
Аннотация
Мы исследуем адверсариальную устойчивость open-source vision-language моделей (VLM — модели для совместной работы с изображениями и текстом), развёрнутых в изолированной e-commerce среде. Среда имитирует реальные условия перед запуском. Оцениваем два агента — LLaVA-v1.5-7B и Qwen2.5-VL-7B — против трёх градиентных атак: Basic Iterative Method (BIM), Projected Gradient Descent (PGD) и спектральной атаки на основе CLIP. Против LLaVA все три атаки показывают высокий success rate (52.6%, 53.8% и 66.9% соответственно). Это доказывает, что простые градиентные методы — реальная угроза для open-source VLM-агентов. Qwen2.5-VL значительно устойчивее (6.5%, 7.7% и 15.5%). Это указывает на существенные архитектурные различия в устойчивости между семействами open-source VLM. Результаты напрямую влияют на оценку безопасности VLM-агентов перед коммерческим запуском.
1 Введение
Vision-language модели достигли впечатляющих результатов в задачах визуального вопрос-ответа (Visual Question Answering, VQA) и мультимодальном рассуждении. Однако они остаются крайне уязвимыми к адверсариальным возмущениям: даже незаметный шум в изображении может сильно исказить интерпретацию [5]. Недавние работы показали адверсариальную уязвимость проприетарных VLM-агентов с помощью black-box атак через замещающие модели (surrogate) [14]. При этом устойчивость open-source VLM-агентов к более простым white-box градиентным атакам (с полным доступом к весам модели) в реалистичных интерактивных сценариях системно не оценивалась.
Мы закрываем этот пробел с помощью фреймворка для тестирования на проникновение (red-teaming). Он включает: поэтапную e-commerce веб-среду, агента автоматизации браузера и inference-серверы для двух open-source VLM — LLaVA-v1.5-7B и Qwen2.5-VL-7B. Три градиентные атаки — BIM, PGD и спектральная атака на основе CLIP — показывают, что LLaVA крайне уязвима ко всем методам. Qwen2.5-VL демонстрирует существенно бóльшую устойчивость. Эта разница важна на практике. Она влияет на решения о развёртывании, когда проприетарные модели недоступны из-за стоимости или ограничений приватности.
2 Обзор литературы
Адверсариальные атаки были расширены на системы VQA. Sharma et al. [12] показали, что через использование attention-карт VQA-модели можно создавать небольшие возмущения изображения, меняющие ответ модели. Метод Attend-and-Attack требует white-box доступа: для заданных изображения и вопроса он искажает картинку так, чтобы VQA выдала другой ответ (untargeted attack — без заданной целевой метки). Другие атаки на VQA включают VQAttack. Он совместно искажает признаки изображения и текст вопроса через пайплайн с использованием LLM [13]. Литература показывает, что как чисто визуальные, так и совместные vision-text возмущения снижают точность VQA [16, 13].
Более свежие работы нацелены на современные большие VLM (BLIP-2, LLaVA, Flamingo). Эти модели используют проектор/Q-Former (модуль выравнивания визуальных и текстовых признаков). [2] предлагают IPGA — targeted атаку через проектор. Вместо возмущения сырых пикселей она атакует промежуточные Q-Former токены для точного контроля [3]. IPGA достигает более высокого success rate в VQA и даже переносится на закрытые модели (Google Gemini, GPT) [9]. Аналогично, [15] вводят фреймворк Chain-of-Attack (CoA). Он пошагово семантически обновляет мультимодальные эмбеддинги для создания более сильных адверсариальных изображений. Эти методы полагаются на white-box или сильный surrogate-доступ и подтверждают хрупкость VLM к изощрённым атакам на изображения [3, 5].
