
Mistral AI представила Mistral Small 4 — новую модель в линейке Mistral Small, которая сводит несколько ранее раздельных возможностей в единую точку развёртывания. Команда Mistral описывает Small 4 как первую модель, совмещающую роли Mistral Small (следование инструкциям), Magistral (рассуждения), Pixtral (мультимодальное понимание) и Devstral (агентное программирование). Итог — одна модель, которая работает как универсальный ассистент, reasoning-модель и мультимодальная система без переключения между моделями в рабочих процессах.
Архитектура: 128 экспертов, разреженная активация
Mistral Small 4 построена по архитектуре Mixture-of-Experts (MoE) — подходу, при котором модель состоит из множества специализированных блоков-«экспертов», и для каждого токена активируется только часть из них. В Small 4 — 128 экспертов, из которых 4 активны на токен. Общее число параметров — 119B, из которых активно 6B на токен (или 8B с учётом embedding- и output-слоёв).
Длинный контекст и мультимодальность
Модель поддерживает контекстное окно в 256k токенов — существенный скачок для практических инженерных задач. Длинный контекст ценен не как маркетинговая цифра, а как операционное упрощение. Он снижает необходимость в агрессивном чанкинге, оркестрации поиска и отсечении контекста при анализе длинных документов, исследовании кодовой базы, multi-file рассуждениях и агентных workflows. Mistral позиционирует модель для общего чата, программирования, агентных задач и сложных рассуждений с текстовыми и изображениями на входе и текстом на выходе. Small 4 попадает в всё более важную категорию универсальных моделей, которые должны справляться и с языковыми, и с визуально-ориентированными корпоративными задачами через единый API.
Настраиваемые рассуждения на этапе инференса
Более важное продуктовое решение, чем размер модели — появление настраиваемого уровня рассуждений. Small 4 предоставляет per-request параметр reasoning_effort. Он позволяет разработчикам увеличивать задержку в обмен на более глубокие рассуждения. В официальной документации reasoning_effort="none" даёт быстрые ответы в стиле чата, эквивалентном Mistral Small 3.2. А reasoning_effort="high" — намеренно пошаговые рассуждения с многословностью, сопоставимой с ранними Magistral-моделями. Это меняет паттерн развёртывания. Вместо маршрутизации (роутинга) между быстрой и reasoning-моделью команды могут держать в сервисе одну модель и варьировать поведение инференса на уровне запроса. Системно это чище и проще управлять в продуктах, где дорогие рассуждения нужны лишь для подмножества запросов.
Заявления по производительности и позиционирование по throughput
