
Фреймворк YOLO («You Only Look Once») долгое время служил эталоном детекции объектов в реальном времени. Однако традиционные итерации (от YOLOv1 до YOLO11) ограничены задержками и чувствительностью к гиперпараметрам постобработки Non-Maximum Suppression (NMS — алгоритм, удаляющий дублирующиеся рамки вокруг одного объекта). В этой статье разбирается YOLOv26 — архитектура, которая отказывается от NMS в пользу нативного end-to-end обучения. Рассматриваем ключевые инновации: оптимизатор MuSGD для стабилизации лёгких backbone’ов (базовых сетей-экстракторов признаков), STAL для назначения меток с учётом мелких объектов и ProgLoss для динамической супервизии.
Статья представляет аналитический обзор YOLOv26 на основе публичной документации, бенчмарков и технических описаний от Ultralytics. Официальная документация: https://docs.ultralytics.com/models/yolo26/
1 Введение
Компьютерное зрение прошло путь от простых методов обработки изображений до доминирования глубокого обучения. Во главе этого развития — Object Detection, фундаментальная задача идентификации и локализации объектов на изображении. В отличие от классификации, детекция требует одновременного предсказания классов и координат ограничивающих рамок (bounding boxes). Это ключевая способность для автономного вождения, робототехники, медицинского анализа и видеонаблюдения. По мере роста спроса на реалтайм-анализ индустрия сдвинулась от тяжёлых двухстадийных детекторов (типа Faster R-CNN) к эффективным одностадийным архитектурам.
1.1 Наследие Ultralytics
Ultralytics стала определяющей силой в реалтайм-детекции. Стандартизировав архитектуру YOLO, команда последовательно расширяла границы эффективности. YOLOv5 и YOLOv8 задали отраслевой стандарт, объединив Cross-Stage Partial (CSP) backbone’ы с удобными пайплайнами деплоя. Эти модели демократизировали AI — сложные задачи детекции заработали на edge-устройствах (периферийных устройствах с ограниченными ресурсами). Но даже эти SOTA-модели зависели от NMS-постобработки — последовательного шага, который вносит непредсказуемые задержки в плотных сценах.
1.2 YOLOv26: самая быстрая модель детекции объектов
Выпущенная в сентябре 2025 года, YOLOv26 устанавливает новый рубеж в реалтайм-детекции. Команда Ultralytics опубликовала бенчмарки, сравнивающие YOLOv26 с предшественниками (YOLOv5–YOLO11) и конкурентами — RTMDet, DAMO-YOLO, PP-YOLOE+.
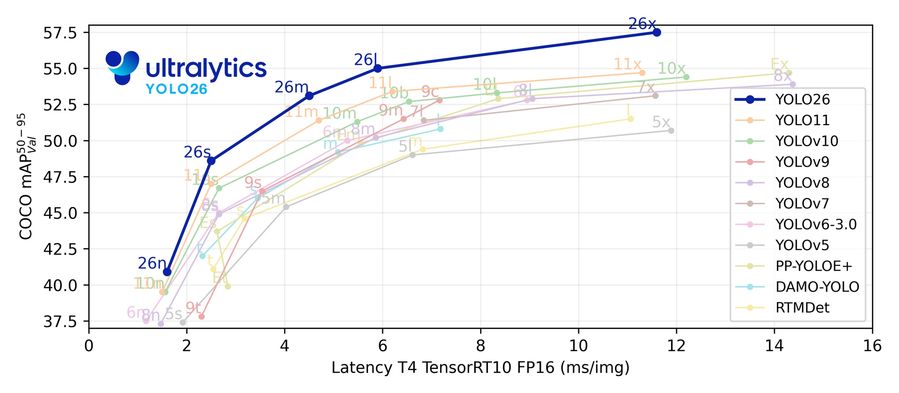
Рисунок 1: Баланс скорости и точности на COCO val2017. Mean Average Precision (mAP 50-95) отложен против задержки инференса (мс/изображение) на NVIDIA T4 (TensorRT10, FP16). Синяя кривая — YOLOv26, образующая новый Pareto-фронт (границу оптимальных решений): более высокая точность при равной или меньшей задержке по сравнению со всеми предыдущими итерациями и конкурентами.
1.2.1 Анализ заявленных показателей
- Pareto-доминирование: кривая YOLOv26 расположена строго выше и левее всех остальных моделей. При любом бюджете задержки архитектура выдаёт бóльшую точность. При любой целевой точности — обеспечивает самую быструю инференцию.
