layout, сегментация, метаданные-контекст и визуальный grounding (привязка извлечённых данных к позициям в исходном документе) для поддержки человекочитаемых документных процессов.
-
Late-interaction retrieval продолжает давить на баланс память/качество. Late-interaction retrieval — метод поиска, при котором сравнение запроса и документа происходит на уровне отдельных токенов, а не целых векторов. victorialslocum резюмирует MUVERA — подход, сжимающий multi-vector retrieval в фиксированно-мерные кодировки. Результат — примерно 70% сокращения памяти и значительно меньшие HNSW-графы (иерархические структуры для поиска ближайших соседей). Цена — некоторое падение recall и throughput запросов. lateinteraction использовал тред, чтобы напомнить об ограничениях single-vector retrieval на сложных OOD-данных (данных, отличающихся от обучающей выборки).
-
Context engineering становится продуктовой категорией. llama_index прямо называет context engineering преемником prompt engineering. Структурированный парсинг и экстракция — ключевой рычаг. Это дополняется поддержкой Hugging Face для отдачи Markdown-представлений статей агентам и навыком Paper Pages для более токен-эффективного поиска и чтения статей (Niels Rogge, mishig25).
Evals, методология обучения и бенчмарки, за которыми стоит следить
-
Воспроизводимость LLM-as-judge снова под огнём. LLM-as-judge — подход, при котором одна LLM оценивает ответы другой. a1zhang показал, что модель набирает 10% при оценке через GPT-5.2-as-judge против 43,5% через GPT-5.1-as-judge. При этом в статье заявлено 34%. Наглядное напоминание, что выбор судьи может перевесить выводы. torchcompiled сформулировал вывод: не используйте LLM-as-judge без валидации корреляции с человеком или настройки под неё.
-
Состав данных для предобучения снова становится ключевым рычагом. rosinality обратил внимание на работу, показывающую, что микс SFT-данных во время предобучения может превзойти стандартный пайплайн «предобучение → файнтюн». Работа демонстрирует scaling law для соотношения при фиксированном бюджете токенов. Родственные посты от arimorcos, pratyushmaini и Christina Baek утверждают, что domain adaptation чаще выигрывает от более раннего смешивания данных. Также — от повторения маленьких качественных датасетов 10–50x во время предобучения, а не от наивного файнтюна.
-
Бенчмарки сдвигаются к «нерешённому и полезному». Ofir Press указывает на будущее, где улучшение на бенчмарке означает решение ранее нерешённых задач, имеющих значение в реальном мире. А не заучивание экзаменообразных датасетов. Он также отмечает, что AssistantBench остаётся нерешённым 1,5 года. Новые бенчмарки и инструменты: ScreenSpot-Pro на Hugging Face для GUI-агентов и академические партнёрства Arena, финансирующие eval-исследования.
Топ-твиты (по вовлечённости, отфильтрованные по технической релевантности)
-
Parameter Golf от OpenAI: OpenAI запустила Parameter Golf — тренировочный челлендж. Задача — уместить лучшую LM в артефакт 16MB, обучив за менее 10 минут на 8×H100. В призовом фонде $1M вычислительных ресурсов. Хорошая энергия для привлечения талантов и красивое дополнение к культуре NanoGPT speedrun (детали от scaling01).
-
Исследование Anthropic на 81k пользователей: Anthropic сообщает, что с помощью Claude за одну неделю опросила 80 508 человек о надеждах и страхах вокруг AI. Компания называет это крупнейшим качественным исследованием такого рода. Интересно и как социальное измерение, и как сигнал, что опосредованное моделью интервьюирование может стать постоянным продуктом и исследовательским инструментом.
-
Превью real-time генерации видео от Runway: Runway показала исследовательское превью, разработанное с NVIDIA. Это HD-генерация видео с time-to-first-frame менее 100 мс на аппаратуре Vera Rubin (твит). Если это масштабируется, речь о качественно другом интерактивном цикле для видео-моделей.
-
Hugging Face об интерфейсах исследования для агентов: Платформенное изменение для отдачи Markdown-представлений статей агентам и сопутствующий навык для работы с papers. Небольшая, но важная инфраструктурная деталь для агентных research-воркфлоу.
-
Интегрированная отладка браузера в VS Code: Последний релиз VS Code от Microsoft добавляет интегрированную браузерную отладку для end-to-end веб-воркфлоу. Полезно само по себе и, вероятно, станет ещё важнее, когда кодирующие агенты начнут работать с live-состоянием браузера.
Что говорят в сообществах
-
Анонс MiniMax-M2.7 (Активность: 947): На изображении — сравнительный анализ M2.7 с Gemini 3.1 Pro, Sonnet 4.6, Opus 4.6 и GPT 5.4 по SWE Bench Pro, VIBE-Pro и MM-ClawBench. Подчёркиваются возможности автономной итерации модели: автономный анализ путей отказа, планирование изменений, модификация кода и оценка результатов с улучшением на 30% на внутренних eval-наборах. Комментаторы выражают скепсис относительно практической применимости моделей, хорошо показывающих себя на бенчмарках, но плохо генерализирующих на реальные задачи.
- Recoil42 обращает внимание на автономные итерационные возможности M2.7. Модель оптимизирует sampling-параметры и workflow-гайдлайны через циклы «анализ → изменение → оценка».
- Specialist_Sun_7819 поднимает критический вопрос о разрыве между бенчмарками и реальностью. Нужны пользовательские тесты для оценки того, как модели справляются с задачами вне обучающего распределения.
- Lowkey_LokiSN выражает обеспокоенность устойчивостью к квантизации, ссылаясь на проблемы с UD-Q4_K_XL вариантом предыдущей M2.5.
-
MiniMax M2.7 на подходе (Активность: 329): Твит MiniMax об участии в NVIDIA GTC с обсуждением M2.7, мультимодальных систем и AI-продуктов. Комментаторы отмечают эффективность MiniMax 2.5 в инструментальных задачах и RAG, хвалят скорость, но указывают на отсутствие поддержки изображения и аудио на входе — что M2.7 может исправить.
- z_3454_pfk хвалит MiniMax 2.5 за эффективность с тулингом и RAG, но отмечает отсутствие поддержки изображения и аудио на входе.
- Dismal-Effect-1914 подчёркивает компактность: при 4-битной квантизации модель занимает около 150 ГБ. Это делает её лучшей в балансе производительности и ресурсоёмкости для сред с ограниченным хранилищем.