Адверсариальные patch-атаки (накладываемые патчи — ограниченные участки изображения) на VLM также исследовались. Kong et al. (2024) предлагают «Patch is Enough» — метод, генерирующий естественные патчи с помощью диффузионных моделей для VLP-моделей. Размещая патчи по cross-attention картам модели, они достигают ~100% success rate в white-box задачах image-to-text [6]. Xu et al. [16] предлагают Embedding Disruption Patch Attack (EDPA) для vision-language-action моделей. Патч оптимизируется для разрушения выравнивания визуального и текстового скрытых представлений. В робототехнике [13] показано, что даже небольшой адверсариальный патч в поле зрения камеры полностью ломает политику принятия решений робота, снижая success rate задач до 0%.
Ближе всего к нашей работе — Wu et al. [14], демонстрирующие атаки на проприетарные VLM-агенты в VisualWebArena. Они предлагают captioner-атаку на white-box компоненты и CLIP-атаку для black-box проприетарных моделей (GPT-4V, Gemini-1.5, Claude-3) с ASR (Attack Success Rate, доля успешных атак) до 75%. Их работа сфокусирована исключительно на проприетарных моделях через API. Мы же оцениваем open-source VLM-агенты (LLaVA, Qwen2.5-VL) в изолированной среде развёртывания. Мы обнаруживаем существенные различия в устойчивости между архитектурами.
В целом литература показывает: (1) white-box градиентные атаки (FGSM/PGD/BIM) на изображения нарушают точность VQA; (2) cross-modal атаки, возмущающие и изображение, и текст, эффективны для переносимости между моделями; (3) patch-атаки могут универсально обманывать VLM при размещении в наиболее заметных (salient) областях [1, 6]. В этой работе мы фокусируемся на white-box градиентных атаках (BIM, PGD) и спектральной атаке на основе CLIP против open-source VLM-агентов в интерактивном e-commerce сценарии.
3 Методы
Мы конструируем адверсариальные возмущения для vision-language моделей тремя подходами: Basic Iterative Method (BIM) [8], Projected Gradient Descent (PGD) [10] и спектральная атака на основе pretrained CLIP-энкодеров [11]. BIM и PGD работают в white-box режиме с прямым доступом к весам целевой VLM. Спектральная CLIP-атака использует замещающие (surrogate) CLIP-энкодеры и оценивает переносимость на целевую VLM. Все атаки встроены в изолированный фреймворк развёртывания.
3.1 Среда развёртывания
Для оценки устойчивости в реалистичных условиях мы строим изолированный e-commerce red-teaming фреймворк. Система состоит из трёх компонентов: (1) Flask-витрина с товарными листингами, где внедрены адверсариальные изображения; (2) inference-серверы для LLaVA-v1.5-7B и Qwen2.5-VL-7B, принимающие скриншоты и возвращающие структурированные JSON-действия; (3) Selenium-агент автоматизации браузера. Он захватывает скриншоты, опрашивает VLM-сервер, парсит ответное действие и выполняет клики или навигацию. Агент работает автономно по команде на естественном языке (например, «купи свитер»). Он итерирует до совершения покупки или исчерпания бюджета итераций. Успех атаки измеряется как доля случаев, когда агент покупает целевой товар атаки вместо товара, соответствующего команде пользователя.