- Масштабирование от Nano до Extra-Large: доминирование на всех масштабах. Nano-вариант (26n) достигает >40 mAP при задержке ≈1.5 мс. На верхнем конце extra-large модель (26x) поднимает точность до ≈57.5 mAP при реалтайм-скорости (≈11.5 мс), обгоняя YOLO11x и RTMDet.
Эмпирические данные подтверждают: удаление NMS и переход к end-to-end архитектуре реально разблокировали прирост пропускной способности, закрепив за YOLOv26 статус самого быстрого детектора на сегодняшний день.
2 Эволюция YOLO
Семейство YOLO прошло десятилетие быстрой архитектурной эволюции — от жёсткой сеточной детекции к гибкому мультитасковому интеллекту. Прогресс делится на три эпохи: Фундаментальная (v1–v3), Коммуникативного расширения (v4–v7) и Современная унифицированная (v8–v26).
2.1 Фундаментальная эпоха (2015–2018)
Оригинальный YOLOv1 переосмыслил детекцию как единую задачу регрессии, пожертвовав частью локализации ради скорости. YOLOv2 добавил anchor boxes (заранее заданные шаблоны рамок), YOLOv3 — мультимасштабные feature pyramids (многоуровневые карты признаков) для решения проблемы мелких объектов, утвердив Darknet как отраслевой стандарт. Эпоха характеризовалась переходом от полносвязных слоёв к fully convolutional архитектурам.
2.2 Эпоха коммуникативного расширения (2020–2022)
Период диверсификации линейки. YOLOv4 и YOLOv5 внедрили CSP-связи и продвинутые аугментации. YOLOv6 и YOLOv7 добавили re-parameterization (технику слияния слоёв для ускорения инференса) и E-ELAN для максимизации утилизации конкретного железа. Модели сокращали разрыв между академией и индустриальным деплоем.
2.3 Современная унифицированная эпоха (2023–настоящее время)
Начиная с YOLOv8, фокус сместился к anchor-free (работающим без шаблонных рамок) декуплированным головкам. YOLOv9 добавил Programmable Gradient Information (PGI), YOLOv10 — dual-label assignment для NMS-free тренировки. YOLO11 оптимизировал C3k2 backbone для мультитасковой эффективности, YOLOv12 интегрировал Area Attention (A²) для transformer-level контекста на скоростях CNN, YOLOv13 использовал гиперграфовое пространственное моделирование.
Ключевая проблема этой эпохи — «Export Gap»: падение производительности при переносе модели с GPU-тренировки на edge-железо (NPU/CPU). Сложные операторы типа Distribution Focal Loss (DFL — функция потерь, моделирующая координаты рамок как распределение), точные на бумаге, создают узкие места на целочисленном железе.
YOLOv26 — кульминация линии, отказывающаяся от нарастания сложности в пользу edge-латентности. Убрав вычислительную нагрузку DFL и перейдя к нативной one-to-one prediction head (головке, предсказывающей одну рамку на объект), модель достигает детерминированного времени инференса.
Таблица 1: Архитектурная эволюция семейства YOLO (v1–v26)
| Модель | Backbone | Neck | Head | Задачи | Anchors | Loss | Пост-обработка | Ключевые инновации |
|---|---|---|---|---|---|---|---|---|
| YOLOv1 (2015) | Darknet-24 | Нет | Coupled | Детекция | Нет | SSE (Sum) | NMS | Единый одностадийный фреймворк регрессии для реалтайм-детекции. |
| YOLOv2 (2016) | Darknet-19 | Pass-through | Coupled | Детекция | Да | SSE | NMS | Anchor boxes, batch normalization, passthrough-слой для улучшения recall мелких объектов. |
