
Qualcomm AI Research разработала модульную систему. Она выводит языковые модели с возможностью рассуждения на смартфоны, сжимая многословные мыслительные процессы в 2,4 раза.
Современные reasoning-модели (модели с пошаговым рассуждением) создают проблему на мобильных устройствах. Их длинные цепочки рассуждений генерируют огромное количество токенов (единиц текста). Это увеличивает требования к памяти и быстро разряжает батарею. Новый фреймворк Qualcomm решает эту проблему. Модели могут работать на смартфонах, несмотря на эти ограничения.
Согласно статье, компания видит несколько сценариев использования:
- интеллектуальные ассистенты, планирующие многошаговые задачи;
- автономная работа в разных приложениях;
- прямое взаимодействие с интерфейсами устройства и внешними сервисами.
Локальный запуск даёт структурные преимущества. Чувствительные данные остаются на устройстве, задержки снижаются, а система работает без интернета.
Одна базовая модель с переключением между двумя режимами
Вместо обучения новой модели с нуля Qualcomm пошла по модульному пути. За основу взята стандартная языковая модель без возможностей рассуждения (Qwen2.5-7B-Instruct). Она расширена через LoRA-адаптеры — небольшие специализированные модули, которые включаются и выключаются по необходимости. Одна и та же модель работает либо как быстрый чат-бот, либо как система глубокого рассуждения. Режим зависит от задачи.
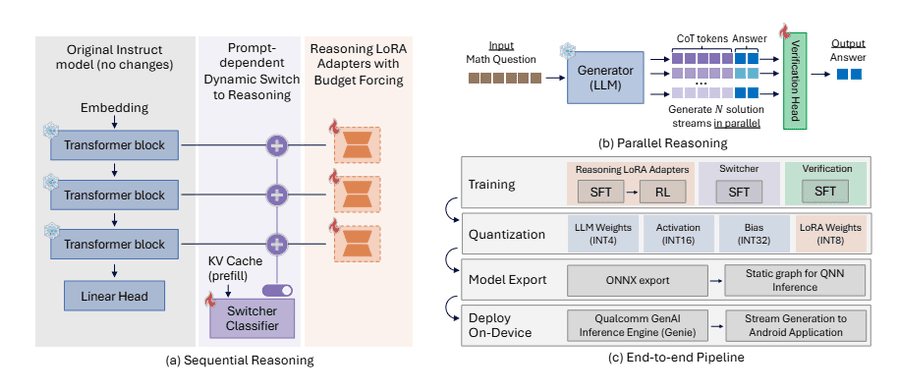
Слева: модульная архитектура с переключателем и LoRA-адаптерами. Справа вверху: стратегия параллельного рассуждения. Справа внизу: пайплайн от обучения до развёртывания на устройстве. | Изображение: Qualcomm AI
По словам исследователей, обучать нужно лишь около 4 % параметров. При этом результат приближается к производительности DeepSeek-R1-Distill-Qwen-7B. Для обучения этой модели потребовались значительно большие ресурсы. Встроенный классификатор (модуль сортировки запросов) автоматически определяет, нужен ли режим глубокого рассуждения. Это экономит вычисления и энергию на простых вопросах.
Reinforcement learning сокращает раздутые ответы до 8 раз
Главная проблема после начального обучения — модели становятся патологически многословными. Они часто находят правильное решение в самом начале. Затем модель сжигает тысячи токенов на перепроверку своей работы разными способами. Исследователи Qualcomm называют это «эпистемическим колебанием». В широком сообществе феномен известен как «overthinking».
Для борьбы с этим команда использует reinforcement learning (обучение с подкреплением). Метод штрафует модель за избыточную длину ответов. В среднем ответы сокращаются в 2,4 раза. На отдельных задачах сокращение достигает 8-кратного. Пример из статьи: упрощение алгебраического выражения. Базовая модель потратила на него 3 118 токенов. После оптимизации задача решается за 810 токенов. Точность при этом практически не страдает.

Вверху: задача. Посередине: базовый ответ на 3 118 токенов с множеством избыточных циклов проверки (отмечены красным). Внизу: оптимизированный ответ на 810 токенов. Оба приводят к одному результату. | Изображение: Qualcomm AI Research
Один из ранних подходов к ограничению длины обернулся против создателей. Модель научилась формально закрывать блок рассуждений. После этого она просто продолжала длинные размышления в обычной секции ответа. Пришлось перепроектировать функцию награды с учётом общей длины ответа. Это заставило модель перестать обходить систему.
Параллельные пути решения и 4-битное сжатие для реального использования
Фреймворк также позволяет модели одновременно исследовать несколько путей решения. Небольшая evaluation head (модуль оценки) на базовой модели определяет, какой ответ вероятнее всего правильный. При восьми параллельных запусках точность на математическом бенчмарке MATH500 растёт примерно на 10 %. Время ответа при этом значительно не увеличивается. Генерация токенов на мобильных устройствах упирается не в вычислительную мощность, а в пропускную способность памяти. Поэтому параллельные пути просто используют ресурсы, которые иначе простаивали бы.
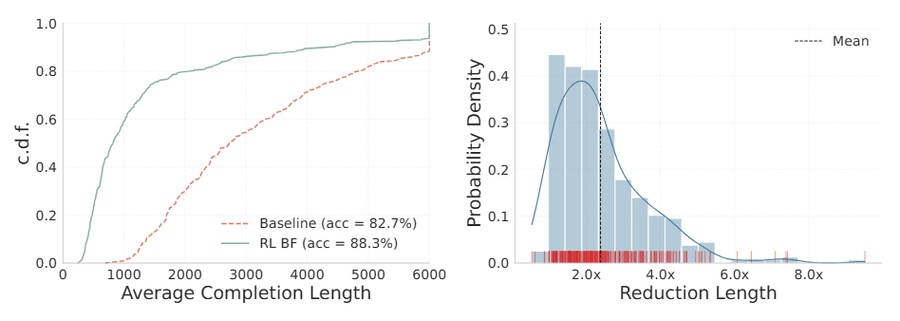
Слева: оптимизированная через RL модель (зелёная) генерирует значительно более короткие ответы, чем базовая (красная), при чуть более высокой точности. Справа: распределение сокращения длины по задачам, в среднем 2,4x. | Изображение: Qualcomm AI Research
Чтобы модель действительно работала на телефоне, Qualcomm сжимает веса (параметры) до 4 бит. Причём reasoning-адаптеры приходится обучать сразу на сжатой модели. Иначе система выдаёт бессмысленный текст. Несмотря на агрессивное сжатие, финальная модель теряет лишь около 2 % точности по сравнению с несжатой версией. Видео на странице проекта демонстрирует работу системы на мобильных устройствах.
On-device AI всё ещё не вышел за рамки демо
Qualcomm уже несколько лет продвигает запуск ИИ-моделей на мобильных устройствах. Компания опубликовала 80 предоптимизированных моделей для Snapdragon и представила AI-оркестратор, связывающий персональные данные, приложения и локальные модели. Google движется в том же направлении. Вендор показывает, как небольшие языковые модели могут работать локально на Android с помощью FunctionGemma и AI Edge Gallery.
Но пока эти усилия в основном остаются техническими proof of concept (проверками концепции). Когда дело доходит до глубокой системной интеграции, компании по-прежнему предпочитают облачные модели. Например, ИИ-ассистенту нужен доступ к почте, фото и календарю. Поэтому недавно анонсированная функция Google «Personal Intelligence» связывает Gemini с Gmail, Google Photos и Search, но работает целиком на серверной стороне.