
При переходе от однократных запросов к сложным многошаговым workflow надёжность моделей ломается в предсказуемых местах. Tool-вызовы не соответствуют схемам. Качество reasoning (цепочек рассуждений) деградирует на длинных диалогах. Модели пропускают визуальные сигналы, специфичные для предметной области. Обычно это чинится дополнительным обучением (post-training), но процесс фрагментирован. Итерации идут медленно, а планирование усложняется.
Together AI, облачная платформа для AI, расширяет сервис дообучения. Теперь он нативно поддерживает tool calling, reasoning и vision-language модели (VLM — модели, работающие с текстом и изображениями). Обновлённый стек обучения эффективно работает с моделями frontier-уровня (самыми мощными на рынке) от 100B+ параметров, обеспечивая до 6× прирост throughput (количества обработанных данных в единицу времени). Кроме того, теперь поддерживаются датасеты до 100 ГБ, а команды получают оценку стоимости до старта и ETA в процессе обучения.
«Together AI делает для дообучения и инференса то же, что Vercel — для LLM-приложений: убирает инфраструктурный слой, чтобы мы могли сфокусироваться на продукте. Мы дообучаем и разворачиваем клиентские модели через простые API-вызовы. Это позволило команде перейти от еженедельных итераций к ежедневным, сократить затраты в 2–3 раза и поднять точность с 77% до 87%». — Lamara De Brouwer, Co-Founder & CTO, XY.AI Labs
Дообучение tool calling
Tool calling — ключевой элемент современных agentic-сценариев (сценариев, где модель действует как автономный агент). Но базовые модели из коробки часто галлюцинируют параметры, выбирают неверные функции или ломают многошаговые последовательности. В tool-calling workflow даже небольшие несостыковки каскадно обрушивают downstream-задачи (задачи, зависящие от результатов предыдущих шагов).
Together Fine-Tuning Service теперь предоставляет полное решение для production-grade tool calling — от дообучения до инференса. Tool-вызовы включаются в тренировочные данные через OpenAI-совместимую схему: функции задаются в массиве tools верхнего уровня, а сервис валидирует, что каждый tool_calls соответствует объявленному инструменту — ещё до старта обучения.
На этапе инференса значительно улучшена надёжность tool calling, чтобы результаты дообучения реально отрабатывались в проде. Улучшенные парсинг и валидация повышают корректность на широком спектре задач. Решение опирается на датасеты из сообщества и внутренних исследований.
Tool-call дообучение доступно для моделей от Qwen, Moonshot AI и Z.AI. Подробности — в документации, пример кода — в cookbook.
Дообучение reasoning
Reasoning-модели генерируют промежуточные цепочки рассуждений перед финальным ответом. Но форматы reasoning не стандартизированы между моделями, что усложняет дообучение.
Теперь сервис поддерживает дообучение напрямую на thinking traces (цепочках промежуточных рассуждений) — через поля reasoning или reasoning_content в assistant-сообщениях. Это позволяет обучать модели на предметно-специфичных паттернах рассуждений, сохраняя структуру и воспроизводимость трейсов. Как и с tool calling, улучшен reasoning-инференс, чтобы дообучённые способности надёжно работали downstream.
Доступно для моделей от Qwen и Z.AI. Документация с полным списком моделей, cookbook с полным демо.
Дообучение vision-language моделей
Многие AI-workflow требуют интерпретации изображений. Для предметных задач — медицинская визуализация, eCommerce — VLM нужно дообучать на новых визуальных паттернах.
Сервис теперь поддерживает дообучение VLM. Данные передаются инлайн через массивы content с base64-кодированными изображениями. В рамках одной задачи можно использовать гибридные датасеты — миксы image-text и text-only примеров.
По умолчанию vision encoder (компонент модели, отвечающий за обработку изображений) заморожен, обновляются только языковые слои. Установка train_vision=true включает joint training — совместное обновление и vision encoder, и языковых слоёв.
Доступно для моделей от Qwen, Google и Meta. Документация, cookbook.
Дообучение крупных моделей
По мере роста open-моделей и расширения контекстных окон инфраструктура должна поспевать. Триллионнопараметрические модели не помещаются на одной ноде — требуются продуманные коммуникации и управление памятью между машинами. Один аппаратный сбой за многочасовой прогон — и прогресс потерян. А реализация оптимизаций и fault tolerance (устойчивости к сбоям) требует серьёзных инвестиций.
