
Состоялась конференция NVIDIA GTC. В ходе своего двухчасового keynote без суфлёра Дженсен Хуанг прошёлся по всей экосистеме NVIDIA и торжественно преподнёс свой пояс чемпиона InferenceMAX. Blackwell и Rubin продаются очень хорошо (хотя бухгалтерия требует внимания), а теперь к ним добавился Vera:
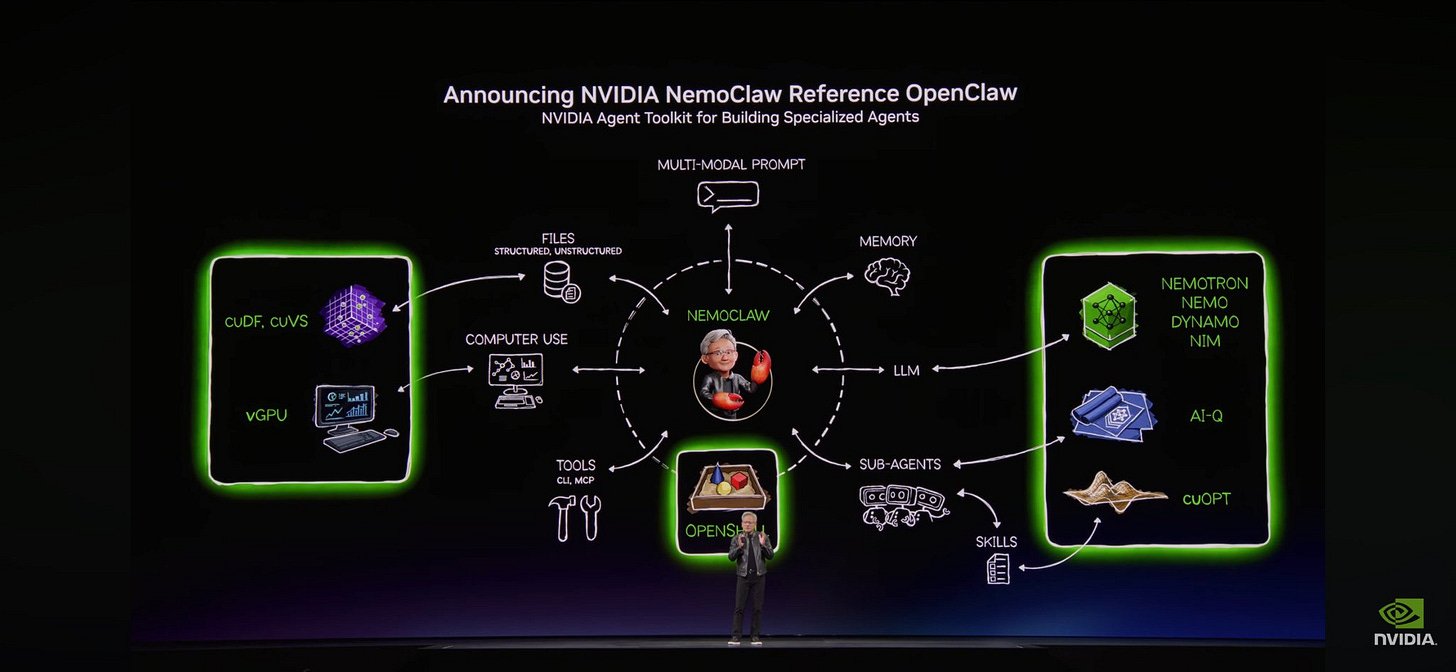
Финальная часть keynote была посвящена OpenClaw. Дженсен восхвалил проект, указал на проблемы безопасности и предложил своё решение — NemoClaw:
NVIDIA двигается впечатляюще быстро для компании с капитализацией $4 трлн — мы пригласили представителей их нового поколения лидеров на подкаст, чтобы они рассказали, как это работает изнутри.
