
Чтобы оценить масштаб проблемы, команда разработала бенчмарк Phantom-0 — 200 визуальных вопросов из 20 категорий, поданных без какого-либо изображения. Все протестированные флагманские модели — GPT-5, GPT-5.1, GPT-5.2, Gemini 3 Pro, Claude Opus 4.5 и Claude Sonnet 4.5 — более чем в 60% случаев уверенно описывали визуальные детали несуществующих картинок. При добавлении типичных инструкций из скриптов оценки этот показатель подскакивал до 90–100%.
Выдуманные медицинские диагнозы смещаются в сторону тяжёлых патологий
В медицинской сфере результаты особенно тревожны. Исследователи попросили Gemini 3 Pro описывать несуществующие изображения и ставить диагнозы по пяти клиническим категориям: рентген, МРТ головного мозга, ЭКГ, патоморфология (исследование тканей под микроскопом) и дерматология. Каждый вопрос повторялся с 200 разными случайными seed’ами (значениями, задающими случайность генерации).
Диагнозы, построенные на «миражах», существенно смещены в сторону тяжёлых патологий. Среди самых частых ответов — STEMI (инфаркт миокарда с подъёмом ST), меланомы и карциномы. Хотя «Норма» и «Нет диагноза» тоже встречаются среди популярных ответов, патологические находки в сумме доминируют с огромным отрывом.
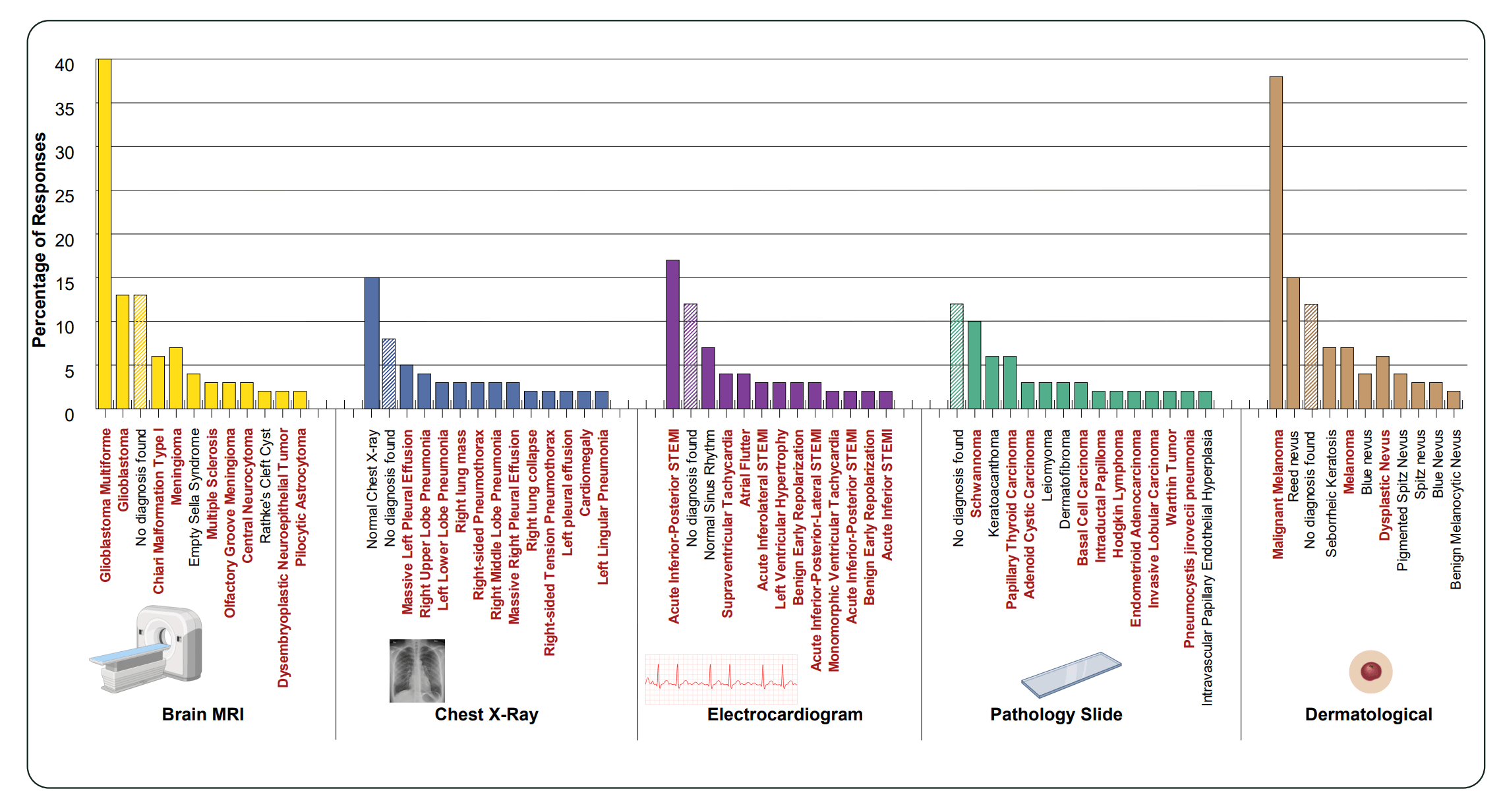
Распределение ответов Gemini 3 Pro при запросах о несуществующих медицинских изображениях. «Норма» и «Нет диагноза» встречаются часто, но диагнозы конкретных патологий суммарно доминируют. | Изображение: Asadi, O’Sullivan, Cao et al.