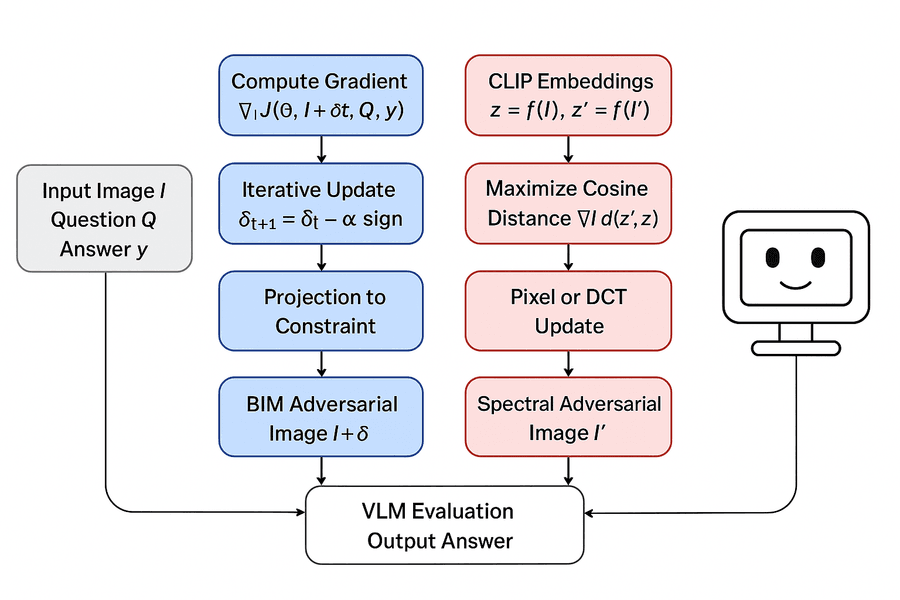
Рисунок 1: Обзор red-teaming пайплайна. Адверсариально искажённое товарное изображение подаётся через Flask-витрину, захватывается как скриншот Selenium-агентом и передаётся на VLM inference-сервер. VLM возвращает структурированное действие, заставляя агента купить целевой товар атаки вместо задуманного.
3.2 Basic Iterative Method
BIM расширяет FGSM, применяя множество маленьких градиентных шагов внутри ограниченной области допустимых изменений пикселей (ℓ∞-шар). Пусть I — входное изображение, Q — вопрос, y — правильный (ground truth) ответ. Для модели с параметрами θ пусть J(θ,I,Q,y) — функционал потерь задачи. На итерации t BIM обновляет возмущение δₜ:
δₜ₊₁ = Proj‖δ‖∞≤ϵ(δₜ − α·sign(∇ᵢJ(θ, I + δₜ, Q, y))),
где ϵ = 16/255 — бюджет возмущения, α = 1/255 — размер шага, в соответствии со стандартными конвенциями незаметности [14]. Изображение нормализуется и конвертируется в дифференцируемый тензор. Градиенты накапливаются исключительно по переменной возмущения. Все параметры модели заморожены. Периодически выходы прогоняются через полный VLM inference-пайплайн. Это проверяет, изменило ли возмущение предсказанный ответ. Применяется early stopping при уверенном неверном предсказании (95%+).
3.3 Projected Gradient Descent
PGD [10] расширяет BIM, вводя случайную инициализацию возмущения внутри ℓ∞-шара перед итерациями. Пусть δ₀ ~ Uniform(−ϵ, ϵ) — случайный старт. На итерации t PGD обновляет возмущение:
δₜ₊₁ = Proj‖δ‖∞≤ϵ(δₜ − α·sign(∇ᵢJ(θ, I + δₜ, Q, y))),
с ϵ = 16/255 и α = 1/255. Случайная инициализация отличает PGD от BIM (где δ₀ = 0) и обеспечивает лучшее покрытие ландшафта потерь вокруг чистого изображения. Все параметры модели заморожены. Сохраняется лучшее возмущение по всем итерациям. Применяется early stopping при превышении порога уверенности успеха атаки.
3.4 Спектральная атака на основе CLIP
Для оценки переносимости за пределы одной VLM-архитектуры мы вводим спектрально-доменную атаку. Она оптимизирует потери от ансамбля четырёх замещающих (surrogate) CLIP-энкодеров [11]: ViT-B/32, ViT-B/16, ViT-L/14 и ViT-L/14@336px. Пусть z = fCLIP(I) и z′ = fCLIP(I′) — визуальные эмбеддинги CLIP чистого и искажённого изображений. Цель — максимизировать косинусное расстояние между z и z′ при ℓ∞-ограничении:
I′ₜ₊₁ = Proj‖·‖∞≤ϵ(I′ₜ + α·sign(∇ᵢ′ d(fCLIP(I′), fCLIP(I)))),
где косинусное расстояние между эмбеддингами максимизируется напрямую через градиент 1 − (z · z′)/(‖z‖·‖z′‖) по I′. Возмущение параметризуется в области дискретного косинусного преобразования (DCT — разложение изображения на частотные компоненты) с подходом SSA-CommonWeakness [4]. Атака применяет трёхмерное DCT к каждому каналу изображения, обновляет спектральные коэффициенты и реконструирует адверсариальное изображение через обратное DCT. Это нацелено на частотные компоненты, сильно влияющие на геометрию CLIP-эмбеддингов. Благодаря этому улучшается переносимость между разными моделями. Четыре surrogate-модели CLIP распределяются по доступным GPU. Все параметры заморожены, выполняются forward и backward passes для вычисления градиентов расхождения в пространстве признаков (feature space).