| YOLOv3 (2018) | Darknet-53 | Multi-Scale | Coupled | Детекция | Да | BCE + SSE | NMS | Мультимасштабное предсказание фич для локализации мелких объектов. |
| YOLOv4 (2020) | CSPDarknet53 | PAN | Coupled | Детекция | Да | CIoU + BCE | NMS | CSP-аугментация для оптимального баланса скорость–точность. |
| YOLOv5 (2020) | CSPDarknet | PAN | Coupled | Детекция | Да | GIoU/CIoU + BCE | NMS | Модульный PyTorch-дизайн с автооптимизацией anchors для удобного деплоя. |
| YOLOv6 (2022) | EfficientRep | PAN | Decoupled | Детекция | Да | SIoU / Varifocal | NMS | Re-parameterized свёртки для high-throughput промышленного инференса. |
| YOLOv7 (2022) | E-ELAN | CSP-PAN | Lead + Auxiliary | Детекция | Да | CIoU + BCE | NMS | E-ELAN, deep supervision и OTA-assignment для точности и эффективности. |
| YOLOv8 (2023) | C2f | PAN | Decoupled | Детекция, сегментация, поза | Нет | BCE + CIoU + DFL | NMS | Anchor-free декуплированная головка — единый мультитасковый фреймворк. |
| YOLOv9 (2024) | GELAN | PAN | Decoupled | Детекция | Нет | BCE + CIoU + DFL | NMS | PGI и GELAN для преодоления информационного узкого места в глубоких сетях. |
| YOLOv10 (2024) | GELAN | PAN | Decoupled | Детекция | Нет | BCE + CIoU + DFL | NMS-Free | NMS-free инференс через Dual-Label Assignment; Partial Self-Attention в GELAN. |
| YOLO11 (2024) | C3k2 | PAN | Decoupled | Детекция, сегментация, поза | Нет | BCE + CIoU + DFL | NMS | C2PSA-рефинмент фич; стандартный NMS для постобработки. |
| YOLOv12 (2025) | Flash + Area Attention | PAN | Decoupled | Детекция, сегментация | Нет | BCE + CIoU + DFL | NMS | Area Attention (A²) для long-range зависимостей при CNN-скорости. |
| YOLOv13 (2025) | Hyper-Net | PAN | Decoupled | Детекция, сегментация, поза | Нет | BCE + CIoU + DFL | NMS | Сторонний релиз iMoonLab; гиперграфовое моделирование для сложных сцен. |
| YOLOv26 (2026) | CSP-Muon (Edge-Optimized CNN) | PAN | Decoupled (1-to-1) | Детекция, сегментация, поза, OBB | Нет | STAL + ProgLoss | NMS-Free | Edge-оптимизированный, DFL-free с one-to-one assignment; нативная NMS-free головка; оптимизирован для CPU и Edge-экспорта. |
3 Архитектура и методология YOLOv26
Философия YOLOv26 отходит от тренда наращивания параметрической сложности (v10, v11) в пользу вычислительной плотности и детерминированной латентности. Это достигается реструктуризацией пайплайна инференса и переносом оптимизационных стратегий из мира LLM — в частности, MuSGD.
3.1 Нативная End-to-End NMS-Free архитектура
Традиционные детекторы используют NMS как отдельный шаг постобработки для фильтрации дублирующихся рамок. NMS итеративно выбирает предложение с максимальной уверенностью (S_max) и подавляет все пересекающиеся рамки (b_i), чей IoU (Intersection over Union — мера перекрытия двух рамок) с S_max превышает порог (N_t):
s_i = { s_i, если IoU(M, b_i) < N_t; 0, если IoU(M, b_i) ≥ N_t }
Эта эвристика принципиально последовательна — латентность зависит от плотности сцены (количества обнаруженных объектов).
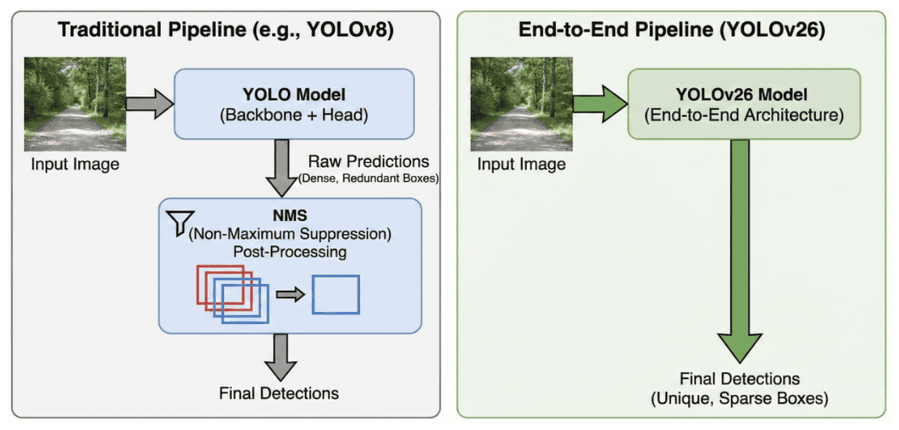
Рисунок 2: Сравнение пайплайнов инференса. (Слева) Традиционный пайплайн YOLOv8 с последовательной NMS-постобработкой. (Справа) End-to-End пайплайн YOLOv26, где модель напрямую выдаёт уникальные предсказания — меньше латентности и сложности.