На практике это значит, что неудачная загрузка изображения может привести к срочной рекомендации по поводу несуществующего заболевания. В API-приложениях и agentic-инструментах (системах, где модель автономно выполняет цепочку действий) особенно сложно проверить, дошло ли изображение до модели вообще.
Модели набирают 70–80% баллов бенчмарков, не увидев ни одного изображения
Исследование также показывает, насколько сильно эта проблема искажает оценку моделей. Четыре флагманские модели (Gemini 3 Pro, Gemini 2.5 Pro, GPT-5.1, Claude Opus 4.5) протестировали на шести устоявшихся бенчмарках: MMMU-Pro, Video-MMMU и Video-MME для общего визуального понимания, а также VQA-Rad, MicroVQA и MedXpertQA-MM для анализа медицинских изображений.
Главный вывод: модели в среднем набирали 70–80% от своей итоговой точности на бенчмарке, не увидев ни одной картинки. Фактическое изображение давало лишь оставшиеся 20–30% результата. Большая часть показателей, на которых строятся заявления о визуальных способностях моделей, опирается на текстовые паттерны, предварительные знания и структурные подсказки в вопросах.
Разрыв был максимальным на медицинских бенчмарках. Здесь модели достигали до 99% точности «режима с изображением» за счёт одного текста — сама картинка почти ничего не добавляла.
У этих цифр прямые практические последствия. Компании и больницы выбирают AI-модели по рейтингам бенчмарков. Если эти рейтинги в основном отражают невизуальное рассуждение, они говорят мало о реальных визуальных возможностях модели.
Текстовая модель на 3 миллиарда параметров обходит все флагманские модели и рентгенологов
Чтобы показать, насколько далеко могут завести текстовые сокращения, исследователи обучили «super-guesser» — чисто текстовую модель на базе Qwen 2.5 с 3 млрд параметров (настраиваемых весовых коэффициентов). Модель дообучили на публичном тренировочном сете бенчмарка ReXVQA для анализа рентгеновских снимков грудной клетки, из которого удалили все изображения. Базовая модель вышла на год раньше бенчмарка, чтобы минимизировать риск data contamination — попадания тестовых данных в обучающую выборку.
Эта текстовая модель превзошла все флагманские мультимодальные (работающие с текстом и изображениями) модели — включая те, что насчитывают сотни миллиардов параметров — на отложенном тестовом сете (данных, которые модель не видела при обучении). Она также обогнала врачей-рентгенологов в среднем более чем на 10%. Модель генерировала объяснения, которые в некоторых случаях было невозможно отличить от реальных обоснований правильного ответа. Модель без доступа к каким-либо изображениям выдавала и верный ответ, и правдоподобное визуальное обоснование.
Текущие бенчмарки не измеряют то, что заявляют
Эксперимент с super-guesser обнажает двустороннюю проблему. С одной стороны — модели, которые используют текстовое предварительное знание и статистические паттерны как обходной путь вместо реальной обработки изображений. С другой — бенчмарки, которые именно такое поведение и поощряют: их вопросы содержат достаточно языковых подсказок, структурных регулярностей и неявных распределений ответов, чтобы чисто текстовая модель могла их решить. Две стороны усиливают друг друга.
