
Искусственный интеллект работает на токенах. Каждый промпт, шаг рассуждения и взаимодействие агента генерирует токены. За последний год их потребление выросло многократно и сейчас превышает 10 квадриллионов токенов в год. Раньше большинство токенов порождалось людьми. Новая эра — это токены, которые генерирует AI при взаимодействии с AI.
Современные agentic-системы (системы из нескольких AI-агентов, выполняющих задачи автономно) планируют задачи, вызывают инструменты, исполняют код, извлекают данные и координируют работу в непрерывных многошаговых процессах. Эти взаимодействия создают огромные объёмы reasoning-токенов (токенов, используемых моделью для внутренних рассуждений), раздвигают KV cache (кэш, хранящий ключи и значения предыдущих токенов для контекста) и требуют изолированных CPU-окружений (sandbox) для тестирования и валидации результатов от ускорительных систем. Всё это предъявляет жёсткие требования к низкой задержке и высокой пропускной способности — от GPU и CPU до scale-up-доменов (объединения GPU в единый вычислительный кластер), scale-out-сетей (распределения задач между отдельными серверами) и хранилищ.
Чтобы обеспечить полезный интеллект для таких систем, нужны целые парки специализированных стоек, работающих как единый AI-суперкомпьютер. В этой статье представляем NVIDIA Vera Rubin POD — набор из пяти специализированных стоек, построенных на базе стоечной архитектуры NVIDIA MGX третьего поколения и созданных для эпохи agentic AI.
Знакомство с NVIDIA Vera Rubin POD
Платформа NVIDIA Vera Rubin создана через глубокий co-design (совместное проектирование) семи чипов — вычислительных, сетевых и для хранения. Это самая сложная POD-платформа от NVIDIA. В её составе: 40 стоек, 1,2 квадриллиона транзисторов, почти 20 000 чипов NVIDIA, 1 152 GPU NVIDIA Rubin, 60 экзафлопс и суммарная полоса пропускания scale-up 10 ПБ/с.
Vera Rubin POD включает пять новых специализированных стоек для agentic AI-нагрузок. Этим нагрузкам требуются высокая пропускная способность, экстремально низкая задержка инференса, плотная CPU-изоляция и массивное хранилище контекстной памяти. Вместе стойки образуют единую систему для самых энергоэффективных дата-центров.

Рис. 1. NVIDIA Vera Rubin POD включает пять стоек, объединённых в один AI-суперкомпьютер на базе архитектуры NVIDIA MGX
Каждый чип в POD масштабируется внутри стоек MGX третьего поколения. Экосистему поддерживают более 80 партнёров с глобальной цепочкой поставок, имеющей опыт вывода крупномасштабных AI-систем на рынок. Все стойки MGX делят общие габариты питания, охлаждения и механики — это обеспечивает быстрое развёртывание и бесшовные переходы между поколениями.
Существует два типа MGX-стоек с медными спайнами (тяжёлыми коммутационными панелями на задней стороне), спроектированных для производительности, отказоустойчивости и энергоэффективности. MGX NVL соединяется через NVIDIA NVLink, а новая MGX ETL — через один из двух типов спайна: NVIDIA Spectrum-X Ethernet или прямые чип-к-чип связи NVIDIA Groq 3 LPU.
NVIDIA Vera Rubin NVL72: платформа для четырёх законов масштабирования
NVIDIA Vera Rubin NVL72 — базовый стоечный вычислительный движок современной AI-фабрики. Стойка интегрирует 72 GPU NVIDIA Rubin и 36 CPU NVIDIA Vera, соединённых массивной медной спайной NVLink. Она работает как один гигантский GPU. NVL72 спроектирована для четырёх законов масштабирования AI: предобучение, постобучение, масштабирование на этапе инференса (test-time scaling) и agentic-масштабирование. Система оптимизирована для сложной маршрутизации mixture-of-experts (MoE — архитектуры, где разные части модели специализируются на разных задачах) и compute-bound фазы контекста при инференсе (фазы, ограниченной вычислительной мощностью, а не памятью). Даёт до 4x прирост производительности при обучении и до 10x при инференсе на ватт. Стоимость токена снижается в 10 раз по сравнению с NVIDIA Blackwell.