YOLOv26 радикально меняет пайплайн через нативную End-to-End архитектуру. Переобучив головку предсказаний на one-to-one label assignment (стратегию «один объект — одно предсказание»), модель учится выдавать одну итоговую рамку на объект уже при тренировке. NMS исключается полностью — инференс превращается из многостадийной фильтрации в детерминированное отображение входа в выход (Рисунок 2). Результат — упрощённый граф вычислений с константным временем инференса независимо от числа объектов.
Влияние на производительность: удаление NMS даёт серьёзное сокращение задержек, особенно на non-GPU железе, где последовательные операции — узкое место. Ultralytics сообщает о ~43% ускорении инференса на CPU по сравнению с NMS-базлайнами. Константное время критично для safety-critical приложений — автономного вождения, медицинского мониторинга.
3.2 Регрессионная декуплированная головка (DFL-Free)
Последние итерации YOLO (v8–v11) использовали Distribution Focal Loss (DFL) для моделирования координат рамок как распределений, а не детерминированных значений. DFL повышает точность локализации, но вносит overhead: Softmax по дискретизированным бинам для каждой координаты. На edge-железе (NPU, DSP) эти Softmax-слои трудно квантизовать и они становятся основным узким местом.
Оценка одной координаты y через DFL требует интегрирования по дискретному распределению (обычно 16 бинов):
ŷ_DFL = Σᵢ i · Softmax(wᵢ) = Σᵢ i · e^{wᵢ} / Σⱼ e^{wⱼ}
Операция включает повторные вычисления экспонент и делений — дорого на целочисленных edge-акселераторах.
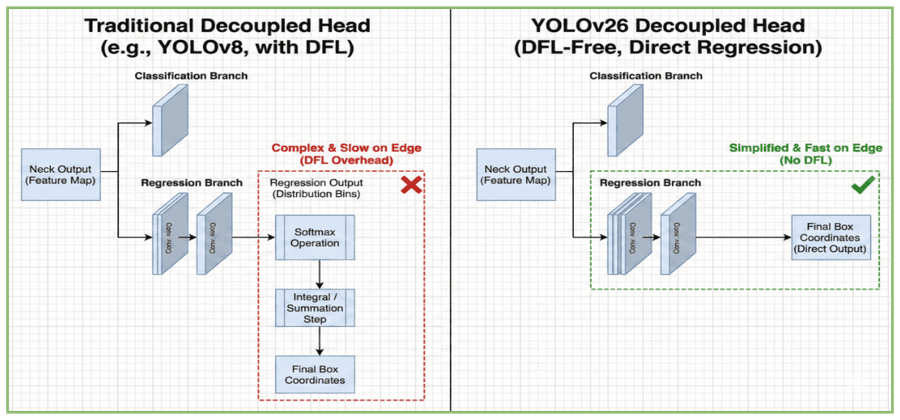
Рисунок 3: Сравнение головок предсказаний. (Слева) Традиционная декуплированная головка с DFL. (Справа) Головка YOLOv26 со стратегией Direct Regression — без overhead DFL для оптимизированного edge-инференса.
YOLOv26 возвращается к Direct Regression, полностью убирая этот модуль (Рисунок 3). Мотивация — тот самый «Export Gap»: разрыв между теоретическими FLOPs и реальной скоростью на железе. Декодинг упрощается до прямого линейного отображения:
ŷ_v26 = ℱ_reg(x) ∈ ℝ
Чтобы сохранить точность без DFL, YOLOv26 использует доработанную декуплированную головку по мотивам YOLOX. Головка разделяет экстракцию фич на две ветви:
Head(x) = { ℱ_cls(x), ℱ_reg(x) }
ℱ_cls предсказывает вероятности классов, ℱ_reg — параметры рамок напрямую. Разделение гарантирует, что удаление DFL не ухудшает классификацию. Регрессионная ветвь оптимизируется через STAL и ProgLoss для компенсации потерянной точности локализации.
3.3 Продвинутая динамика тренировки: MuSGD, STAL и ProgLoss
Удаление DFL и переход к end-to-end архитектуре требуют более надёжной стратегии тренировки для предотвращения коллапса градиентов. YOLOv26 решает это триадой оптимизационных инноваций.
3.3.1 Оптимизатор MuSGD
Для стабильной сходимости YOLOv26 внедряет MuSGD (Momentum-Unified Stochastic Gradient Descent) — гибридный оптимизатор, объединяющий стандартный SGD с Muon. Вдохновлён тренировочной динамикой LLM Kimi K2 от Moonshot AI, MuSGD — стратегический перенос оптимизации из NLP в computer vision.
Ключевая инновация — интеграция Muon. В отличие от поэлементных оптимизаторов (AdamW), Muon выполняет ортогонализацию матриц. Он обновляет весовую матрицу так, чтобы она была ортогональна текущему состоянию. Это максимизирует эффективность обновлений и контролирует спектральную норму.
MuSGD комбинирует ортогональное масштабирование со стабильностью классического SGD. Сначала определяется стандартный momentum-буфер:
v_{t+1} = β · v_t + g_t
Затем финальное обновление весов модифицируется внедрением Newton-Schulz ортогонализации в траекторию:
θ_{t+1} = θ_t − η · (α · v_{t+1} + (1 − α) · NewtonSchulz(g_t))
NewtonSchulz(g_t) эффективно «нормализует» градиентную матрицу через итеративный процесс уточнения. Гибридный подход смягчает дисперсию чистого SGD и избегает нестабильности чистых ортогональных обновлений в ранних эпохах.
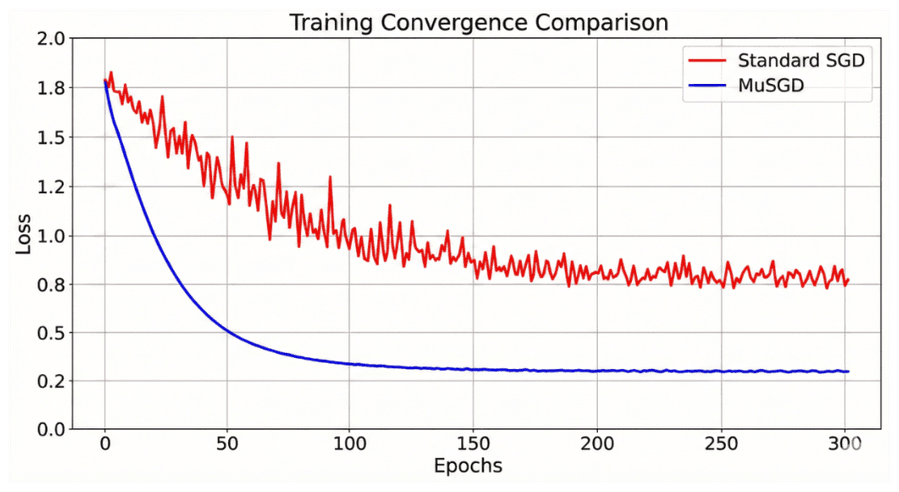
Рисунок 4: Концептуальная визуализация динамики оптимизации. MuSGD (синий) снижает дисперсию градиентов стандартного SGD (красный), позволяя более крутую кривую обучения без warm-up.
MuSGD позволяет упрощённому end-to-end backbone’у учить робастные фичи без сложных warm-up расписаний, сокращая общее время тренировки.
3.3.2 Small-Target-Aware Label Assignment (STAL)
Для решения проблемы «исчезновения мелких объектов» в edge-оптимизированных моделях YOLOv26 реализует STAL. Стандартные стратегии назначения опираются на фиксированный IoU-порог (τ = 0.5). Для крупных объектов это работает. Но для мелких (занимающих <1% площади изображения) даже хорошо центрированные anchors дают математически низкий IoU из-за пиксельной дискретизации.
STAL заменяет статический порог динамической переменной, адаптирующейся к масштабу объекта:
τ_dynamic = τ_base · (1 − α · e^{−Area_obj / Area_img})
Для крошечного объекта экспоненциальное слагаемое приближается к 1, значительно снижая τ_dynamic. Anchors с низким физическим пересечением всё равно назначаются позитивными семплами. Это работает как «лупа» для сигналов супервизии. Мелкие или окклюдированные объекты (дроны, медсканы) получают достаточный градиентный вклад.
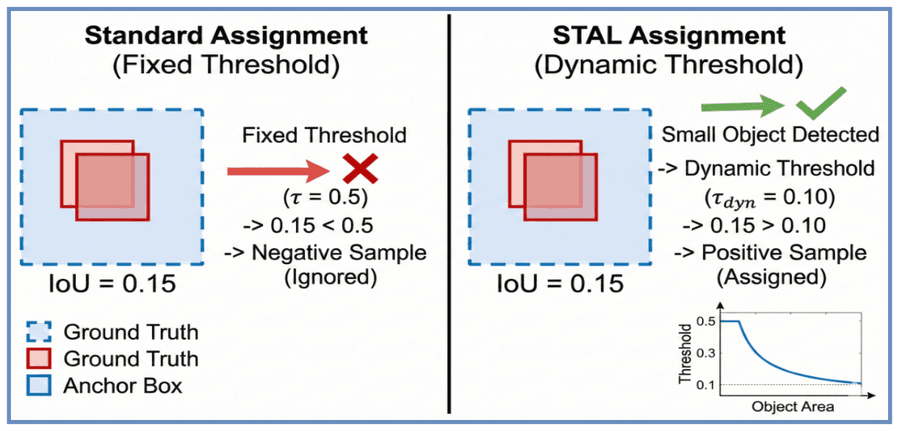
Рисунок 5: Механизм STAL. (Слева) Стандартное назначение игнорирует мелкий объект — его IoU (0.15) ниже фиксированного порога (0.5). (Справа) STAL определяет малое соотношение площадей и динамически снижает порог до 0.10, успешно назначая anchor позитивным семплом.
3.3.3 Progressive Loss Balancing (ProgLoss)
Для стабилизации тренировки end-to-end архитектуры YOLOv26 применяет ProgLoss — динамическое взвешивание потерь. В стандартных детекторах соотношение между классификационной потерей (L_cls) и потерей регрессии рамок (L_box) фиксировано. Для end-to-end обучения это субоптимально. Сеть должна одновременно учить дискриминацию фич и точную локализацию без геометрических подсказок anchor-приоров.
ProgLoss вводит зависящий от времени коэффициент модуляции (λ_t). Общая функция потерь эволюционирует по эпохам:
L_total(t) = λ_t · L_cls + (1 − λ_t) · L_box
λ_t следует монотонно убывающему расписанию, например cosine decay.
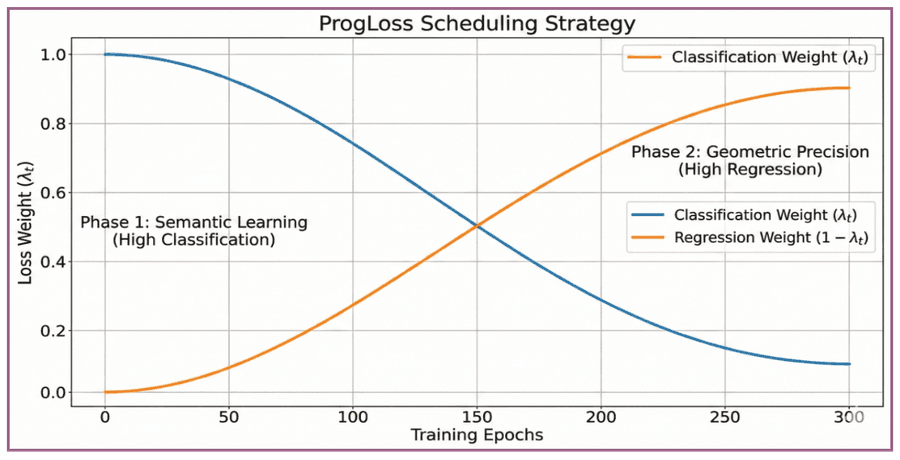
Рисунок 6: Концептуальная визуализация ProgLoss. Вес классификации (λ_t, синий) доминирует в ранней фазе «семантического обучения» для стабилизации; вес регрессии (оранжевый) прогрессивно растёт, приоритизируя «геометрическую точность» в финальных эпохах.
- Ранняя фаза (высокий λ_t): градиент доминируется L_cls — приоритет семантических фич, стабилизация backbone и фиксация существования объектов.
- Поздняя фаза (низкий λ_t): фокус смещается на L_box — файнтюн геометрических границ. Это предотвращает доминирование «лёгких негативов» на финальных этапах, обеспечивая высокую точность локализации без DFL.
4 Мультитасковые возможности YOLOv26
YOLOv26 — унифицированное семейство моделей с end-to-end поддержкой широкого спектра CV-задач. Каждый вариант, от Nano (n) до Extra-Large (x), нативно совместим со специализированными головками для разных типов пространственного и семантического вывода.

Рисунок 7: Унифицированный мультитасковый инференс YOLOv26: (a) детекция, (b) сегментация, (c) классификация, (d) оценка позы, (e) детекция повёрнутых рамок (OBB).
4.1 Детекция объектов
Основная задача — идентификация и локализация объектов через axis-aligned bounding boxes (Рисунок 7a). YOLOv26 оптимизирует пайплайн за счёт нативной end-to-end архитектуры: one-to-one assignment даёт 43% сокращение CPU-латентности. Удаление недифференцируемого NMS делает процесс полностью детерминированным — критично для надёжности методов объяснимости и для safety-critical сценариев.
Детекция мелких фич дополнительно усилена STAL. В задачах типа анализа микроскопических аномалий STAL предотвращает «vanishing gradient» (затухание градиента) для объектов, занимающих менее 1% площади изображения.