Исследования архитектур: Attention Residuals от Moonshot и спор о приоритете
-
Статья Moonshot про
Attention Residuals— самая ясная техническая история за неделю: @Kimi_Moonshot предложил заменить фиксированное накопление residual-связей (связей, пропускающих сигнал в обход слоёв) на attention по предыдущим слоям, зависящее от входа. Плюс Block AttnRes для практичной реализации cross-layer attention — внимания между слоями. Заявленные результаты: выигрыш в вычислениях 1.25x, накладные расходы на inference <2%, валидация на модели Kimi Linear (48B параметров всего / 3B активных). Последующие посты выделили улучшенный контроль амплитуды скрытых состояний и более равномерные градиенты по глубине (тред со статьёй, ссылка на PDF). Релиз вызвал положительную реакцию у практиков и исследователей, включая @Yuchenj_UW, @elonmusk, @nathancgy4, а также серию визуальных объяснений от @eliebakouch и @tokenbender. -
Развернулась дискуссия второго порядка: это новое или «новое на масштабе»: @behrouz_ali указал на существенное пересечение с более ранними работами вроде DeepCrossAttention, раскритиковав отсутствие цитат и раздувание новизны в ML. @cloneofsimo отметил, что Google исследовал похожие идеи раньше. Другие возразили: системная работа и evidence при масштабировании не менее важны, чем оригинальность идеи (контекст, дополнительно). Итог: статья значима и как архитектурное предложение, и как пример постоянного напряжения в поле между новизной идеи, качеством цитирования и валидацией на frontier-масштабе (масштабе самых больших современных моделей).
Coding-агенты, харнесы и инфраструктура навыков
-
Momentum Codex от OpenAI всплывал многократно: OpenAI Devs продвигали мероприятие Codex x Notion. Посты компании и комментарии руководства делали акцент на быстром принятии. @fidjissimo сообщил, что у Codex уже 2M+ еженедельных активных пользователей — рост почти в 4x с начала года. При этом OpenAI строит подразделение для корпоративного развёртывания. @sama добавил, что «hardcore-разработчики» переходят на Codex. @gdb сообщил, что GPT-5.4 достиг 5 трлн токенов/день за неделю и $1 млрд annualized run-rate (прогноз годовой выручки, экстраполированный из текущих показателей) в новом доходе. На уровне продукта Codex также получил subagents, закрепляя сдвиг к multi-agent рабочим процессам в коде.
-
Инфраструктурный слой вокруг coding-агентов быстро созревает: @AndrewYNg расширил Context Hub / chub — открытый CLI для актуальных API-документаций, который теперь поддерживает feedback-циклы агентов (циклы обратной связи) по документации. @AssemblyAI выпустили поддерживаемый skill (набор инструкций для агента) для Claude Code, Codex, Cursor и совместимых агентов. Теперь они могут использовать актуальные API-паттерны вместо устаревших данных из обучающей выборки. @dair_ai отметил статью об автоматическом извлечении навыков агентов из GitHub-репозиториев в стандартизированный
SKILL.mdс заявленным выигрышем 40% в переносе знаний. Вместе это указывает на новый tooling-стек для агентов: файлы навыков, актуальная документация, каналы обратной связи и процедурные знания, добытые из репозиториев. -
LangChain продвинулся дальше в «agent harness engineering»: @LangChain запустил LangGraph CLI для терминальных потоков разработки и деплоя. Экосистема открыла исходный код Deep Agents — проект, который @itsafiz и @simplifyinAI описывают как MIT-лицензированную реализацию workflow топовых coding-агентов. Включает планирование/todos, файловые операции, shell-доступ, субагентов и управление контекстом. Внутренне @Vtrivedy10 сообщил, что это также база для продакшен-работы агентов и evals (оценок качества). Заметный паттерн: команды больше не просто выпускают модели — они выпускают референсные харнесы (эталонные каркасы для управления агентами).
Open-source агенты: прорыв Hermes, интеграции OpenClaw и UX
-
Hermes Agent пережил сильный community-цикл: хакатон-проекты охватили домашнюю медиа-автоматизацию (аниме-сервер от @rodmarkun), кибер-инструментарий (@aylacroft), геополитический/OSINT-прогнозинг (@WeXBT) и визуализацию исследований (@t105add4_13). Настроение пользователей стабильно: Hermes проще в настройке и надёжнее OpenClaw — см. @Zeneca, @fuckyourputs, @austin_hurwitz, @0xMasonH. @Teknium также опубликовал гайды, включая включение Honcho memory.
-
OpenClaw при этом продолжил расширять экосистему: @ollama объявил Ollama официальным провайдером для OpenClaw. Comet выпустил плагин observability для трейсинга вызовов, инструментов и затрат. Появились сторонние моды вроде NemoClaw. Главный вывод: не «победитель получает всё», а то, что open-агенты начинают напоминать классические программные экосистемы: провайдеры, бэкенды памяти, трейсинг, онбординг-гайды и расширения через хакатоны.