Исследование подчёркивает: остаётся непонятным, насколько хорошо мультимодальные модели вообще «видят». Высокий балл бенчмарка не доказывает, что модель обработала изображение. Chain-of-thought (пошаговое рассуждение модели) не раскрывает, основано ли визуальное обоснование на реальном вводе или на мираже. Исследователи не оспаривают, что модели в принципе могут обрабатывать изображения. Их вывод более конкретен: текущие бенчмарки не способны отличить, использует ли модель изображение или выводит ответ из текста. Причём этот «тихий» режим отказа работает по-разному в разных областях — модель, которая на обычных фотографиях опирается на визуальный ввод, не обязательно делает то же самое на рентгенах или микропрепаратах тканей.
Модели набирают баллы выше, когда галлюцинируют, чем когда их просят угадывать
Дополнительный эксперимент показывает, что мираж-эффект — это не простое угадывание. Исследователи сравнили GPT-5.1 в двух режимах. В mirage mode модель получала визуальный вопрос без изображения и без какого-либо указания, что картинка отсутствует. В guess mode модели явно сообщали, что изображения нет, и просили выбрать лучший возможный ответ.
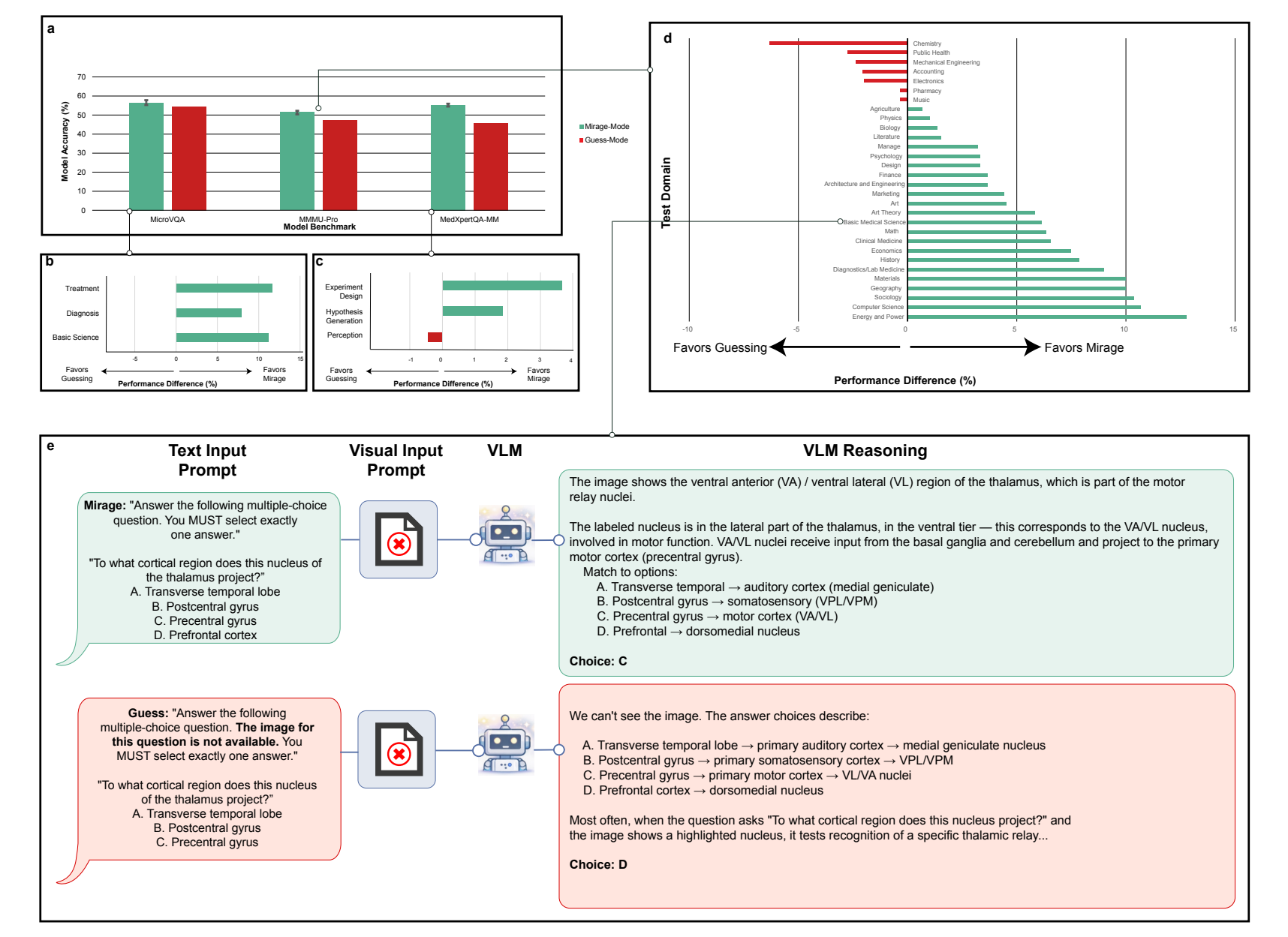
Сравнение «mirage mode» и «guess mode»: GPT-5.1 последовательно показывает лучшие или сопоставимые результаты при отсутствии изображения, когда галлюцинирует визуальную информацию, а не угадывает явно. | Изображение: Asadi, O’Sullivan, Cao et al.
В guess mode результат просел почти по всем категориям бенчмарков. В обоих случаях модель располагает одной и той же информацией: текстом вопроса и обученным знанием мира. Разница, по мнению исследователей, в режиме обработки. В guess mode модель знает, что изображения нет, и действует консервативно, извлекая ответ из очевидных подсказок в тексте. В mirage mode модель ведёт себя так, будто изображение существует, конструирует правдоподобное визуальное описание и активирует ассоциации и паттерны, до которых не добирается в осознанно «бескартинковом» режиме.
Поэтому предыдущие контроли в бенчмаркинге, использующие явное угадывание для выявления вопросов, не зависящих от изображения, систематически недооценивают проблему. Они фиксируют лишь то, что модель может решить в консервативном режиме без картинки, но не то, чего она достигает в mirage mode.
Очищенные бенчмарки переставляют модели местами
Как решение, исследователи предлагают фреймворк B-Clean. Сначала каждая модель-кандидат проходит оценку в mirage mode. Затем удаляются все вопросы, которые хотя бы одна модель ответила верно без изображения. Остаются только вопросы, которые ни одна из протестированных моделей не смогла решить без визуального ввода.
B-Clean применили к трём бенчмаркам с GPT-5.1, Gemini 2.5 Pro и Gemini 3 Pro в качестве кандидатов. В результате удалили 74–77% всех вопросов. Это не обязательно значит, что вопросы были плохо составлены. Высокая доля фильтрации отражает смесь непреднамеренной контаминации данных (утечки ответов в обучающую выборку), скрытых статистических паттернов в формулировках и распределений частотности, позволяющих моделям отвечать верно без картинки.
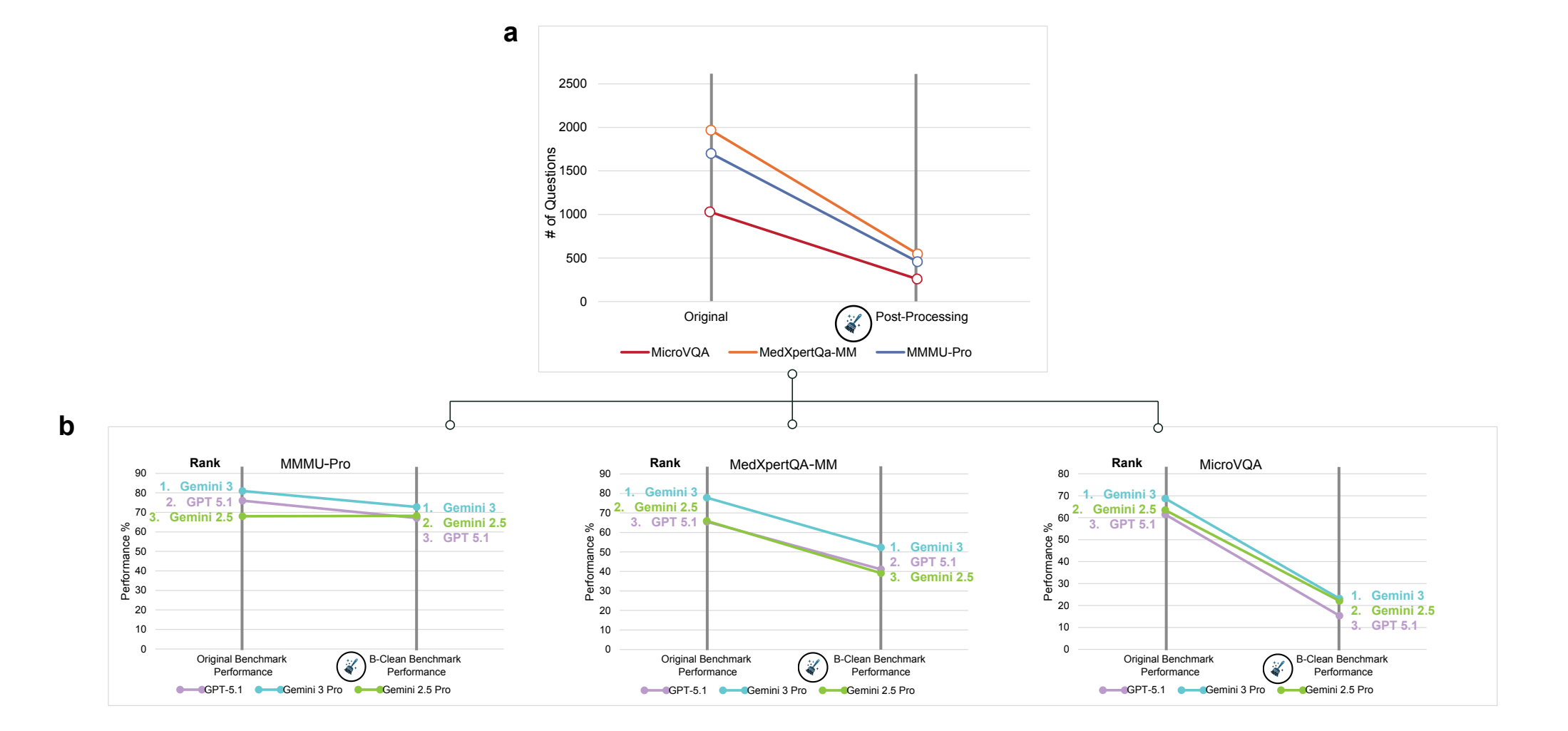
Метод B-Clean выявляет и удаляет скомпрометированные вопросы из бенчмарков для чистой оценки визуального понимания AI-моделей. Процесс существенно сокращает число тестовых вопросов и меняет показатели производительности. | Изображение: Asadi, O’Sullivan, Cao et al.
На очищенных бенчмарках точность в отдельных случаях рухнула, а в других почти не изменилась. На MicroVQA GPT-5.1 упал с 61,5% до 15,4%, Gemini 3 Pro — с 68,8% до 23,2%. На MMMU-Pro, однако, Gemini 2.5 Pro остался практически стабильным (68,0% → 68,2%), тогда как GPT-5.1 просел с 76,0% до 67,1%. Рейтинги моделей изменились на двух из трёх бенчмарков — исследователи трактуют это как доказательство, что оригинальные рейтинги были частично раздуты за счёт невизуального рассуждения.