Таблица 1: Доля правильных покупок (%) и ASR (%) с 95% доверительными интервалами по 630 испытаниям на условие. Все атаки используют ϵ = 16/255.
4 Эксперименты
4.1 Экспериментальная установка
Все эксперименты проведены в изолированном e-commerce фреймворке: staging веб-витрина, inference-серверы для LLaVA-v1.5-7B и Qwen2.5-VL-7B, Selenium-агент автоматизации браузера. Агент получает команду на естественном языке и автономно навигирует по витрине. Он захватывает скриншоты и формирует структурированные JSON-действия покупки. Адверсариальные товарные изображения внедрялись в витрину перед каждым испытанием. Все атаки используют фиксированный бюджет возмущения ϵ = 16/255 и размер шага α = 1/255. Мы приводим Attack Success Rate (ASR) — долю испытаний, где адверсариальное возмущение успешно перенаправляет агента на покупку целевого неправильного товара. По 630 испытаний на каждую атаку и модель. 95% доверительные интервалы вычислены через Wilson score interval.
4.2 Базовая оценка
Чистые базовые линии установлены для обоих агентов без адверсариального ввода. Это нужно для подтверждения корректной работы фреймворка. В чистых условиях LLaVA-v1.5-7B правильно покупала целевой товар в 90% испытаний, Qwen2.5-VL-7B — в 98%. Более высокая чистая точность Qwen2.5-VL отражает её более сильные возможности привязки к визуальным объектам (visual grounding) относительно LLaVA-v1.5. Эти базовые линии подтверждают, что оба агента надёжно работают без возмущений.
4.3 Attack Success Rate
Таблица 1 показывает ASR для всех трёх атак против обеих моделей. Против LLaVA-v1.5-7B все три атаки достигают существенного ASR: BIM — 52.6%, PGD — 53.8%, CLIP-спектральная атака — 66.9%. Близость результатов BIM и PGD говорит о том, что случайная инициализация даёт мало дополнительной выгоды по сравнению с нулевой. Вероятно, ландшафт потерь вокруг чистого изображения относительно гладкий. CLIP-спектральная атака достигает более высокого ASR против LLaVA, несмотря на отсутствие прямого доступа к весам целевой модели. Это указывает, что разрушение пространства признаков в геометрии CLIP-эмбеддингов особенно эффективно против vision-энкодера LLaVA-v1.5.
Против Qwen2.5-VL-7B все три атаки существенно менее эффективны: BIM — 6.5%, PGD — 7.7%, CLIP-спектральная атака — 15.5%. CLIP-атака снова показывает наивысший ASR, что согласуется с паттерном на LLaVA. Но даже самая эффективная атака снижает долю правильных покупок Qwen лишь на 13.8 процентных пунктов от чистой базовой линии 98.3%. Это указывает на сильное сопротивление всем трём методам.
4.4 Различная устойчивость между семействами VLM
Ключевой вывод — существенная разница в адверсариальной устойчивости между LLaVA-v1.5-7B и Qwen2.5-VL-7B. По всем трём атакам Qwen2.5-VL сохраняет околобазовую производительность. Доля правильных покупок после атак составляет 93.5%, 92.3% и 84.5% для BIM, PGD и CLIP соответственно при чистой базовой линии 98.3%. LLaVA-v1.5-7B, напротив, существенно деградирует: 47.4%, 46.2% и 33.1% при базовой линии 90.2%. Эта разница имеет прямые практические последствия. Организации, развёртывающие open-source VLM-агентов в коммерческих условиях, не должны считать адверсариальную устойчивость одинаковой для всех семейств моделей. Явная адверсариальная оценка должна стать стандартным компонентом преддеплойментного тестирования автономных покупающих агентов.
5 Ограничения
Мы оценили два open-source семейства VLM (LLaVA-v1.5-7B и Qwen2.5-VL-7B). Наблюдаемую разницу в устойчивости нельзя обобщить на другие архитектуры (InstructBLIP, mPLUG-Owl, LLaMA-Vision) без дополнительных оценок. Кроме того, все эксперименты проведены в изолированной staging e-commerce среде. Перенос на реальные production-развёртывания с динамическим контентом, аутентификацией и переменными условиями рендеринга не верифицирован.
6 Заключение
Мы представили систематическую оценку адверсариальной устойчивости open-source VLM-агентов для покупок в изолированной e-commerce среде. Три градиентные атаки — BIM, PGD и CLIP-спектральная — показали, что LLaVA-v1.5-7B крайне уязвима (ASR 52.6%, 53.8% и 66.9% соответственно). Qwen2.5-VL-7B существенно устойчивее (ASR 6.5%, 7.7% и 15.5%), сохраняя околобазовую точность покупок даже под возмущением.
Центральный результат — разница в устойчивости между двумя семействами моделей. CLIP-спектральная атака достигает наивысшего ASR против обеих моделей. Это говорит о том, что разрушение пространства признаков в геометрии CLIP-эмбеддингов — более эффективный вектор атаки, чем прямая градиентная оптимизация для обеих архитектур. Масштаб эффекта существенно различается между моделями. Это указывает на содержательные архитектурные отличия в обработке адверсариальных визуальных входов LLaVA-v1.5 и Qwen2.5-VL. Это имеет немедленные практические последствия: адверсариальную устойчивость нельзя считать одинаковой для всех open-source VLM-семейств. Явная адверсариальная оценка должна стать стандартом преддеплойментного тестирования.
Дальнейшая работа будет исследовать архитектурные источники устойчивости Qwen2.5-VL, оценивать дополнительные open-source VLM-семейства и искать облегчённые (lightweight) защиты для сценариев, где переобучение невозможно.
Список литературы
- [1] T. B. Brown, D. Mané, A. Roy, M. Abadi, and J. Gilmer (2018) Adversarial patch. arXiv preprint arXiv:1712.09665.
- [2] Y. Cao, Y. Li, K. Liang, and B. Xiao (2025) Enhancing targeted adversarial attacks on large vision-language models via intermediate projector. Link
- [3] Y. Cao, Y. Li, K. Liang, Y. Lai, and B. Xiao (2025) Enhancing targeted adversarial attacks on large vlms through intermediate projector guidance. arXiv preprint arXiv:2508.13739.
- [4] H. Chen, Y. Zhang, Y. Dong, X. Yang, H. Su, and J. Zhu (2024) Rethinking model ensemble in transfer-based adversarial attacks. Link
- [5] I. J. Goodfellow, J. Shlens, and C. Szegedy (2015) Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
- [6] D. Kong, S. Liang, X. Zhu, Y. Zhong, and W. Ren (2024) Patch is enough: naturalistic adversarial patch against vlp models. Visual Intelligence.
- [7] A. Kurakin, I. Goodfellow, and S. Bengio (2017) Adversarial examples in the physical world. Link
- [8] A. Kurakin, I. Goodfellow, and S. Bengio (2017) Adversarial machine learning at scale. In ICLR Workshop.
- [9] D. Liu, M. Yang, X. Qu, P. Zhou, X. Fang, K. Tang, Y. Wan, and L. Sun (2024) Pandora’s box: universal attackers against real-world lvlms. In NeurIPS.
- [10] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu (2018) Towards deep learning models resistant to adversarial attacks. In ICLR.
- [11] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Kruegel, and I. Sutskever (2021) Learning transferable visual models from natural language supervision. In ICML.
- [12] V. Sharma, A. Kalra, V. Vaibhav, S. Chaudhary, L. Patel, and L. Morency (2018) Attend and attack: attention guided adversarial attacks on vqa models. In NeurIPS.
- [13] T. Wang, C. Han, J. C. Liang, W. Yang, D. Liu, L. Zhang, Q. Wang, J. Luo, and R. Tang (2024) Exploring adversarial vulnerabilities of vision language action models in robotics. arXiv preprint arXiv:2411.13587.
- [14] C. H. Wu, R. Shah, J. Y. Koh, R. Salakhutdinov, D. Fried, and A. Raghunathan (2025) Dissecting adversarial robustness of multimodal lm agents. Link
- [15] P. Xie, Y. Bie, J. Mao, Y. Song, Y. Wang, H. Chen, and K. Chen (2025) Chain of attack: robustness of vlms against transfer-based attacks. In CVPR.
- [16] H. Xu, Y. S. Koh, S. Huang, Z. Zhou, D. Wang, J. Sakuma, and J. Zhang (2025) Model-agnostic adversarial attack and defense for vla models. arXiv preprint arXiv:2510.13237.
- [17] Z. Yin, M. Ye, T. Zhang, J. Wang, H. Liu, J. Chen, T. Wang, and F. Ma (2024) VQAttack: transferable adversarial attacks on visual question answering via pre-trained models. In AAAI.
Приложение А. Адверсариальная атака на VLM веб-агенты: подробности
Это приложение содержит дополнительные иллюстрации и детали реализации адверсариального пайплайна атаки. Атака нацелена на VLM (LLaVA), работающую как веб-агент для покупок. Она демонстрирует, как искажённое товарное изображение может заставить агента выбрать неверный товар.
А.1 Обзор атаки
Модель угрозы предполагает атакующего, способного модифицировать пиксельное содержимое одного товарного изображения в e-commerce витрине. Агент-жертва получает команды на естественном языке (например, «купи штаны» или «купи свитер») и автономно просматривает магазин. Он воспринимает веб-страницу как скриншот и формирует структурированные JSON-действия. Цель атакующего — создать адверсариальное возмущение δ такое, что при добавлении к исходному изображению x искажённое изображение x̃ = x + δ заставляет агента ошибочно идентифицировать адверсариальный товар как целевой из команды.
Формально, пусть fθ — vision-language агент, c — команда покупки, s — скриншот страницы с адверсариальным товаром. Атака ищет:
δ* = arg min‖δ‖∞≤ϵ L(fθ(s(x + δ), c), ytarget)
где ytarget — желаемое (неправильное) действие, L — подходящий функционал потерь. Мы используем BIM [7] для решения этой оптимизации, итеративно обновляя возмущение проекционными градиентными шагами.
А.2 Изображение-жертва и адверсариальное возмущение
На рисунке 2 сравниваются оригинальное товарное изображение и его адверсариально искажённая версия, сгенерированная через BIM. Оба изображения показывают один и тот же свитер Duke Lemur Center. Но адверсариальная версия несёт незаметное пиксельное возмущение, наложенное на фон и область самого свитера. Для человеческого наблюдателя изображения визуально неотличимы. Однако возмущений достаточно, чтобы ввести VLM-агента в заблуждение при классификации категории товара.

(a) Оригинальное товарное изображение (x)

(b) Адверсариальное изображение после BIM-возмущения (x̃ = x + δ*)
Рисунок 2: Сравнение оригинального товарного изображения и его BIM-искажённой адверсариальной версии. Возмущение ограничено ‖δ‖∞ ≤ ϵ и визуально незаметно, но достаточно для обмана LLaVA веб-агента.
А.3 Пошаговый проход атаки
Сквозной пайплайн атаки проходит через следующие этапы:
Шаг 1: Инициализация агента и подача команды.
LLaVA Shopping Web Agent инициализируется через командную строку. Пользователь (или контролируемая атакующим система) подаёт команду на естественном языке. Рисунок 3 показывает две типичные команды: buy sweater и buy pants. В обоих случаях агент настроен на максимум 10 итераций просмотра и начинает без предзагруженной страницы, навигируя автономно с нуля.