NVIDIA Groq 3 LPX: стойки инференс-ускорителей
Co-design с платформой Vera Rubin для массивного контекста и низких задержек agentic AI. Каждая стойка Groq 3 LPX содержит 256 LPU (language processing units — специализированных процессоров для обработки языка). Работает в паре с Vera Rubin NVL72, устраняя компромисс между скоростью интерактивности и пропускной способностью. Объединение высокополосных SRAM-only LPU (процессоров, использующих только быструю SRAM-память) с Rubin GPU с большим объёмом HBM обеспечивает низкую задержку и высокую пропускную способность на длинных контекстах. Это ускоряет интерактивность триллионно-параметровых моделей без потери системной пропускной способности. Связка NVL72 + LPX даёт до 35x больше токенов и до 10x больше выручки для триллионно-параметровых моделей по сравнению с Blackwell. Подробнее — в статье Inside NVIDIA Groq 3 LPX.
NVIDIA Vera CPU rack: agentic AI и reinforcement learning в масштабе
Стойка NVIDIA Vera CPU объединяет до 256 CPU NVIDIA Vera в плотной жидкостно-охлаждаемой стойке. Одна стойка поддерживает более 22 500 одновременных окружений reinforcement learning (RL) (обучения с подкреплением) или sandbox-агентов — максимальное количество сред для тестирования, исполнения и валидации результатов от стоек Vera Rubin NVL72 и LPX. Стойки Vera CPU — фундамент крупномасштабного agentic AI и RL: в два раза эффективнее и на 50% быстрее традиционных стоечных CPU. Подробнее — в статье о том, как Vera CPU обеспечивает высокую пропускную способность и эффективность для AI-фабрик.
NVIDIA BlueField-4 STX: AI-native хранилище
Стойка NVIDIA BlueField-4 STX построена на процессоре BlueField-4, объединяющем Vera CPU и ConnectX-9 SuperNIC (специализированный сетевой интерфейс). Масштабируется через сеть Spectrum-X Ethernet.
На ней развёрнута платформа контекстной памяти NVIDIA CMX — новый класс AI-native инфраструктуры хранения, спроектированной специально для AI-нагрузок. CMX бесшовно расширяет GPU-контекст на весь POD и ускоряет инференс, выгружая KV cache в выделенный высокополосный слой хранения. Платформа оптимизирована для хранения и отдачи массивного контекста, обрабатывая временный контекст инференса как нативный AI-тип данных. Этот контекст переиспользуется между ходами, сессиями и агентами. Это даёт до 5x больше токенов в секунду и до 5x лучшей энергоэффективности по сравнению с традиционными подходами к хранению.
NVIDIA Spectrum-6 SPX: сетевые стойки
Весь POD объединяется в единый суперкомпьютер через сетевые стойки NVIDIA Spectrum-6 SPX. Они ускоряют east-west трафик (между серверами внутри дата-центра) и north-south трафик (между дата-центром и внешней сетью) внутри AI-фабрик. Конфигурируются с коммутаторами Spectrum-X Ethernet или NVIDIA Quantum-X800 InfiniBand — обеспечивая низкую задержку и высокую пропускную способность между стойками в масштабе.
Стойка Spectrum-6 SPX включает коммутатор Spectrum-6 на 102,4 Тб/с с 512 линиями и co-packaged optics (CPO — оптические интерфейсы, интегрированные прямо в чип коммутатора) на 200 Гб/с в одно- и многочиповых исполнениях. Эта интеграция кремниевой фотоники заменяет плаггаемые трансиверы, обеспечивая максимальную энергоэффективность и отказоустойчивость, низкую задержку и джиттер (небольшие колебания времени доставки пакетов). Также обеспечивается почти идеальная эффективная полоса пропускания для синхронизации AI-нагрузок между вычислительными и хранилищными средами.
Co-design этих специализированных стоек позволяет Vera Rubin POD ускорить каждый компонент agentic AI-нагрузок. Всё строится на унифицированной архитектуре NVIDIA MGX.
Архитектура NVIDIA MGX третьего поколения
Серийные AI-стойки должны соответствовать множеству критериев: быстрый выход на объём, доказанная производительность в масштабе, глубокий hardware-software co-design, отказоустойчивость и энергоэффективность, бесшовное развёртывание, готовность к будущим архитектурам.
Архитектура MGX третьего поколения задаёт стандарт по всем направлениям с инженерными прорывами в механическом дизайне, питании и охлаждении.
Отказоустойчивость и масштабируемость
MGX приоритизирует PCB-соединения (соединения через печатные платы) в одинарной ширине. Это раскрывает полностью модульный дизайн без кабелей, шлангов и вентиляторов. Вычислительные trays (выдвижные модули) и NVLink-коммутаторы получают максимальную надёжность, масштабируемость и обслуживаемость. Одинарные 19-дюймовые стойки также упрощают логистику и ускоряют развёртывание в AI-фабриках.