Теперь сервис поддерживает дообучение новейших open-weights моделей (моделей с открытыми весами). Отправляете задачу — оптимизации происходят под капотом. Новые доступные модели:
- Qwen 3.5-397B-A17B
- Qwen 3.5-122B-A10B
- Qwen 3.5-35B-A3B
- Qwen 3.5-35B-A3B-Base
- Kimi K2.5
- Kimi K2 (Instruct, Thinking)
- GLM-4.7
- GLM-4.6
Полный список с длинами контекста — в документации.
Ускорение обучения
В этом обновлении фокус смещён на самые impactful оптимизации в training stack. Основная мишень — mixture-of-experts архитектуры (MoE, архитектуры, где разные части модели специализируются на разных задачах). Такие модели составляют большинство сильных моделей за последний год. Для ускорения интегрирован вариант SonicMoE — оптимизированные ядра, перекрывающие операции с памятью с вычислениями. Это значительно сократило объём активаций в памяти и минимизировало впустую потраченные вычислительные ресурсы.
Также добавлены кастомные CUDA-ядра (программы для GPU от NVIDIA) для вычисления loss и устранены несколько GPU-to-CPU точек синхронизации в training loop (цикле обучения), которые вызывали ненужные остановки.
Результат: каждая модель получила минимум 2× прирост throughput, а крупные вроде Kimi-K2 — свыше 6×. Быстрее обучение — больше экспериментов за день, быстрее выход в прод.
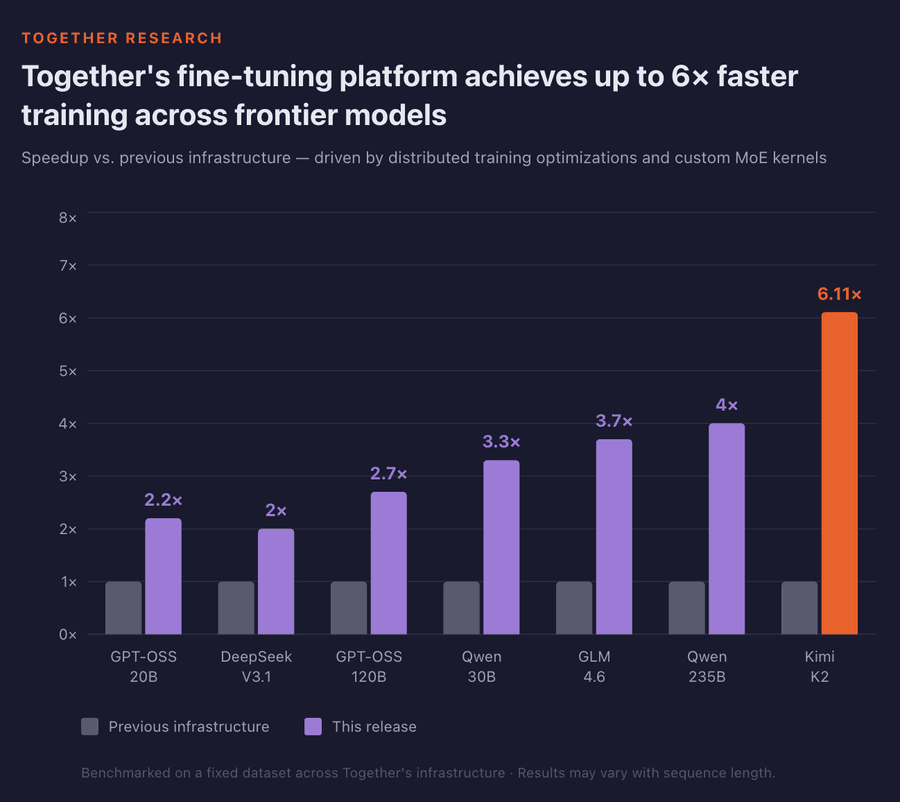
Оценка стоимости и времени
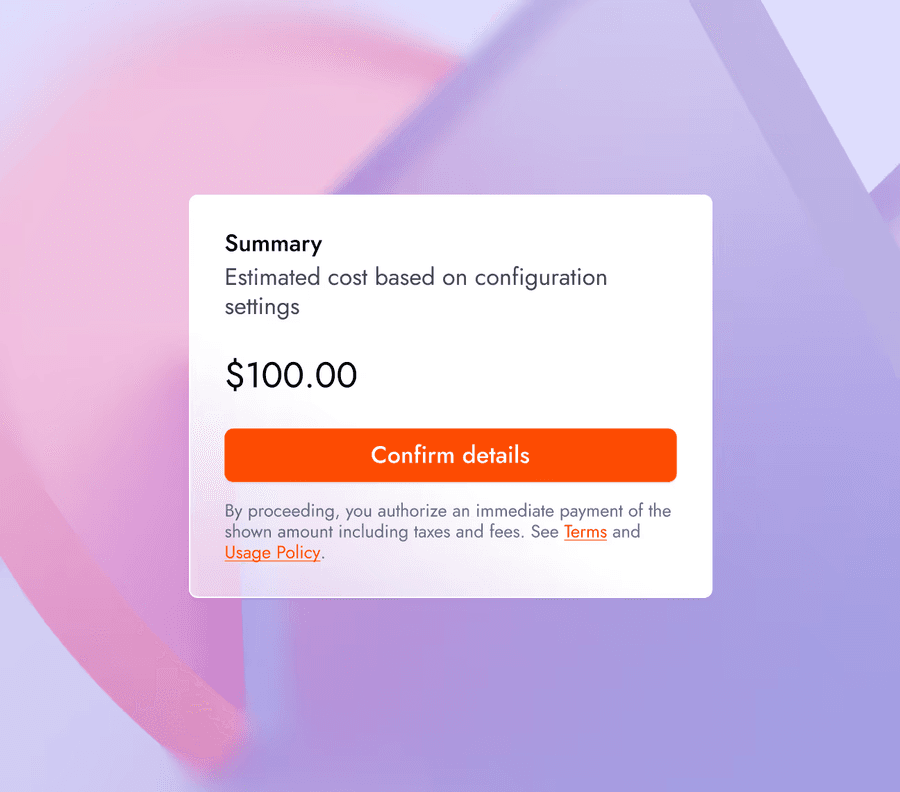
Теперь сервис оценивает стоимость обучения до запуска — через UI или CLI. Прозрачность цен исключает сюрпризы с бюджетом.
Оценка стоимости: увидьте расчётную цену до старта, чтобы понимать затраты заранее.
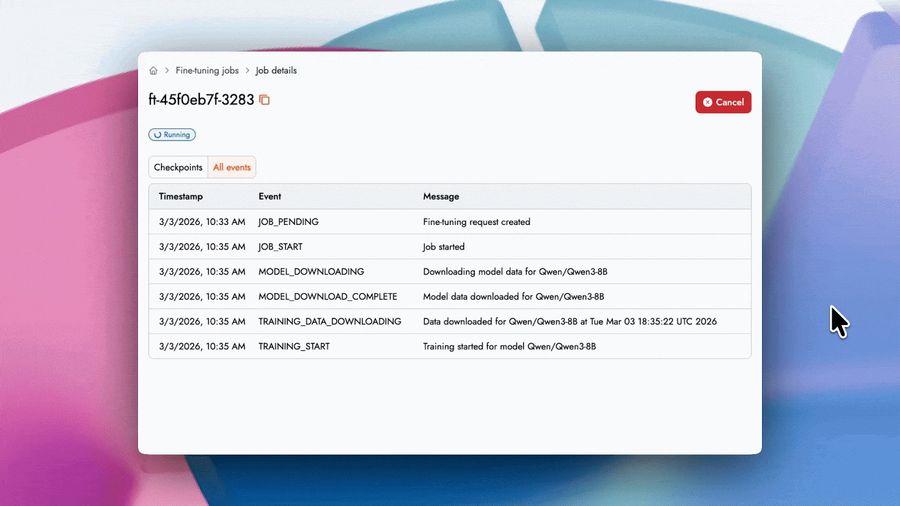
Оценка времени: live-прогресс-бар с динамически обновляемым ETA.
Начало работы
Cookbook: