
Новая модель Gemma 4 вышла, и она интересная. Между E4B и 26B A4B была пустота, и 12B-модель заняла её органично. Но это Google DeepMind — без архитектурного эксперимента не обошлось.
Так в чём же особенность Gemma 4 12B?
Она без энкодеров!
Термин «encoder-free» может вызывать путаницу. Современные генеративные LLM и так обычно decoder-only. Речь о другом: из модели убрали энкодеры для обработки аудио и изображений. При этом мультимодальные возможности сохранились.
Убрав энкодеры, которые отвечали за осмысление мультимодальных входов, Google DeepMind перенесли эту нагрузку на саму LLM. Все модальности теперь объединены внутри одной модели. LLM больше не ждёт, пока энкодеры обработают аудио и изображения — она начинает работать с входом и генерировать ответ раньше.
В этом гайде показано, как именно убрали vision- и audio-энкодеры и чем их заменили. Результат — 12B-модель, которая работает с аудио и изображениями без энкодеров.
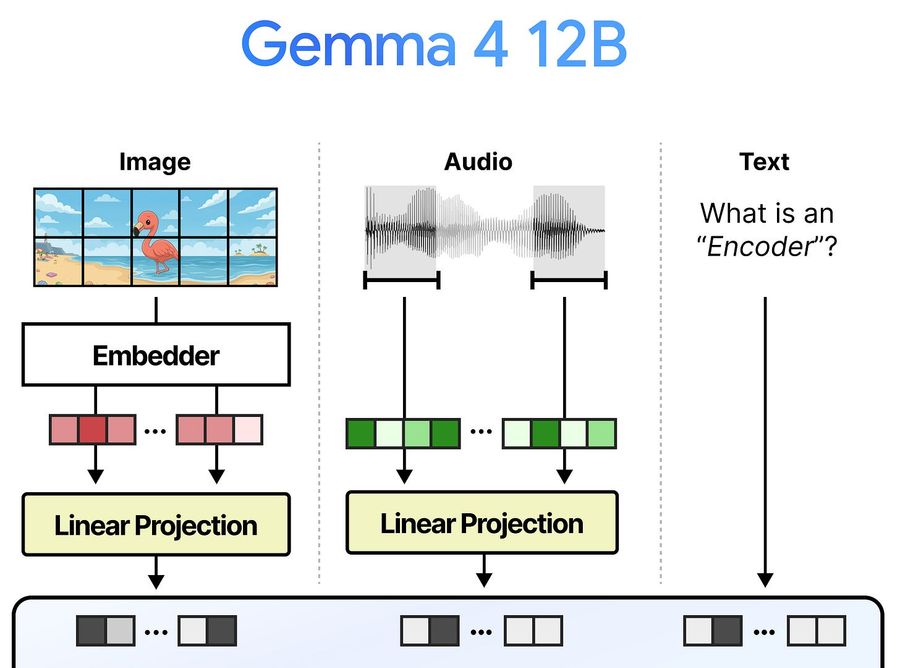
Как обычно подключают модальности к LLM
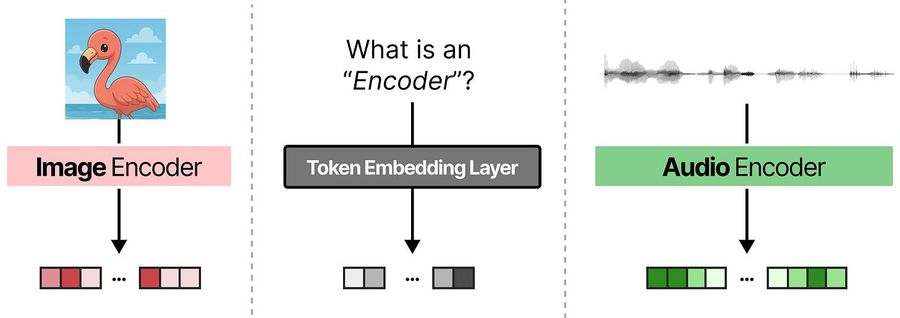
Когда LLM получает текст, token embedding-слой разбивает строку на токены и превращает их в эмбеддинги (числовые векторы). Затем они проходят через decoder-слои с attention-механизмами, где формируются осмысленные контекстные представления.
Чтобы научить LLM понимать другие модальности — аудио и изображения — обработку обычно выносят за пределы модели. Отдельный энкодер на базе Transformer сначала превращает входные данные в эмбеддинги. Это компактная модель с attention, работающая по тому же принципу, что и основная LLM.
Но полученные эмбеддинги нельзя передать LLM напрямую. У них другая размерность, и в n-мерном пространстве они ведут себя иначе. Стандартное решение — коннектор (адаптирующий слой), который приводит выход энкодера к той же размерности, что и token-эмбеддинги. В конце концов, Large Language Model обучена преимущественно на тексте.
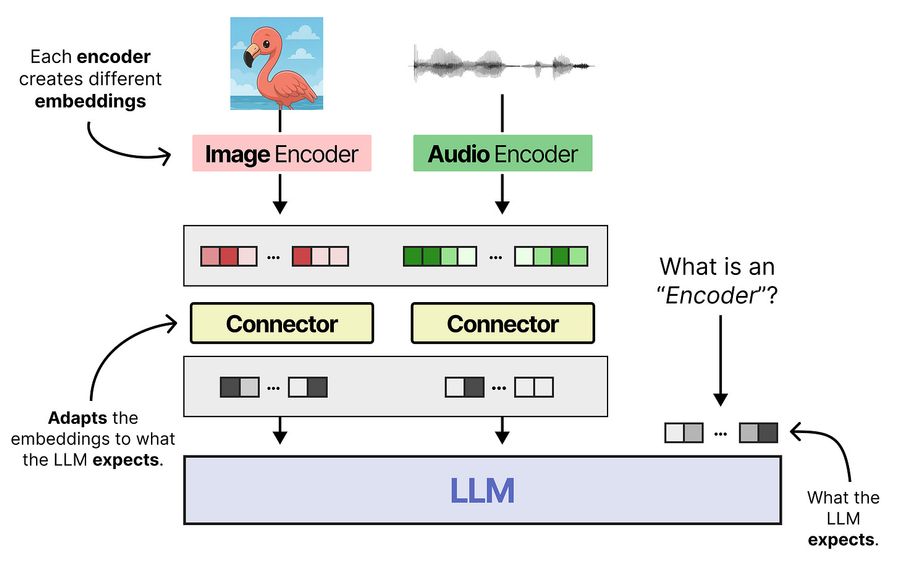
Эти два компонента — энкодер и коннектор — стандартная схема для мультимодальных LLM. Она работает и используется во многих open-access моделях, включая Gemma 4 и Qwen 3.5.
Но у неё есть цена. Нетекстовые энкодеры должны обработать вход до того, как запустится LLM — это добавляет латентность при инференсе. Плюс энкодеры заметно утяжеляют модель по количеству параметров.
А что, если обойтись без энкодера? Что, если достаточно одного коннектора?
Энкодеры в Gemma 4
Gemma 4 поддерживает три модальности:
- Текст — все модели
- Изображения — все модели
- Аудио — только E2B и E4B
Для каждой модальности нужна Transformer-подобная архитектура с attention. Для изображений и аудио используются два отдельных энкодера, которые создают визуальные и аудио-токены для LLM.
Все модели Gemma 4 (E2B, E4B, 26B A4B, 31B) имеют vision-энкодер. У E2B и E4B он весит 150 млн параметров, у 26B A4B и 31B — 550 млн.
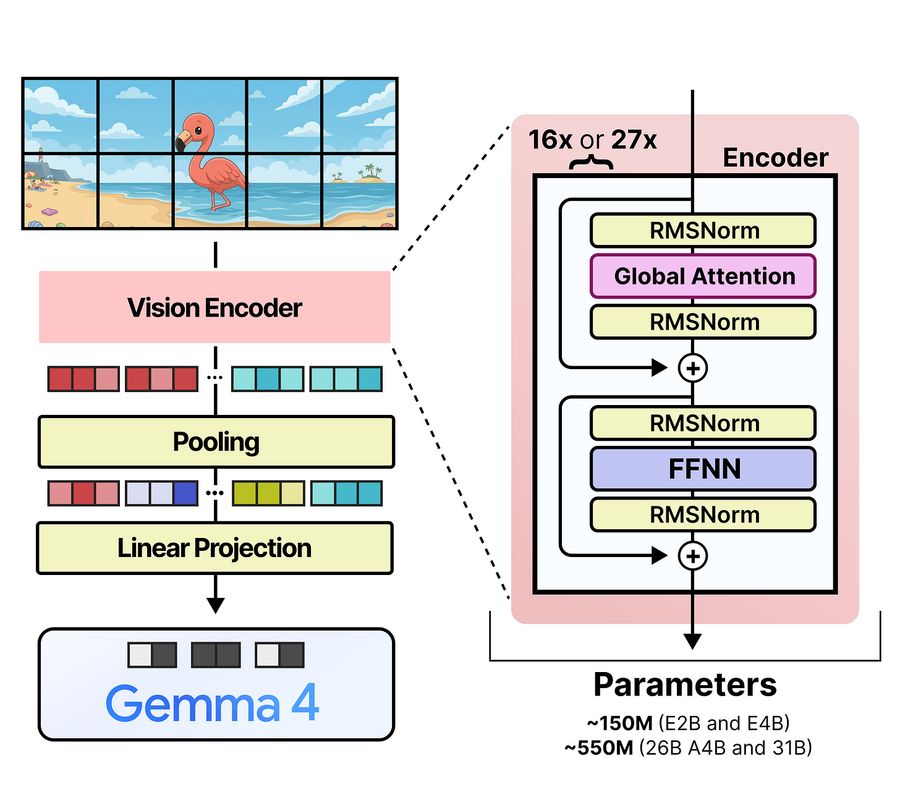
Входные патчи имеют размер 16×16 пикселей. После обработки в vision-энкодере они объединяются (pooling — операция сжатия) в сетку по 3×3 патча.
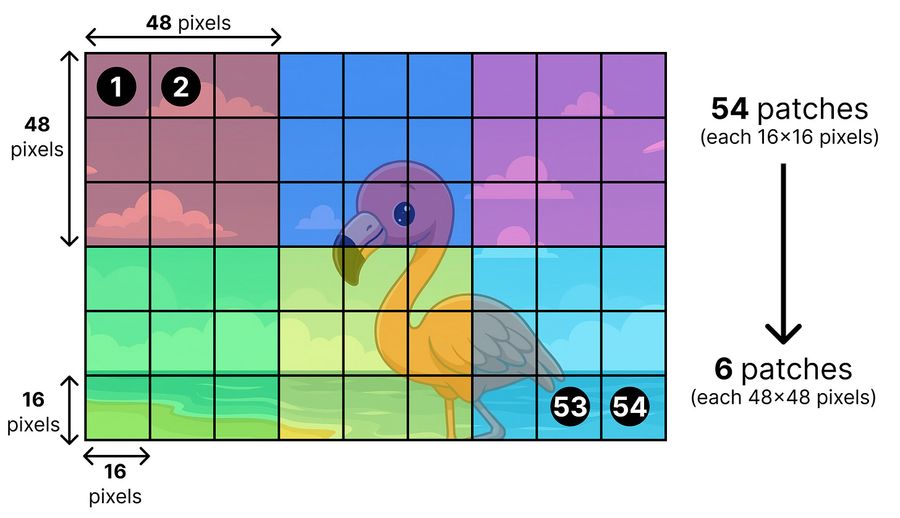
Итоговые patch-эмбеддинги описывают область 48×48 пикселей. После pooling линейный проекционный слой (коннектор) приводит их к размерности токенов LLM. Готовые patch-эмбеддинги имеют ту же форму, что и token-эмбеддинги, и чередуются с ними в последовательности.