4.2 Instance Segmentation
Сегментация в YOLOv26 — сдвиг от региональной локализации к попиксельной классификации (Рисунок 7b). Интеграция mask-prediction ветви рядом с декуплированной головкой обеспечивает точную экстракцию контуров отдельных объектов.
Нововведение YOLOv26-seg — Boundary-Aware Supervision, поддерживаемая ProgLoss. Поскольку модель DFL-free, она избегает ошибок дискретизации, размывающих границы на edge-железе. Поздняя регрессионная фаза ProgLoss работает как «полировщик контуров», сохраняя резкость масок даже для мелких и перекрывающихся объектов. MuSGD обеспечивает более высокое разрешение фич при меньшем числе параметров. Высокоточная сегментация становится доступной не только на мощных GPU, но и на edge-устройствах в реальном времени.
4.3 Классификация изображений
Классификация в экосистеме YOLOv26 — самая вычислительно лёгкая задача, обходящаяся без пространственной регрессии и генерации масок (Рисунок 7c). Головка использует Global Average Pooling (GAP) для сжатия feature maps из backbone в единый вектор с последующим отображением в категориальные вероятности.
YOLOv26-cls использует оптимизированный CSP-backbone для минимальной латентности — идеально для первичной категоризации крупномасштабных медицинских или экологических датасетов. ProgLoss обеспечивает стабильную сходимость на сложных мультиклассовых данных: ранний фокус на семантике создаёт робастные глобальные представления, менее чувствительные к пространственному шуму.
4.4 Оценка позы
Оценка позы в YOLOv26 расширяет пространственный вывод до локализации 17 анатомических ключевых точек (Рисунок 7d). Задача трекает ориентацию суставов, выдавая триплет (x_i, y_i, v_i) для каждой keypoint.
Точность измеряется через Object Keypoint Similarity (OKS), нормализующий евклидово расстояние d_i относительно масштаба объекта s и пер-суставной константы затухания κ_i:
OKS = Σᵢ exp(−d_i² / 2s²κ_i²) · δ(v_i > 0) / Σᵢ δ(v_i > 0)
В отсутствие DFL YOLOv26-pose использует Residual Log-Likelihood Estimation (RLE) — моделирование пространственной неопределённости вместо фиксированного распределения. Это позволяет модели рассуждать через окклюзии. В комбинации с MuSGD обеспечивается высокоточная регрессия ключевых точек с детерминированной латентностью на edge.
4.5 Детекция повёрнутых объектов (OBB)
OBB в YOLOv26 добавляет ротационный параметр (θ) для точной локализации наклонённых целей (Рисунок 7e). Формат нормализованного xywhr устраняет фоновый шум, типичный для axis-aligned рамок в аэро- и индустриальных задачах. Для разрешения разрывов в угловой регрессии применяется специализированный Angle Loss, поддерживающий геометрическую консистентность даже для близких к квадрату объектов.
Задача использует Direct Regression и MuSGD для высокой угловой точности без overhead DFL. NMS-free головка обеспечивает детерминированную латентность в плотных средах — например, в портах. Результат — 43% ускорение по сравнению с традиционными ротационными NMS-базлайнами.
4.6 Open-Vocabulary детекция и сегментация (YOLOE-26)
YOLOE-26 — значительная эволюция линейки, интегрирующая высокопроизводительную архитектуру YOLOv26 с open-vocabulary возможностями (детекцией классов, не виденных при обучении). Выравнивание визуальных фич с лингвистическими эмбеддингами позволяет детектировать и сегментировать произвольные классы объектов в реальном времени, снимая ограничения фиксированных категорий тренировки.
Фреймворк поддерживает три режима инференса: текстовые промпты («найди красную кружку»), визуальные промпты через референсные изображения для one-shot распознавания и prompt-free режим для zero-shot инференса.