Рис. 2. Spine стойки NVIDIA MGX вмещает тысячи кабелей и конфигурируется с NVLink для MGX NVL, а также с Spectrum-X Ethernet или прямыми чип-к-чип связями Groq 3 LPU для MGX ETL
Стойка оснащена высокомодульным spine как бэкплейном — до четырёх преинтегрированных и превалидированных медных картриджей, соединяющих каждый tray в единое целое. Spine держит тысячи кабелей и использует один и тот же форм-фактор для MGX NVL и MGX ETL.
Энергоэффективность от чипа до сети
На уровне компонентов стойки MGX оснащены динамическим распределением питания (dynamic power steering): система направляет энергию туда, где она нужна больше. Питание перераспределяется между CPU, GPU и NVLink-коммутаторами для обеспечения пиковой энергоэффективности каждого компонента.
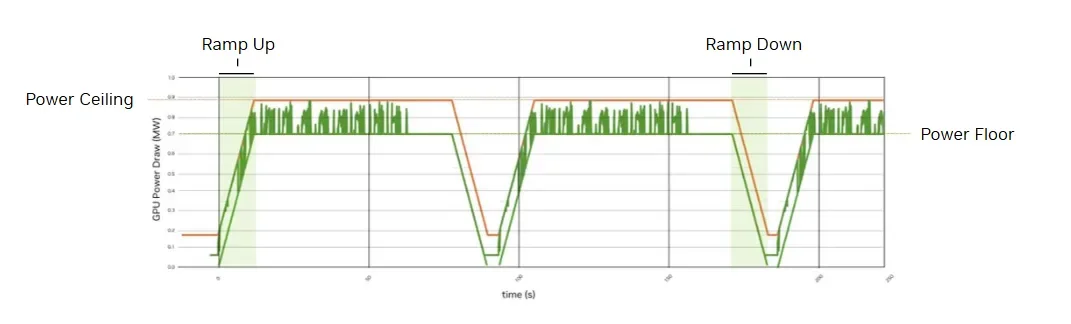
Рис. 3. Стойки NVIDIA MGX используют Intelligent Power Smoothing для поддержания пиковой энергоэффективности компонентов
AI-обучение и инференс создают большие колебания нагрузки. Без управления они создают серьёзную нагрузку на электросеть, инфраструктуру питания дата-центра и IT-оборудование.
Для защиты от скачков мощности MGX-стойки оснащены накопителями энергии на уровне стойки — конденсаторами, смягчающими power transients (резкие скачки потребления). Когда нагрузка резко возрастает, конденсатор дополняет питание, а потребление от сети остаётся ровным. Когда нагрузка падает, конденсатор заряжается, снова без скачков сети.
Vera Rubin NVL72 добавляет Intelligent Power Smoothing: в 6 раз больше накопителей энергии на уровне стойки (400 Дж на GPU) и новую замкнутую систему. В ней GPU непрерывно мониторят заряд конденсаторов для более эффективного выравнивания профиля мощности. Результат — существенно меньшие колебания AC-мощности в минуту, снижение пикового потребления тока до 25% и отказ от массивных батарей для защиты от power transients.