Mistral делает акцент и на эффективности инференса. Small 4 обеспечивает сокращение времени завершения на 40% в латентно-оптимизированной конфигурации. В throughput-оптимизированной конфигурации — трёхкратный рост RPS (запросов в секунду). Оба результата в сравнении с Mistral Small 3. Mistral подаёт Small 4 не просто как более крупную reasoning-модель, а как систему, нацеленную на улучшение экономики развёртывания при реальных нагрузках.
Бенчмарки и эффективность генерации
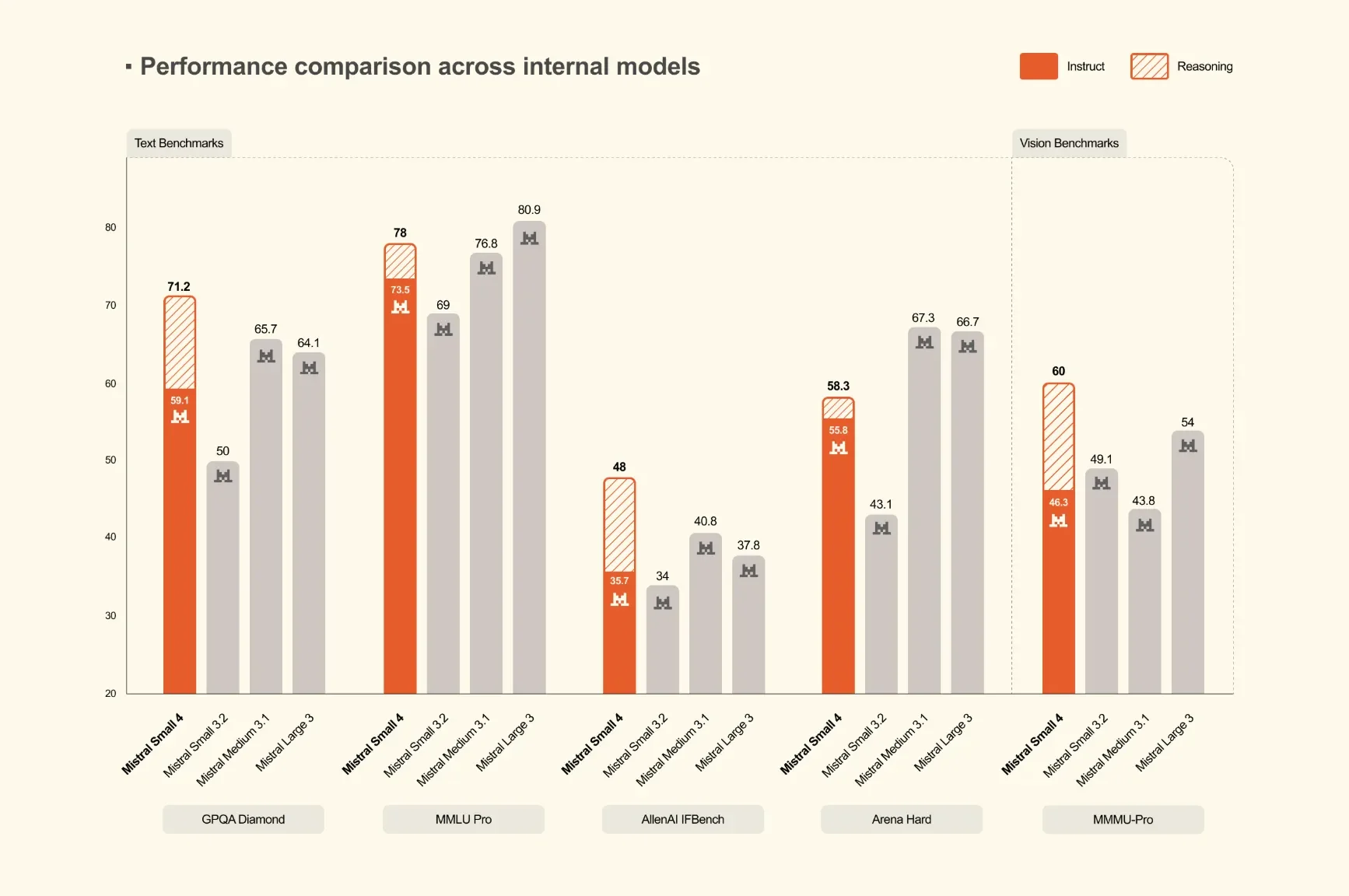
На reasoning-бенчмарках релиз фокусируется и на качестве, и на эффективности вывода. По данным исследовательской команды Mistral, Mistral Small 4 с включёнными рассуждениями соответствует или превосходит GPT-OSS 120B на AA LCR, LiveCodeBench и AIME 2025, генерируя при этом более короткие ответы. В цифрах Mistral: Small 4 набирает 0.72 на AA LCR при 1.6K символов, тогда как Qwen-моделям требуется от 5.8K до 6.1K символов для сопоставимого результата. На LiveCodeBench Small 4 обходит GPT-OSS 120B, выдавая на 20% меньше текста. Это внутренние результаты компании, но они подчёркивают метрику более практичную, чем голый бенчмарк: производительность на сгенерированный токен. Для production-нагрузок более короткие выводы напрямую снижают задержку, стоимость инференса и накладные расходы на обработку ответов downstream.
Детали развёртывания
Для self-hosting Mistral даёт конкретные рекомендации по инфраструктуре. Минимальная конфигурация — 4× NVIDIA HGX H100, 2× NVIDIA HGX H200 или 1× NVIDIA DGX B200. Для лучшей производительности рекомендуются более крупные сборки. На HuggingFace в model card указана поддержка vLLM, llama.cpp, SGLang и Transformers, хотя часть путей помечена как work in progress. vLLM рекомендуется как основной вариант. Mistral также предоставляет кастомный Docker-образ и отмечает, что фиксы, связанные с tool calling и парсингом рассуждений, ещё будут добавлены в upstream-репозитории. Полезная деталь для инженерных команд: поддержка уже есть, но некоторые элементы в opensource-стеке сервинга ещё стабилизируются.
Итоги
- Единая модель: Mistral Small 4 объединяет instruct, reasoning, мультимодальность и агентное программирование в одной модели.
- Разреженный MoE: 128 экспертов, 4 активных на токен — целевая эффективность выше, чем у dense-моделей (где все параметры активны на каждом токене) сопоставимого общего размера.
- Длинный контекст: окно в 256k токенов, вход — текст и изображения, выход — текст.
- Настраиваемые рассуждения: параметр
reasoning_effortна уровне инференса заменяет маршрутизацию между отдельными быстрой и reasoning-моделями. - Открытое развёртывание: модель выпущена под Apache 2.0, поддерживает сервинг через vLLM и другие стеки, на Hugging Face доступны несколько вариантов чекпоинтов.
Подробнее: Model Card на Hugging Face и технические детали.