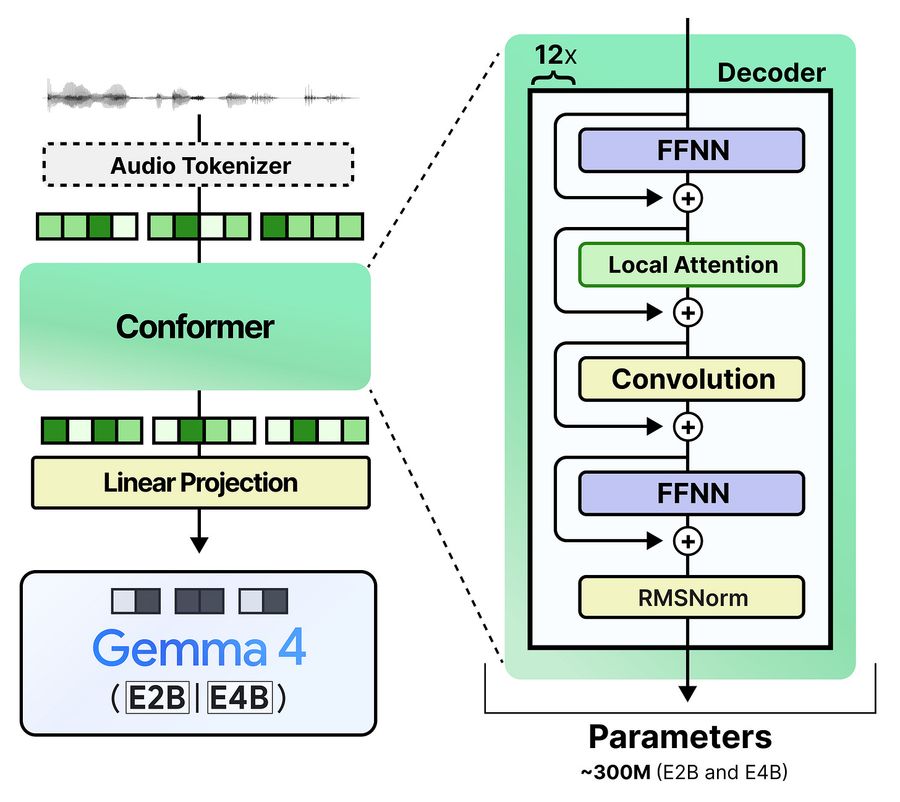
Модели E2B и E4B также имеют audio-энкодер весом 305 млн параметров (у обеих одинаковый). Как и vision-энкодер, он проецирует свои выходы в пространство токенов LLM. Аудио-токены чередуются с текстовыми.
Энкодеры относительно малы по сравнению с самой LLM, но они добавляют латентность и усложняют пайплайн. Кроме того, при fine-tuning Gemma 4 обычно обучают только LLM, а не энкодеры. Это затрудняет их совместное масштабирование.
Gemma 4 12B: архитектура без энкодеров
Чтобы убрать энкодеры и при этом выпустить новую модель, Google DeepMind создала Gemma 4 12B. По структуре decoder-я она близка к dense-модели (модели, где все параметры активны при каждом запросе) на 31B. Там тот же паттерн чередования local attention и global attention, причём global attention всегда идёт последним.
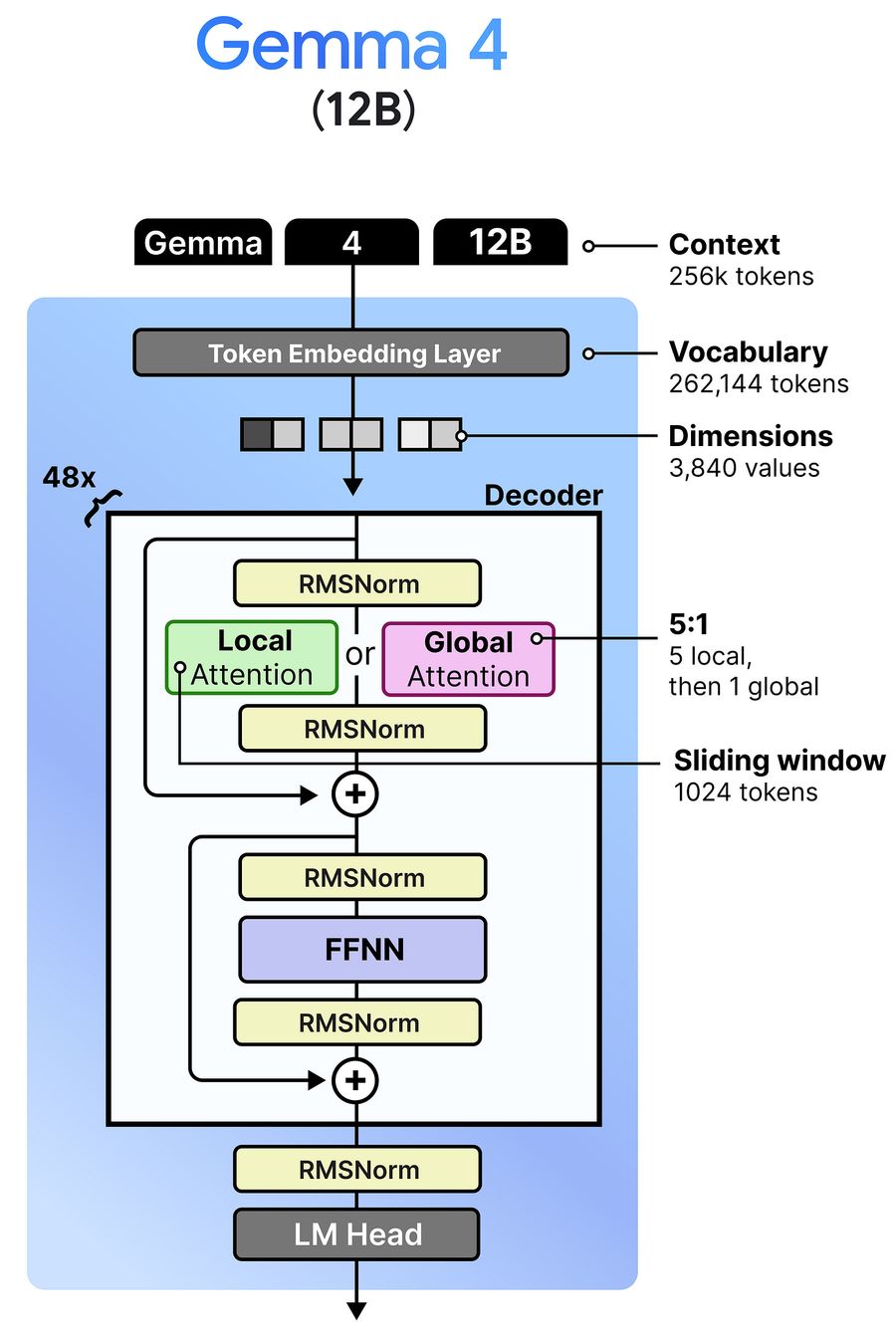
Модель органично встаёт между E4B и 26B A4B и подходит для конфигураций с 12–16 ГБ VRAM. Но главное отличие — отсутствие тяжёлых энкодеров.
Замена vision-энкодера
Вместо vision-энкодера с десятками Transformer-слоёв (15 или 27) Gemma 4 12B использует лёгкий embedding-модуль из одного слоя.
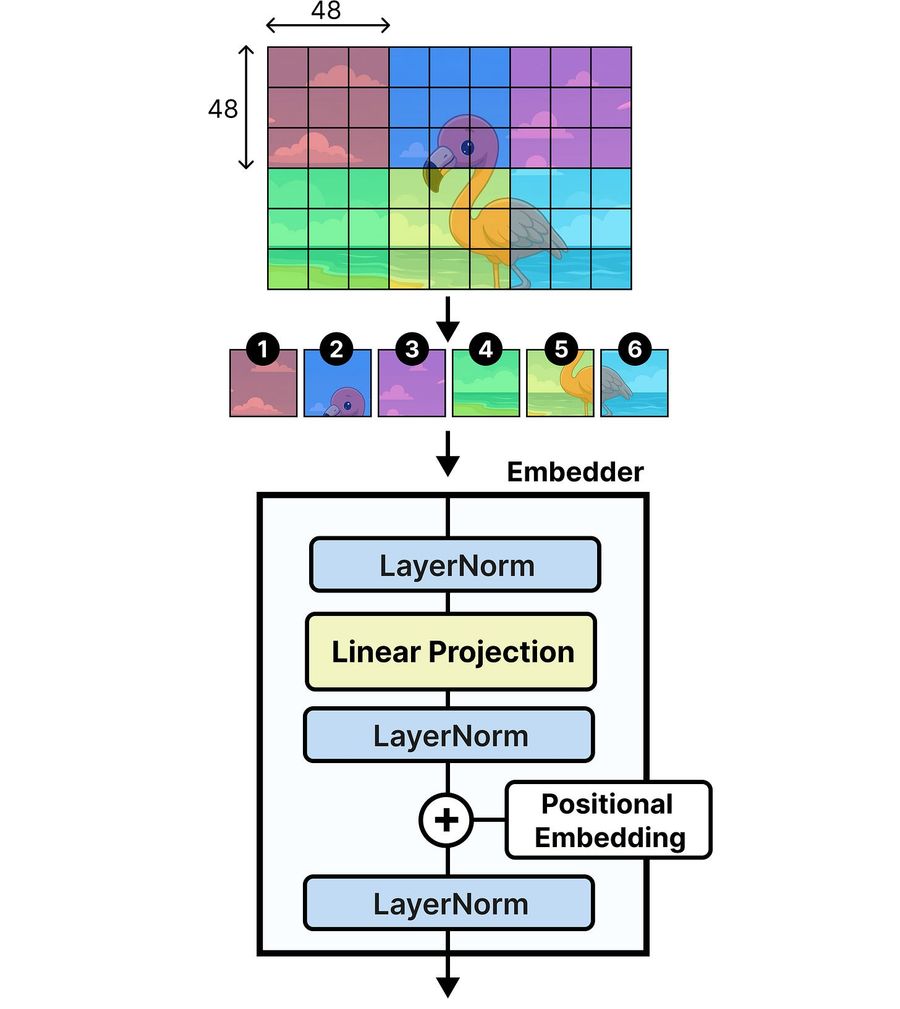
Модель работает с патчами 48×48 напрямую, а не 16×16 с последующим pooling. Vision-энкодер создавал семантически насыщенные эмбеддинги — у embedder-а такого нет. Поэтому объединять 16×16 в 48×48 особого смысла не было.
При обработке патчей нужно добавить позиционную информацию, чтобы LLM понимала, где находится каждый vision-токен на исходном изображении. Поскольку в embedder-е нет attention, использовать 2D-positional RoPE (метод позиционного кодирования) из vision-энкодера нельзя. Позиционное кодирование самой LLM тоже не подходит — оно воспринимает вход как одномерную последовательность.
Вместо этого пространственная информация добавляется в vision-эмбеддинги до попадания в LLM. Механизм простой и использует две матрицы:
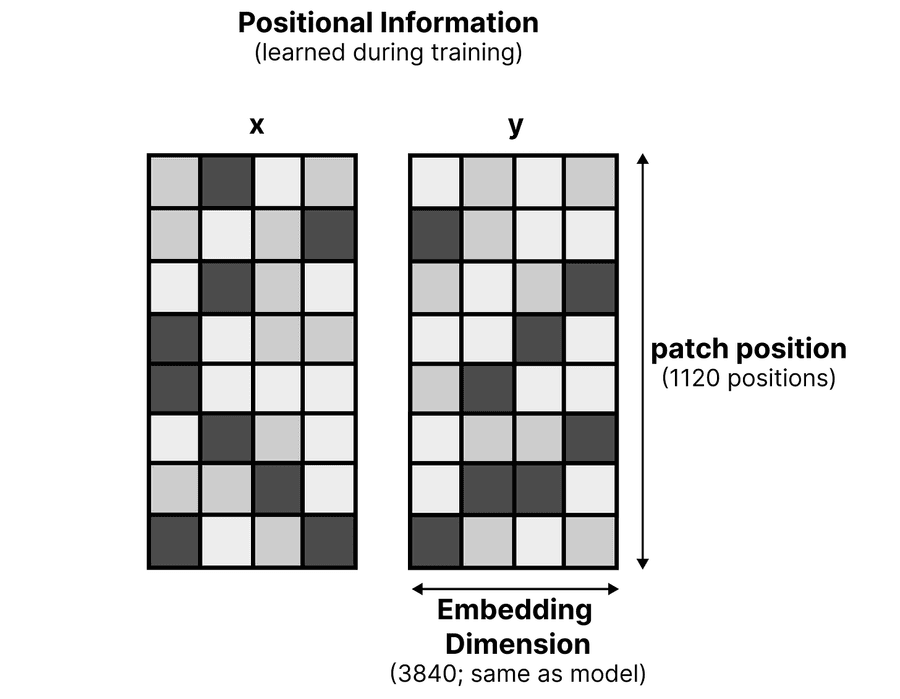
Эти матрицы кодируют x- и y-координаты патчей. Каждая имеет размерность 1120 (позиция патча) × 3840 (размерность входа модели). Число 1120 — максимальное количество патчей, на которое можно разбить изображение. Как и в моделях с vision-энкодерами, это количество поддерживает разные аспект-рейтио.
Gemma 4 с vision-энкодерами позволяет выбрать budget size (лимит токенов на изображение): 70, 140, 280, 560 или 1120 токенов (патчей). Больше токенов — более детальное восприятие.
Для каждого патча берутся соответствующие эмбеддинги из x- и y-матриц, суммируются и добавляются к vision-эмбеддингу. Пример: патч на позиции x=2, y=1 — берём строку 2 из x-матрицы и строку 1 из y-матрицы, складываем.
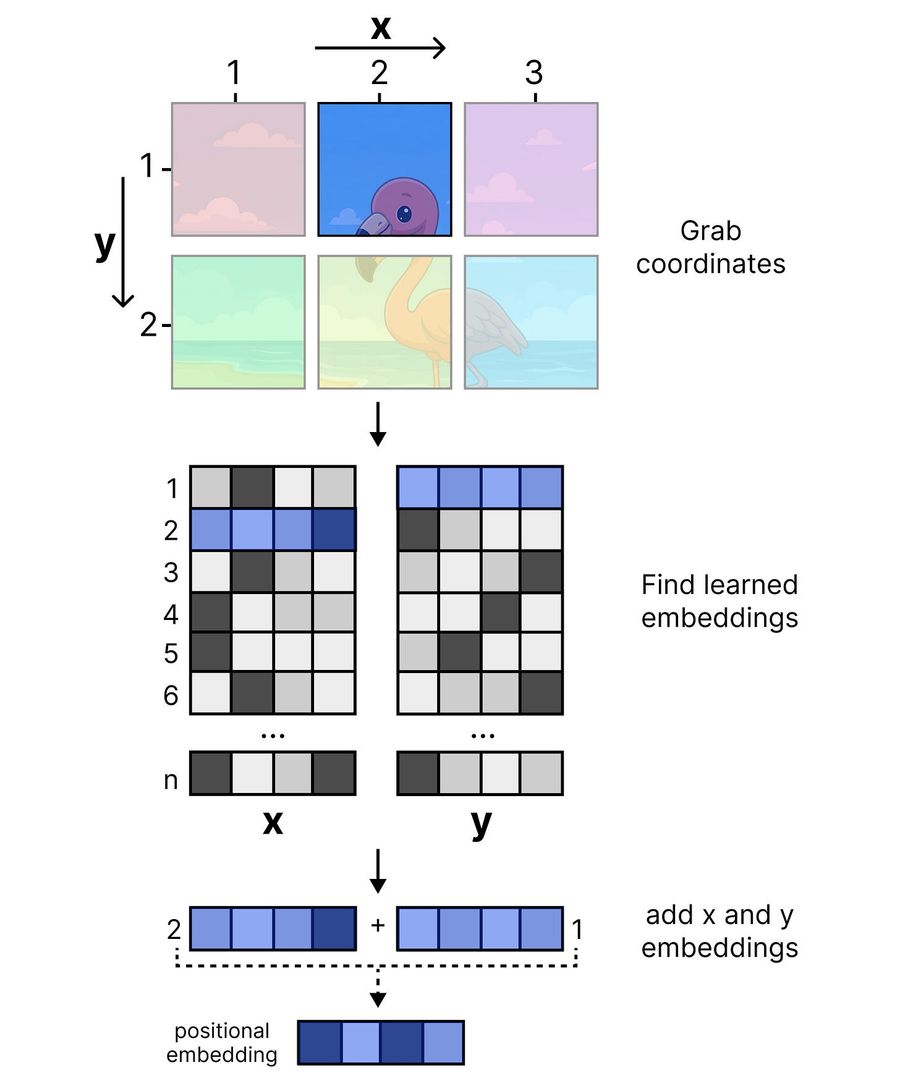
После добавления позиционных эмбеддингов идёт финальный LayerNorm для стабильности, затем проекция в размерность Gemma 4 12B.
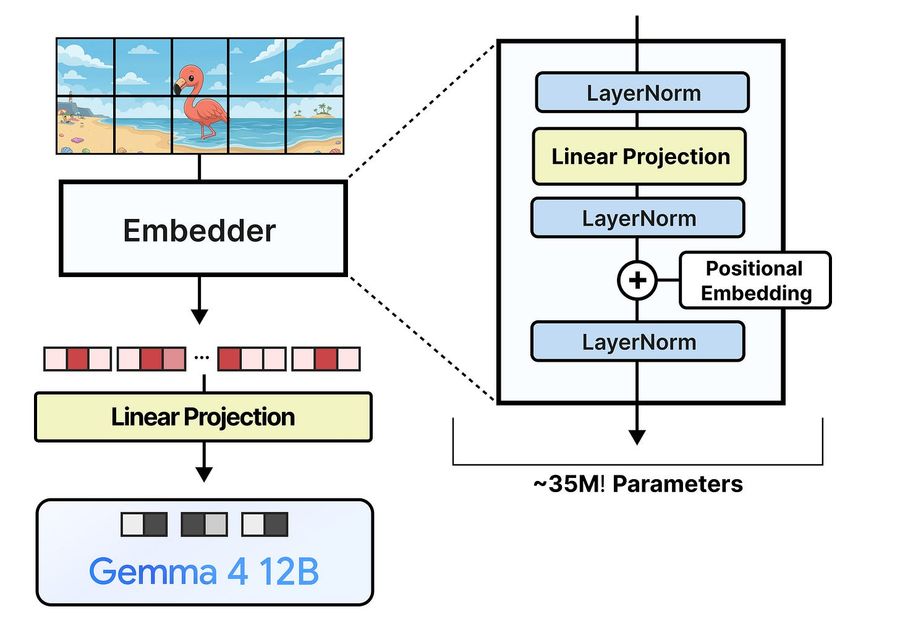
Против 550 млн параметров vision-энкодера в 31B — embedder весит всего ~35 млн. Но это не «бесплатный обед»: LLM приходится брать на себя обработку и понимание, которые раньше делал энкодер. Модель учится этому на этапе тренировки.
Откуда берутся 35 млн параметров при отсутствии энкодера? В основном из проекции патчей в размерность LLM. Каждый патч содержит 48 × 48 × 3 = 6912 значений, которые нужно спроецировать в 3840 (размерность Gemma 4 12B). Только эта проекция (6912 × 3840 + 3840) занимает ~26 млн параметров. То есть энкодер не сжался до 35 млн весов attention и FFN-слоёв (слоёв полносвязных нейронных сетей). Просто пикселей много и их нужно проектировать.
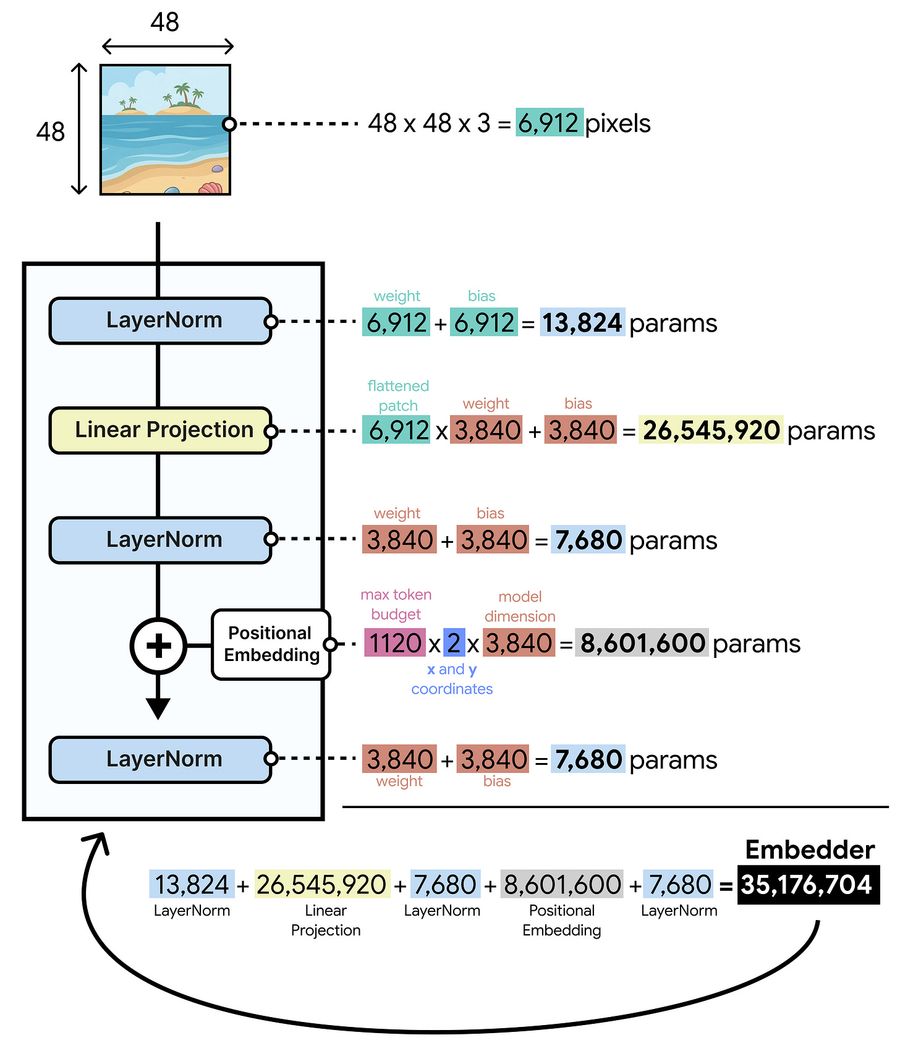
На схеме выше обрабатывается только один патч. Поскольку в embedder-е нет attention, каждый патч обрабатывается изолированно. Attention берёт на себя сама LLM.
Разница с Gemma 4 31B хорошо видна на сравнении: embedder минимальный и по сути только добавляет позиционные эмбеддинги. А vision-энкодер — полноценная модель на ~550 млн параметров.
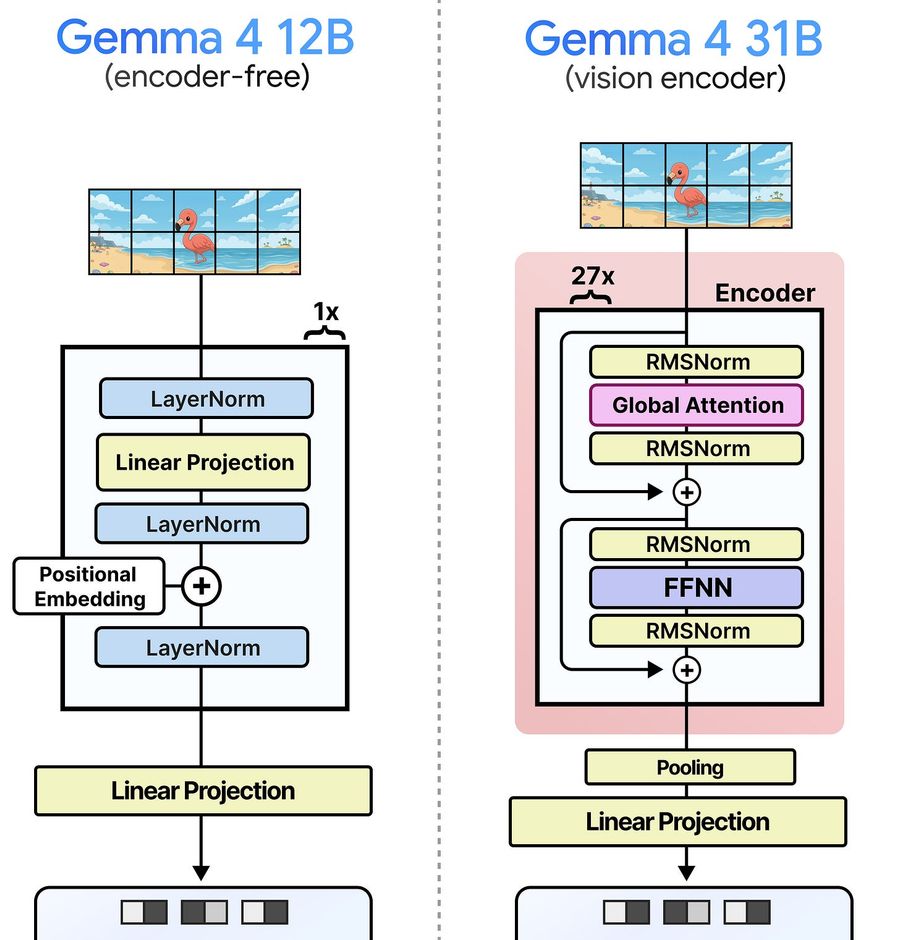
Ключевой плюс encoder-free подхода: vision-токены попадают в LLM значительно быстрее. Модель раньше начинает обрабатывать вход и генерировать ответ.
Замена audio-энкодера
С аудио всё ещё проще. Вместо того, чтобы извлекать признаки через энкодер, модель использует сырой аудиовход — по аналогии с сырыми пикселями для изображений. У аудио есть важное преимущество: ему не нужны дополнительные позиционные эмбеддинги. Аудио уже представляет собой одномерную последовательность и обрабатывается так же, как текст.
Аудиовход разбивается на сегменты по 40 миллисекунд. При частоте дискретизации 16 кГц каждый сегмент содержит 640 значений — это сырые амплитудные сэмплы звуковой волны.
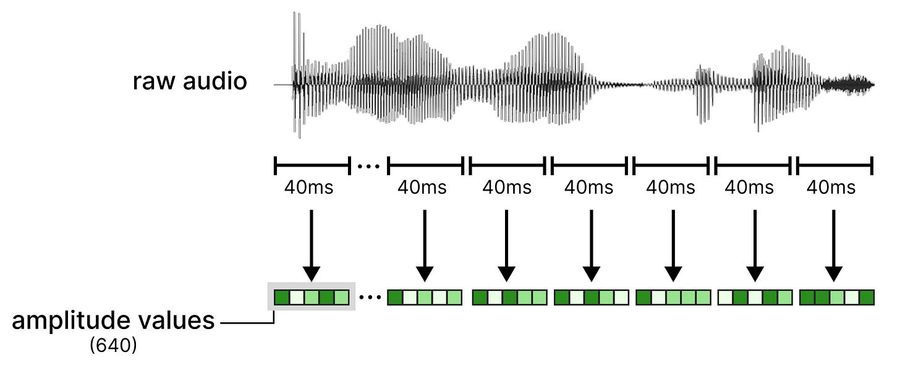
Эти сырые признаки подаются в линейный проекционный слой, который приводит их к размерности Gemma 4 12B.
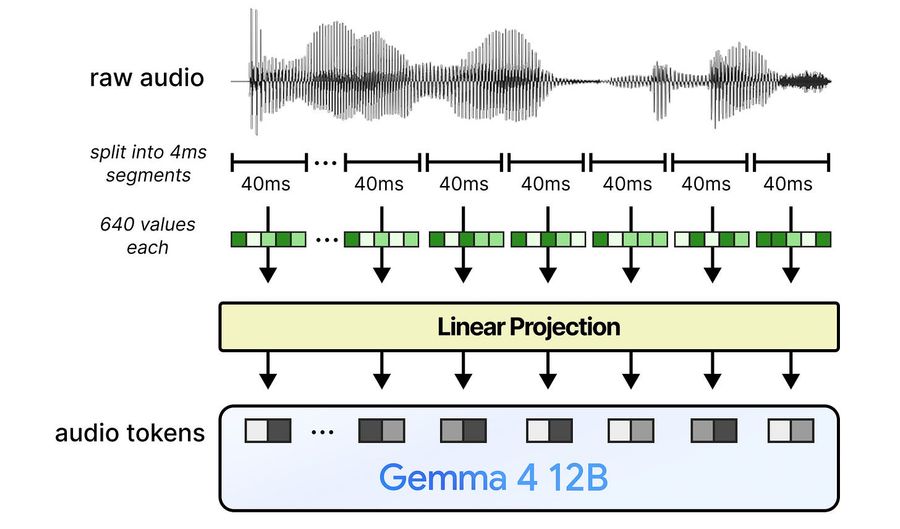
Весь подход сводится к тому, чтобы убрать энкодер и напрямую спроецировать сырые признаки в формат текстовых токенов.
На сравнении ниже хорошо видна разница: Gemma 4 E4B токенизирует аудио и прогоняет его через стопку decoder-слоёв. А Gemma 4 12B — просто разбивает на сегменты и проецирует.
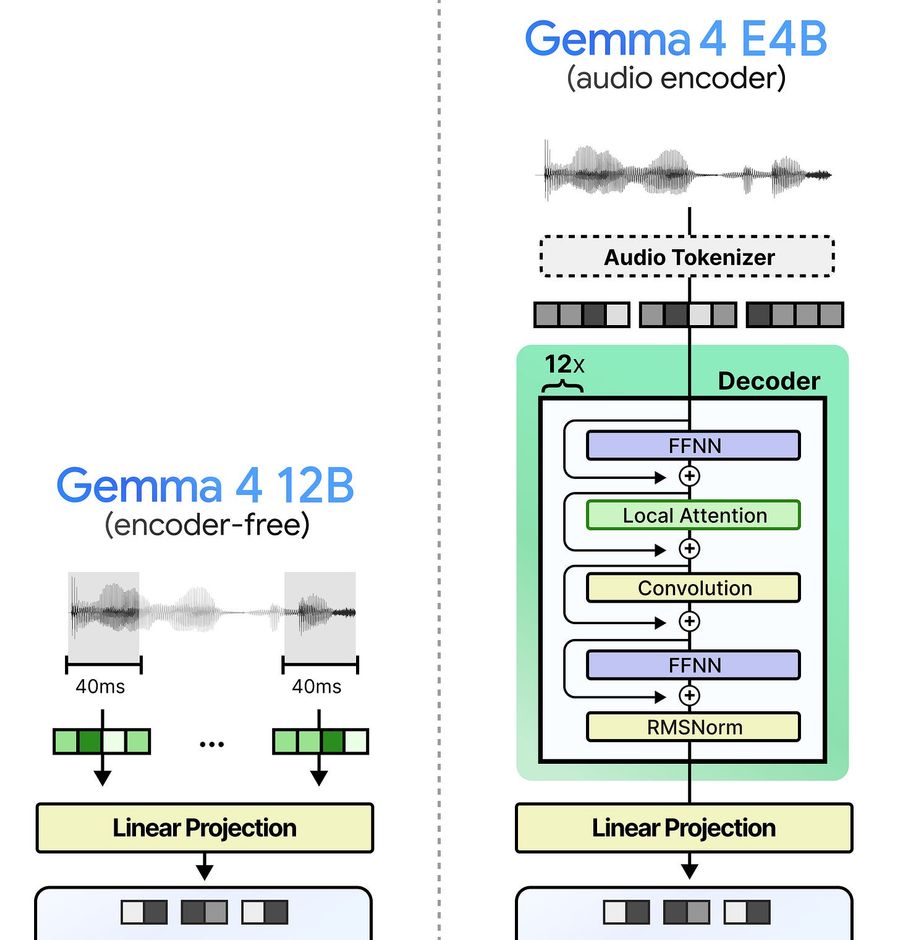
Gemma 4 12B не просто закрывает пробел между E4B и 26B A4B. Она использует принципиально иной подход к мультимодальности.