Анализ множеств
Set Analysis или Анализ множеств - ключевая функциональность, которой нужно которой нужно овладеть для эффективного использования платформы Qlik. Применяется анализ множеств в вы�ражениях агрегирования в визуальном слое и решает 2 задачи:
- Позволяет «зашить» фильтры в формулу;
- Позволяет настроить реакцию выражения на выборки.
Простая агрегирующая формула, которая реагирует на любые отборы в фильтрах:
Sum(Sales)
Анализ множеств пришется в фигурных скобках внутри агрегирующий функции, перед полями.
Sum({-->Анализ множеств <-->} Sales)
Синтаксис анализа множеств имеет 2 уровня:
- идентификаторы множеств
- модификаторы множеств.
Идентификаторы множеств
Основной смысл использования идентификаторов множеств — создание сложных условий для выборок за счет функционала взаимодействия множеств.
Идентификаторы множеств — это условные обозначения наборов фильтров, без возможности их тонкой настройки. Идентификаторы бывают трех видов:
- Системные идентификаторы
- $ — текущая выборка. Это множество подразумевается по умолчанию
- 1 — все данные приложения. Формула, в которой используется идентифика�тор множества 1, например sum(1 Sales), не будет реагировать ни на какие фильтры.
- $1 (2,3,…n) — предыдущее состояние фильтров стандартной выборки, предпредыдущее состояние и т.д.
-
В качестве идентификаторов множества можно использовать альтернативные состояния. Как вы состояние назовете, такой у него и идентификатор.
-
Текущие фильтры можно сохранить как закладку. Название закладки также можно использовать как идентификатор множества.
:::
Если идентификатор множеств состоит из нескольких слов, то надо писать его в одинарных кавычках.
:::
Если откроете информацию о созданной закладке, то увидите синтаксис анализа множеств, который в ней сохранен. Сохраните закладку с некоторыми фильтрами, а потом используйте ее как идентификатор множества.
Закладки как идентификатор множеств в реальных проектах используется крайне редко.
В качестве идентификаторов обычно используют альтернативные состояния, чтобы дать пользователю универсальный функционал выборок — когда пользователь может использовать любые наборы фильтров и взаимодействий между ними.
Модификаторы множеств
Модификатор множества проще всего описать, как фильтры, вшитые в формулу. В отличие от идентификаторов, которые должны создаваться заранее (закладки), и могут содержать динамические выборки (альтернативные состояния).
Модификаторы представляют собой значения отфильтрованных полей, прописанные прямо в формуле. Выглядит это примерно так:
sum({$<CategoryName={'Мужская одержда'}, OrderYear={2018}>} Sales)
Модификаторы пишутся в треугольных стрелках(скобках), рядом с идентификаторами. Модификаторы как бы вносят уточнения в идентификаторы.
Например:
sum({1< CategoryName={'Мужская одежда'} >} Sales)
выражение значит, что берутся все данные приложения (идентификатор 1), но при этом остаются только данные, отфильтрованные по полю CategoryName, по значению Мужская одежда.
Если модификатор применяется к выборке по умолчанию, то идентификатор можно не указывать или указать $, если вам так больше нравится, т.е. формулы будут работать одинаково:
sum({$<CategoryName={'Мужская одежда'}>} Sales)
sum({<CategoryName={'Мужская одежда'}>} Sales)s
Модификаторы множеств довольно часто используются чтобы ограничить расчет показателя по заранее заданным значениям полей. Например, сделать формулу для продаж только текущего и прошлого года, а потом сравнить их между собой на дашборде в визуалищации KPI.
Если в модификаторе нужно указать несколько значений для одного поля, это делается через запятую, внутри фигурных скобок:
sum({<CategoryName={'Мужская одежда', 'Мужская обувь' }>} Sales)
Если значение в модификаторе простое (одно слово или число), его нужно писать без кавычек. Иначе, значение нужно помещать в одинарные кавычки.
Наборы значений модификаторов могут взаимодействовать также, как и идентификаторы множеств. Например, выражение
sum({<CategoryName={'Мужская одежда', 'Мужская обувь', 'Женская одежда'}* {'Мужская обувь', 'Женская одежда'} >}s Sales)
вернет нам сумму продаж только по Мужской обуви и Женской одежде, потому что только эти 2 значения пересекаются в обоих наборах.
Обратите внимание, что выражение перестает реагировать на фильтр по полю, которое указано в модификаторе множеств. Это работает даже если для поля не указано никаких значений, то есть формула:
sum({<CategoryName, Country, Customer >} Sales)
не будет реагировать на фильтры по полям CategoryName, Country, Customer. Этим можно пользоваться, чтобы исключить нежелательную реакцию на фильтры.
В качестве полей для модификаторов можно исопльзовать только реально существующие поля в модели данных. Создаваемые измерения в основных элементах нельзя использовать в анализе множеств.