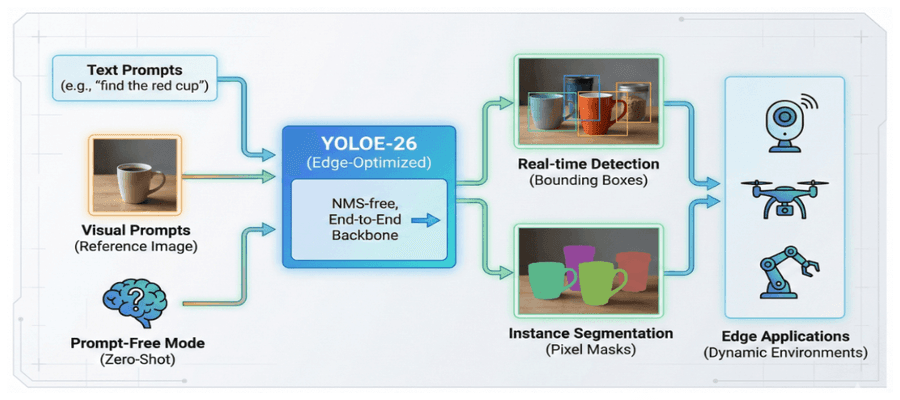
Рисунок 8: Концептуальный обзор open-vocabulary архитектуры YOLOE-26 — мультимодальная обработка входов для реалтайм edge-детекции и сегментации.
YOLOE-26 строится на нативном NMS-free end-to-end дизайне YOLOv26, исключающем эвристическую постобработку. Это даёт быстрый open-world инференс с минимальной латентностью — мощное решение для edge-приложений в средах с широким и эволюционирующим словарём объектов.
5 Последствия для Edge AI: преодоление «Export Gap»
«Export Gap» — устойчивая проблема современной детекции: разрыв между теоретической производительностью на GPU и реальной латентностью на edge-железе.
5.1 Узкое место латентности в традиционных моделях
SOTA-модели от YOLOv8 до YOLOv13 активно использовали DFL для максимизации mAP. Математически точно, DFL требует сложных Softmax-операций по дискретизированным бинам. На серверных GPU это незаметно. Но на целочисленном железе (NPU мобильных устройств, DSP дронов) Softmax-слои трудно квантизовать и они становятся главным узким местом. Модель, выглядящая эффективно в статье, страдает от серьёзной деградации пропускной способности при экспорте на встроенные системы.
5.2 Детерминированный инференс через Direct Regression
YOLOv26 решает проблему возвратом к Direct Regression, явно убирая вычислительную нагрузку DFL. Декуплируя обучение репрезентаций от сложной постобработки, архитектура гарантирует: инференс-граф состоит исключительно из стандартных свёрточных и линейных операций. Это обеспечивает детерминированную латентность — время инференса постоянно при любой сложности сцены и плотности объектов. Предсказуемость критична для safety-critical edge-приложений, где нарушение таймингов ведёт к катастрофическим последствиям.
6 Перспективы развития
Несмотря на новый бенчмарк, остаются направления для исследований на стыке edge-эффективности и когнитивного интеллекта.
Встроенная объяснимость: сейчас «чёрный ящик» детекторов вскрывается пост-hoc методами типа Grad-CAM или SHAP. Перспективное направление — Inherent Explainability (встроенная в модель объяснимость), когда головка выдаёт не только рамку и класс, но и карту обоснований или текстовое объяснение («Классифицировано как опухоль из-за неровной текстуры границы»). Встроенная интерпретируемость в end-to-end пайплайн — трансформация для медицинской диагностики и автономной обороны.
Единое пространственно-временное восприятие: NMS-free детерминированная природа YOLOv26 уникально подходит для видеоаналитики. Традиционные детекторы мерцают в видео из-за произвольного выбора разных рамок NMS по кадрам. Будущие итерации могли бы расширить backbone для нативной спатиотемпоральной (объединяющей пространственную и временную информацию) детекции — трекинг и распознавание действий («человек бежит») за один прямой проход, без отдельных алгоритмов типа DeepSORT.
Test-Time Adaptation на edge: статичность обученных моделей — ограничение в динамичных средах. Test-Time Adaptation (адаптация модели во время работы, без дообучения) позволила бы обновлять batch normalization статистики или легковесные adapter-слои прямо на edge-устройстве. Дрон или медприбор мог бы «акклиматизироваться» к новым условиям освещения или профилям шума сенсоров в реальном времени без полного ретрейна на сервере.
7 Заключение
YOLOv26 переопределяет парадигму реалтайм-детекции, отказываясь от NMS в пользу нативного end-to-end обучения. Переход к NMS-Free фреймворку, поддержанный оптимизатором MuSGD и ProgLoss, решает исторический компромисс между латентностью и точностью при значительном ускорении на CPU. Переход к Direct Regression головке закрывает «Export Gap», обеспечивая детерминированную латентность на устройствах с ограниченными ресурсами. Новый Pareto-фронт в официальных бенчмарках подтверждает: YOLOv26 обходит предшественников и конкурентов, сигнализируя о фундаментальном сдвиге к полностью обучаемым пайплайнам, ориентированным на конкретное железо — необходимой основе для следующего поколения safety-critical Edge AI.