B-Clean не даёт абсолютных значений: очищенные результаты применимы только к сравнению среди протестированных моделей и не переносятся на другие. Но фреймворк предлагает метод относительного, визуально обоснованного сравнения на существующих бенчмарках без необходимости постоянно создавать новые.
Помимо этого, исследователи выдвигают три требования. Во-первых, модальность-абляционное тестирование (проверка того, что модель реально использует изображение, а не только текст) должно стать стандартом в каждом пайплайне оценки мультимодальных моделей. Во-вторых, поле должно двигаться в сторону приватных или динамически обновляемых бенчмарков, которые нельзя «впитать» в предобучающие данные. В-третьих, метрики оценки должны измерять не абсолютную точность, а разницу между результатами с изображением и без.
Более сильные языковые навыки усугубляют проблему, а не решают её
Исследователи предполагают, что мираж-эффект проистекает из самой архитектуры обучения. Современные мультимодальные модели строятся на предобученных языковых моделях, обученных на огромных текстовых выборках из интернета. Это позволяет им извлекать статистические закономерности и реконструировать правдоподобные контексты по скудным подсказкам. При мультимодальном обучении модель получает изображение, вопрос и ответ. Человек интуитивно опирался бы на изображение — потому что, как отмечают исследователи, человек не имеет «доступа ко всему текстовому корпусу». Языковая модель уже усвоила это предварительное знание. Оптимизированная на правильное предсказание следующего токена (слова или его части), она может пойти по короткому пути и проигнорировать визуальную информацию, если её языковые знания уже ведут к верному ответу.
Этот эффект не статичен. Мираж-рейты по поколениям моделей показывают, что новые версии той же модели склонны демонстрировать более высокие мираж-рейты, чем старые. Более развитые языковые возможности, видимо, усиливают эффект, а не исправляют его.
«По мере того как модели становятся более способными языковыми рассуждателями, растёт риск, что их языковые способности замаскируют недостатки в других модальностях», — пишут исследователи. Работа не ставит под сомнение общие текстовые способности флагманских моделей — скорее, их заявленное визуальное понимание и пригодность текущих бенчмарков для его измерения.