Динамические модификаторы множеств
В качестве значений модификаторов можно использовать конструкцию $(=).Она подставляет на место любого выражения, помещенного внутрь нее, результат вычисления этого выражения.
Синтаксис поиска в модификаторах множеств
Если в модификаторе множеств взять значения в двойные кавычки, то можно использовать синтаксис поиска, как в фильтрах. А это значит, что можно использовать, например, знаки подмены символов вроде *.
sum({<CategoryName = {"*обувь"} >} Sales)
Данное выражение вернет сумму продаж по всем категориям, которые заканчиваются на слово «обувь». Т.к. знак * заменяет произвольное кол-во символов в начале фразы.
Границы диапазонов можно ограничивать с 2-х сторон, например [Бюджет]=>=2000<1000.
Так же можно использовать другие выражения в качестве условия для поиска. Если в двойных кавычках написать знак =, а после него условие с формулой, то это будет работать как фильтр по соответствующему измерению. Например,
sum({<Customer = {"=sum(Sales)>=10000"} >} Sales)
такая формула будет возвращать сумму продаж только по тем покупателям, для которых сумма продаж в текущей выборке больше или равна 10000.
На месте формул можно использовать метки мер, созраненных как основные элементы. Т.е. формула может выглядеть так:
sum({<Customer = {"=[Продажи]>=10000"} >} Sales)
Учитывая, что формулы внутри модификаторов могут иметь собственный анализ множеств, этот метод полезен, чтобы избегать конфликта синтаксиса с двойными кавычками.
Взаимодействия множеств
Между идентификаторами множеств можно использовать логические операторы взаимодействия. По сути это влияет на итоговый набор фильтров, применяющихся в выражении:
- Объединение (+): объединяет выборки из множеств;
- Исключение (-): исключает из одной выборки значения другой выборки;
- Пересечение (*): оставляет только те значения, которые пересекаются в обеих выборках;
- Исключение пересечения (/): оставляет значения, не пересекающиеся в обеих выборках.
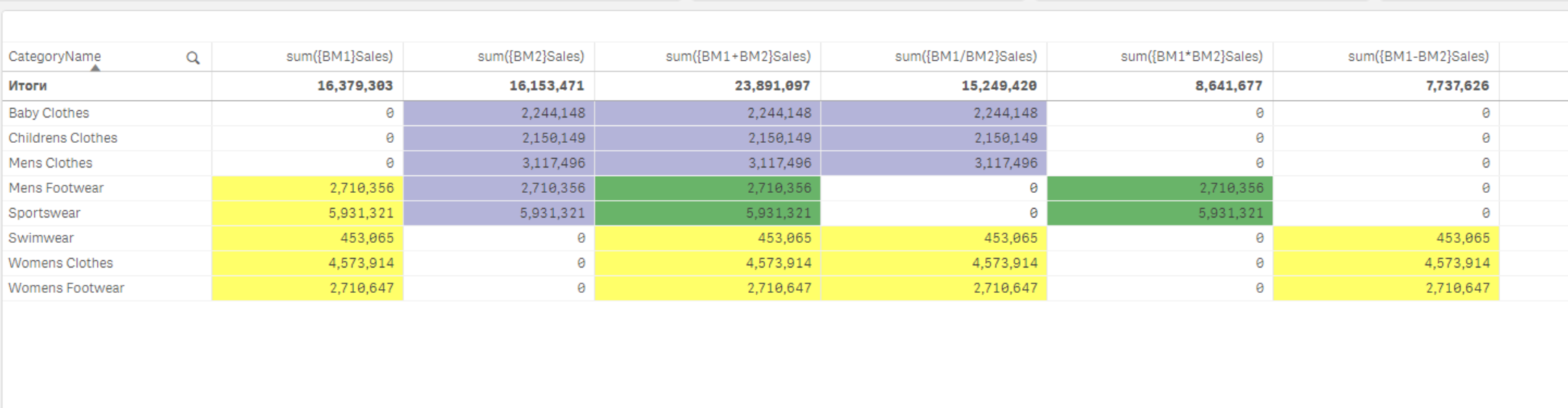
Например, пусть будут выделен�ы следующие множества:
Закладка BM1, с фильтрами CategoryName: 'Womens Clothes', 'Sportswear', 'Swimwear', 'Womens Footwear', 'Mens Footwear'
Закладка BM2, с фильтрами CategoryName: 'Mens Clothes', 'Sportswear', 'Mens Footwear', 'Childrens Clothes', 'Baby Clothes'
Обратите внимение, что в закладках есть 2 совпадающих значения: 'Sportswear' 'Mens Footwear'.
Тогда возможные взаимодействия могут выглядеть следующим образом:
По матриалам курса EvgeniyStuchalkin "Анализ множеств". Вы можете скачать приложение с полным описанием функционала анализа множеств, а также интерактивными примерами.