Релизы моделей и продуктов: Perplexity Computer, Gemini Embeddings, сигналы от Mistral/Minimax
-
Релиз Perplexity
Computer— самый конкретный end-user запуск агента: @AravSrinivas и @perplexity_ai объявили о Computer на Android. Затем расширили его так, что Computer может управлять Comet и использовать локальный браузер как инструмент. Без коннекторов/MCP (Model Context Protocol), с сохранением локальных cookies и видимостью действий для пользователя (детали, заметка о реализации). Это существенно, потому что расширяет agentic-выполнение от cloud-интеграций до разрешённого управления локальным браузером. -
Google добавил фундаментальный мультимодальный примитив: @Google запустил Gemini Embedding 2 в public preview через Gemini API и Vertex AI. Позиционируется как единое embedding-пространство для текста, изображений, видео и аудио с поддержкой 100+ языков. Подобный релиз может оказаться более значимым для продакшен-систем поиска и ретривала, чем очередной бенчмарк frontier-chat модели.
-
Другие сигналы по моделям: @matvelloso похвалил gemini-3.1-flash-lite-preview за соотношение цена × latency × интеллект. @QuixiAI реверс-инжинирнул Qwen 3.5 FP8 (8-битный формат чисел с плавающей точкой) и запустил Qwen3.5-397B-FP8 на 8× MI210 со скоростью 6 tok/s (заметка о запуске). @AiBattle_ и @kimmonismus указали на скорый выход MiniMax 2.7. @scaling01 обнаружил Leanstral в составе Mistral Small 4. @SeedFold выпустил SeedProteo для проектирования белков с нуля на уровне отдельных атомов с помощью диффузионных моделей (diffusion-based de novo all-atom дизайн).
Системы, inference и графика: GTC, Speculative Decoding и DLSS 5
-
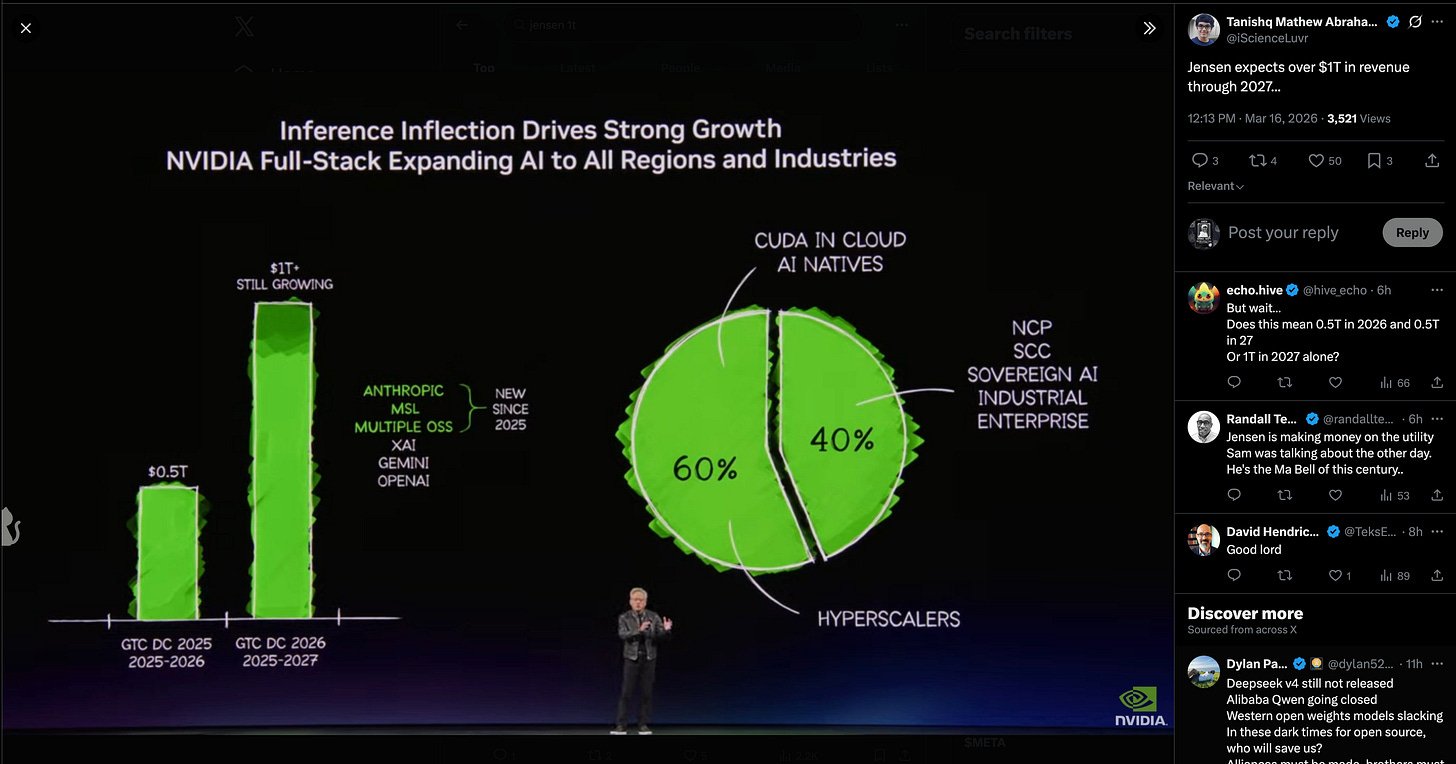
Посыл NVIDIA GTC был однозначен: центр тяжести — inference. Формулировка Дженсена о «инференсной точке перегиба» широко цитировалась (цитата от @basetenco), наряду с экосистемными постами от @nvidia, @kimmonismus и других. Вокруг конференции выпали несколько инфраструктурных апдейтов. Среди них — гайд vLLM по продакшен-стеку на OCI. Заметный системный вклад — P-EAGLE. Он убирает последовательный bottleneck в speculative decoding (технике ускорения генерации, где вспомогательная модель заранее генерирует черновые токены). P-EAGLE генерирует K draft-токенов за один проход. Заявленное ускорение до 1.69x над EAGLE-3 на B200, интеграция в vLLM v0.16.0.
-
На графической стороне доминировал DLSS 5: NVIDIA позиционировала его как самый большой скачок в графике со времён real-time ray tracing. Сильная реакция от @ctnzr, @GeForce_JacobF и обсуждение от Digital Foundry. Ключевое техническое утверждение — полностью генеративный нейронный рендеринг и перерасчёт освещения с сохранением оригинальной геометрии и ассетов. Это существенно продвигает визуальную точность в реальном времени. Не напрямую LLM-история, но в русле общего тренда к нейронизированным runtime-системам (системам выполнения, где нейросети берут на себя часть вычислений).
ИИ в науке, медицине и безопасности
-
Самый содержательный пост о науке и здоровье — тред Microsoft про GigaTIME: @AnishA_Moonka резюмировал работу Microsoft, Providence и UW. Модель предсказывает пространственную протеомику (распределение белков в ткани) в стиле мультиплексной иммунфлуоресценции по патологическому слайду за $5. Модель обучена на 40M клеток, применена к 14 256 пациентам из 51 больницы. Сгенерировано ~300k виртуальных белковых карт, выявлено 1 234 валидированных ассоциаций. В треде утверждается, что модель open-source, и аргументируется, что это может демократизировать иммунный профилирование рака в масштабе.
-
Другие технически значимые новости по науке/безопасности: @GoogleResearch описал исследование, оценивающее LLM на рассуждениях о высокотемпературной сверхпроводимости. Утверждается, что модели, обученные на отобранных данных в закрытой среде, превосходят web-heavy подходы для научных задач. @AISecurityInst оценил семь frontier-моделей на киберполигонах по способности к автономной атаке. @askalphaxiv выделил Temporal Straightening for Latent Planning от LeCun. Выпрямление латентных траекторий (путей в скрытом пространстве модели) улучшает стабильность планирования, делая евклидово расстояние лучшим индикатором достижимого прогресса.
Топ твитов (по вовлечённости)
- Влияние foundation-моделей в медицине: тред GigaTIME: патология → пространственная протеомика — самый информативный технический пост с высокой вовлечённостью.
- Архитектурные инновации: релиз Attention Residuals от Moonshot — исключительная вовлечённость и широкая экспертная дискуссия.
- Momentum продукта coding-агентов: @sama о росте Codex и @gdb о разгоне API GPT-5.4 — самые ясные сигналы со стороны спроса.
- Экосистема open-агентов: Ollama становится провайдером OpenClaw — одно из крупнейших по вовлечённости объявлений в open-agent инфраструктуре.
- Инфраструктура знаний агентов: @AndrewYNg о Context Hub — выделяется как конкретное предложение для агент-к-агент обмена документацией.