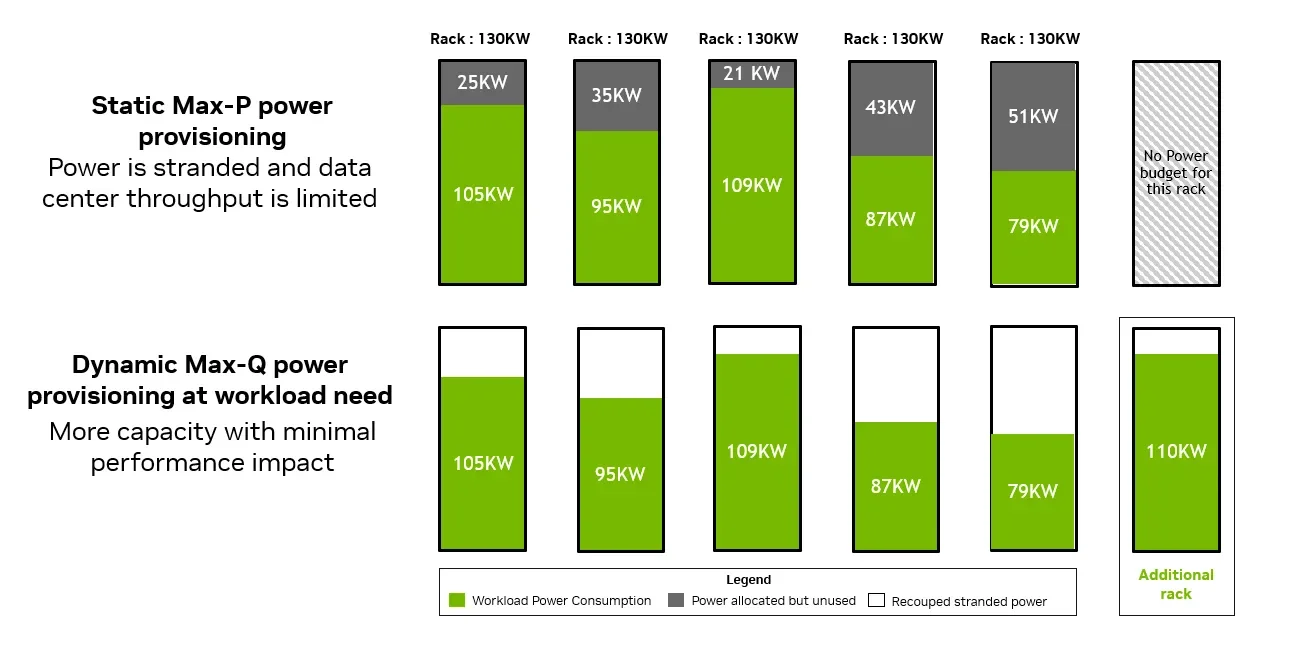
Рис. 4. Dynamic Max-Q высвобождает «застрявшую» мощность и разблокирует дополнительную GPU-ёмкость
На уровне инфраструктуры выделение стоек по статическому Max-P замораживает мощность, которую можно было бы потратить на генерацию токенов. Это предполагает однородные нагрузки с постоянным пиковым потреблением. Однако AI-фабрики запускают смесь нагрузок с разным профилем питания.
Выделяя MGX-стойкам более низкий динамический Max-Q, дата-центры максимизируют пропускную способность. Энергия динамически направляется каждой стойке в нужном объёме. Это освобождает «застрявшую» мощность, разблокирует до 30% больше GPU в том же бюджете при 45°C жидкостного охлаждения и повышает производительность на ватт.
Большие энергобюджеты для вычислений
Все MGX-стойки универсально спроектированы для работы с температурой входной воды 45°C — дата-центры с жидкостным охлаждением получают бесшовный переход без перестройки инфраструктуры. На рис. 5 показана схема: внешняя вода при 41°C подаётся в CDU (блоки распределения охлаждающей жидкости), которые поставляют охлаждающую жидкость при 45°C на AI-стойки.
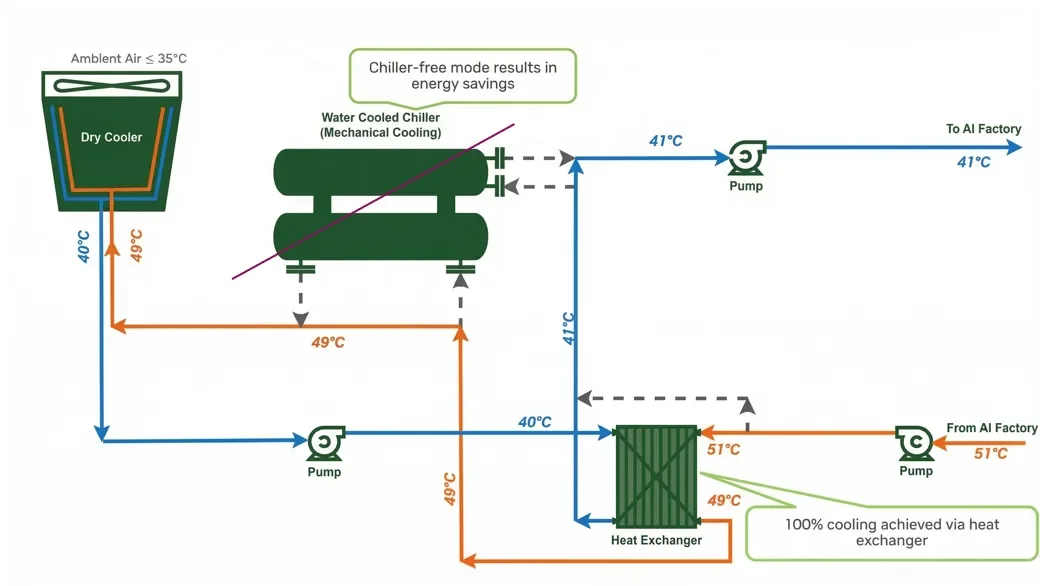
Рис. 5. Энергоэффективный сценарий свободного охлаждения при 45°C на входе в MGX-стойки
Работа при 45°C позволяет дата-центрам во многих климатических зонах использовать ambient air и dry cooler с замкнутым контуром. Это снижает потребность в компрессорах, уменьшает PUE (отношение общего потребления дата-центра к потреблению IT-оборудования) и высвобождает энергию для вычислений. Более низкие температуры входа (35°C) требуют отвлечения значительных мощностей или воды на охлаждение. Высокие температуры максимизируют долю сетевой энергии, конвертируемой напрямую в токены. Экономия достаточна, чтобы разместить до 10% дополнительных стоек Vera Rubin NVL72 в том же энергобюджете.
MGX-стойки могут быть на 100% жидкостно-охлаждаемыми, используя ту же инфраструктуру, что и предыдущие поколения. Третье поколение MGX включает новые внутренние манифольды trays, rack-манифольды UQD08 и жидкостно-охлаждаемые busbars (токопроводящие шины) до 5 000 А. Выбор охлаждающей жидкости зависит от заказчика, но многие продолжат использовать деионизированную воду или пропиленгликоль (PG25). Он служит до 10 лет в замкнутом контуре с минимальным обслуживанием.
Открытый стандарт
В основе — открытая, стандартизированная архитектура MGX. Первая массовая стоечная система — NVIDIA Blackwell в 2024 году. NVIDIA передала дизайн в Open Compute Project (OCP), подтвердив приверженность open source и позволив экосистеме быстрее инновировать. NVIDIA построила экосистему из 80+ глобальных партнёров с диверсифицированной цепочкой поставок, опытной в выводе стоечных AI-систем на рынок.
Стойки NVIDIA MGX NVL
Как показывают независимые бенчмарки SemiAnalysis InferenceMax, стоечные системы NVIDIA дают 50x лучшую производительность на ватт и 35x меньшую стоимость токена (NVIDIA GB300 NVL72 vs NVIDIA H200). Это напрямую трансформируется в выручку и операционную маржу.
В 2024 году NVIDIA отгрузила первые GB200 NVL72. В 2025 — GB300 NVL72. Теперь Vera Rubin NVL72 в полном производстве, отгрузки запланированы на вторую половину 2026 года.
Упрощённый дизайн NVIDIA Vera Rubin NVL72
NVIDIA Vera Rubin NVL72 — инженерное решение, которое встаёт в существующие стойковые места дата-центров без доработок. При почти двукратном увеличении числа транзисторов по сравнению с GB200 NVL72 она даёт 10x производительности на ватт через экстремальный co-design. Стойка интегрирует 72 GPU Rubin, 36 CPU Vera, ConnectX-9 SuperNIC и BlueField-4 DPU (специализированный процессор для сетевых и вычислительных задач инфраструктуры) на 18 вычислительных tray, плюс 9 NVLink-коммутаторных tray. Всего 1,3 млн индивидуальных компонентов, почти 1 300 чипов — в одинарной стойке MGX третьего поколения весом около 1 800 кг (примерно как пикап).

Рис. 6. Стойка NVIDIA Vera Rubin NVL72
Вычислительные и NVLink Switch tray
72 GPU работают как единый движок благодаря NVLink шестого поколения: 3,6 ТБ/с на GPU и 260 ТБ/с scale-up полосы на стойку — больше, чем полоса пропускания всего глобального интернета. Этот высокоскоростной обмен данными проходит через NVLink spine на задней панели стойки. Это четыре модульных преинтегрированных картриджа с 5 000 медных кабелей общей длиной более 3 км.
Видео 1. Ключевые отличия вычислительного tray NVIDIA Vera Rubin от NVIDIA Grace Blackwell
Вычислительные tray внутри Vera Rubin NVL72 полностью переработаны по сравнению с Blackwell. Жёсткий PCB-midplane (центральная печатная плата-перекрытие), рассчитанный на одинарную стойку, позволяет обойтись без кабелей, шлангов и вентиляторов. Это сокращает время сборки compute tray с почти двух часов до пяти минут — ускорение сборки и обслуживания до 20x.
Каждый compute tray содержит два суперчипа NVIDIA Vera Rubin по 17 000 компонентов каждый — примерно в пять раз больше, чем в современном смартфоне. Суперчипы через PCB-midplane соединяются с фронтальными модульными бэями, где установлены восемь ConnectX-9 SuperNIC и один BlueField-4 DPU.

Рис. 7. NVLink Switch tray NVIDIA Vera Rubin
Vera Rubin NVL72 добавляет новые механизмы отказоустойчивости на уровне стойки для максимизации uptime (времени непрерывной работы) и goodput (эффективной пропускной способности без учёта повторных запросов) крупных AI-кластеров. NVLink Switch tray поддерживают режим обслуживания — администраторы могут переводить коммутаторы в maintenance mode и заменять их без остановки стойки. Архитектура также допускает продолжение работы при недоступности нескольких switch tray, минимизируя простои.
На уровне кремния GPU Rubin непрерывно запускают nondisruptive health checks (проверки состояния без прерывания работы), а CPU Vera поддерживают in-system testing и память SOCAMM для более быстрого обслуживания. Совместно эти инновации от чипа до стойки снижают операционные накладные расходы и развивают достижения отказоустойчивости кластеров Blackwell.
NVIDIA Vera Rubin Ultra NVL576
Vera Rubin Ultra вводит новую двухуровневую all-to-all NVLink-топологию (топологию, где каждый узел напрямую связан с каждым) для масштабирования до 576 GPU. NVL576 объединит восемь отдельных MGX NVL-стоек по 72 GPU Rubin Ultra каждая в едином NVLink-домене на 576 GPU с медными и прямыми оптическими соединениями. Построена на той же экосистеме MGX для быстрейшего выхода в производство.
Масштаб этой топологии демонстрирует Polyphe — внутренний полнофункциональный прототип NVIDIA на базе GB200, реализующий multirack NVL576 scale-up.

Рис. 8. Прототип NVIDIA Polyphe — полнофункциональная multirack NVL576 scale-up система на базе GB200
NVIDIA Kyber NVL1152: следующее поколение
Для масштабирования за пределы NVL576 будет представлена новая стойка — NVIDIA Kyber. Это следующее поколение MGX NVL, удваивающее NVLink-домен на стойку до 144 GPU.

Рис. 9. NVIDIA Kyber NVL1152
Kyber масштабируется до массивного all-to-all NVL1152 суперкомпьютера через аналогичные прямые оптические межстоечные соединения. Kyber задаёт фундамент следующей эры экстремального scale-up AI-вычислений на базе NVIDIA Feynman. Первоначально Kyber будет представлен с Vera Rubin Ultra как самостоятельная NVL144 система, предлагая клиентам три варианта NVLink scale-up доменов: NVL72, NVL144 и флагманский NVL576.
Стойки NVIDIA MGX ETL
MGX NVL предоставляют масштабные scale-up вычислительные домены. Однако agentic AI-воркфлоу требуют специализированных узлов для экстремально низко-задержечного инференса, CPU-sandboxing и ускоренного контекстного хранилища для KV cache. Для этого Vera Rubin вводит архитектуру MGX ETL — новую полностью конфигурируемую MGX-стойку со spine на Spectrum-X Ethernet или с прямым чип-к-чип spine. Она использует ту же экосистему, что и MGX NVL.
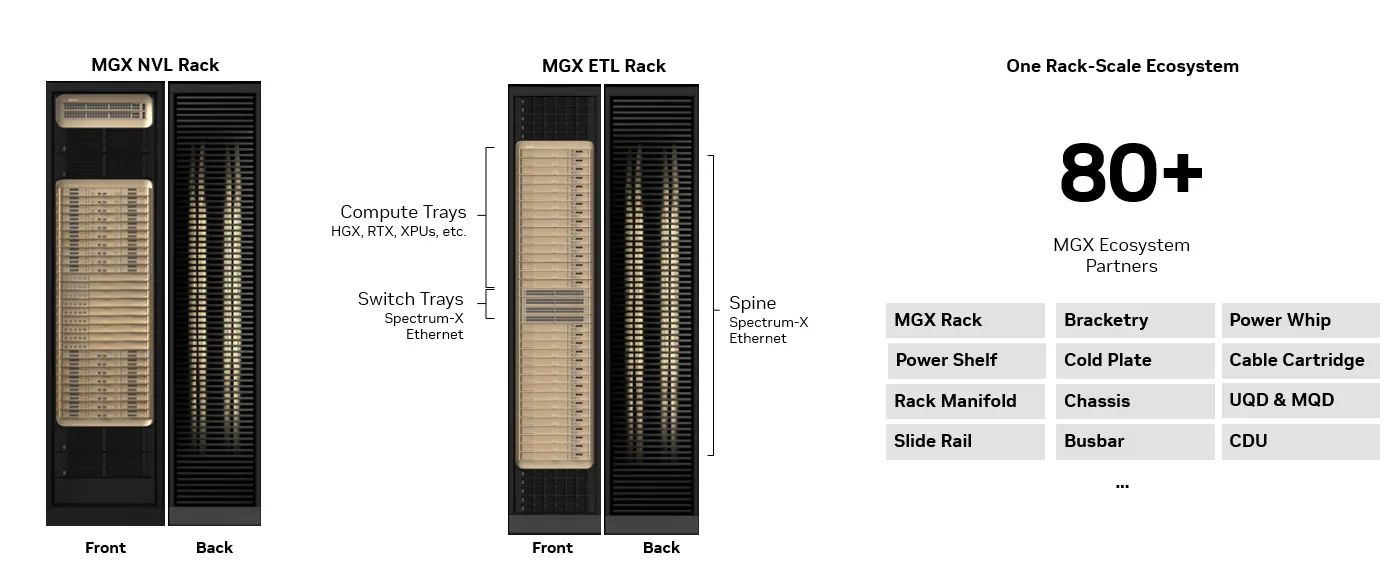
Рис. 10. MGX ETL добавляет поддержку Spectrum-X Ethernet, используя ту же инфраструктуру MGX, включая медный spine в картриджах
MGX ETL делит форм-фактор и физическую инфраструктуру с MGX NVL. Она работает в том же механическом, энергетическом и охлаждающем конверте. Оба типа стоек используют общие ключевые компоненты от экосистемы MGX: стойки, шасси, tray, кабельные картриджи, манифольды жидкостного охлаждения, quick disconnects (быстроразъёмные соединения), busbars, направляющие, power shelves, поддоны для сбора утечек, ручки tray и многое другое.
MGX ETL использует преинтегрированные и превалидированные медные картриджи с spine на Spectrum-X Ethernet или с прямым чип-к-чип spine. Экосистема и цепочка поставок те же, что и у MGX NVL — с многолетним опытом массового производства.
Spine на Spectrum-X Ethernet
MGX ETL со spine на Spectrum-X Ethernet — основа для стоек Vera CPU и BlueField-4 STX в Vera Rubin POD. Стойка высококонфигурируема и может размещать до 256 GPU Rubin (системы HGX Rubin NVL8), XPU и другое.

Рис. 11. 1U MGX ETL switch tray обеспечивает связность Spectrum-X Ethernet для spine
В этой конфигурации 1U MGX ETL switch tray (на базе Spectrum-6) располагаются в центре стойки. Задние порты подключаются к медному spine, а 32 фронтальных OSFP-разъёма обеспечивают оптическую связность с остальным POD.
MGX ETL использует топологию Spectrum-X Multiplane, которая распределяет линии 200 Гб/с по нескольким коммутаторам. Это обеспечивает полную all-to-all связность между узлами внутри стойки при сохранении одного сетевого тира (уровня иерархии сети). Преинтегрированный медный spine даёт отказоустойчивую и энергоэффективную связность (между ETL-стойками — с одним тиром оптики) и расширяет специализированный Spectrum-X Ethernet с нулевым джиттером, изоляцией шума и балансировкой нагрузки на всю 256-чиповую стойку.
Прямой чип-к-чип spine
Спроектированный для экстремально низко-задержечного инференса, LPX rack объединяет 256 LPU как единое целое. Содержит 32 compute tray по восемь LPU, соединённых прямым чип-к-чип spine из двух медных картриджей. Они создают сложную point-to-point топологию на тысячах парных медных соединений. Кабели формируют spine на задней панели стойки в том же картриджном форм-факторе, что и другие MGX-стойки. Эта массивная interconnected fabric (интерконнект) позволяет всей 256-LPU стойке работать как единый быстрый инференс-движок, развёртываемый вместе с Vera Rubin NVL72.
При масштабировании на несколько LPX-стоек прямые чип-к-чип связи сохраняются между стойками. Это позволяет нескольким LPX-стойкам работать как единый, невероятно быстрый инференс-движок.
Платформа AI-фабрики NVIDIA Vera Rubin DSX
NVIDIA Vera Rubin DSX — платформа AI-фабрики с blueprint и reference design для co-designed AI-инфраструктуры от чипа до электросети. Максимизирует эффективность преобразования энергии сети в токены, goodput и ускоряет выход на первое производство.
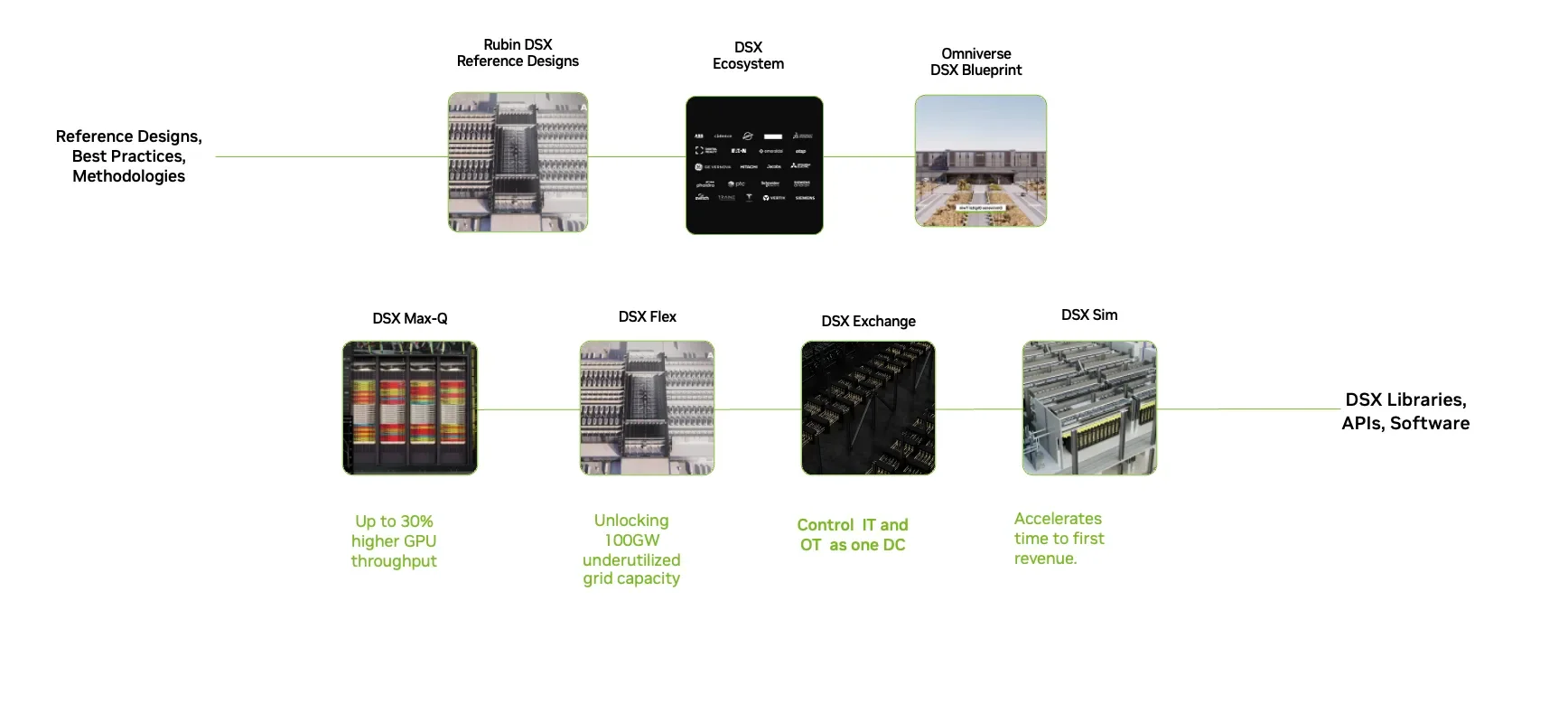
Рис. 12. Опорные элементы NVIDIA Vera Rubin DSX — открытая экосистема для построения AI-инфраструктуры
Vera Rubin DSX объединяет чипы, системы, софтверные библиотеки, API и глобальную партнёрскую экосистему в единую архитектуру. Она тесно интегрирует вычисления, сеть, хранение, питание, охлаждение и управление инфраструктурой на всей AI-фабрике. Это позволяет партнёрам быстро проектировать, развёртывать и масштабировать гигаваттные AI-фабрики с максимальной токен-пропускной способностью на ватт и улучшенным uptime за счёт встроенной отказоустойчивости и энергоэффективности.
Узнайте больше о NVIDIA Vera Rubin POD
AI-инфраструктура быстро эволюционирует: от дискретных чипов и отдельных серверов — к co-designed POD-суперкомпьютерам и AI-фабрикам. Современные agentic AI-нагрузки двигают индустрию к специализированной инфраструктуре, объединяющей вычисления, сеть и хранение в единый суперкомпьютер. NVIDIA Vera Rubin POD объединяет пять стоек с ключевыми механическими, энергетическими и охлаждающими инновациями архитектуры MGX третьего поколения. Это обеспечивает масштабируемость, отказоустойчивость и энергоэффективность.
На масштабе AI-фабрики Reference Design NVIDIA Vera Rubin DSX и NVIDIA Omniverse DSX Blueprint для цифровых двойников AI-фабрик дают единый фреймворк для их построения и эксплуатации. Вместе эти инновации обеспечивают серьёзный прирост производительности, рентабельности и энергосбережения для эпохи agentic-приложений.
Присоединяйтесь к NVIDIA GTC 2026 и смотрите keynote GTC с основателем и CEO NVIDIA Дженсеном Хуангом.