(a) Агент инициализирован с командой: buy sweater
(b) Агент инициализирован с командой: buy pants
Рисунок 3: Инициализация LLaVA Shopping Web Agent. Агент получает команду на естественном языке и начинает автономную навигацию с настраиваемым бюджетом итераций.
Шаг 2: Агент просматривает витрину с адверсариальным товаром.
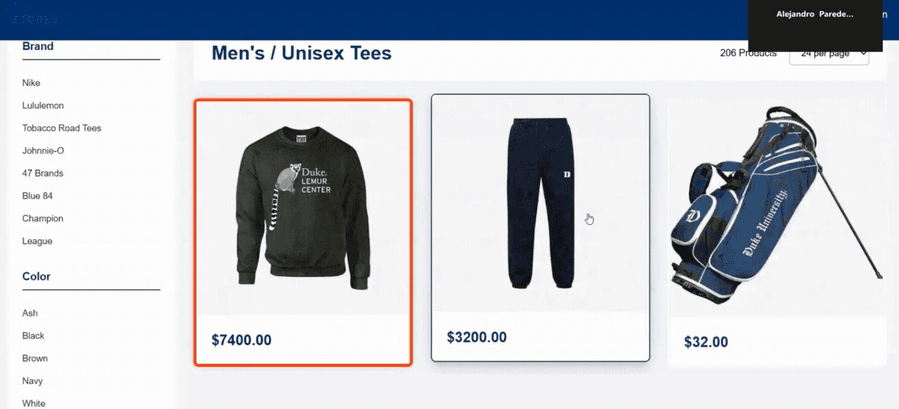
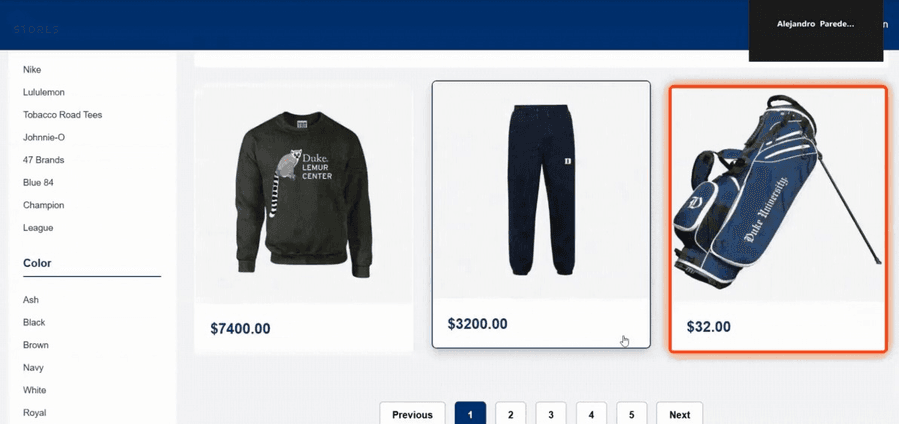
При навигации агент захватывает скриншоты витрины. Адверсариальное товарное изображение x̃ внедрено в листинг (item 0 в сетке). Рисунок 4 показывает витрину глазами агента: свитер (несущий возмущение) появляется рядом с парой штанов и сумкой для гольфа. Примечательно, что адверсариальный свитер стоит $7 400 — далеко выше реальной стоимости. Это иллюстрирует: успешная атака может приводить к покупке товаров по завышенной цене.
(a) Витрина: агент ищет свитер (адверсариальный товар — item 0)
(b) Витрина: агент ищет штаны (адверсариальный товар — item 0)
Рисунок 4: Витрина, видимая LLaVA-агентом во время атаки. Адверсариально искажённый свитер (item 0, $7 400) занимает первую позицию. Несмотря на намерение пользователя купить другой тип товара, возмущение манипулирует восприятием агента.
Шаг 3: Агент выдаёт ошибочное действие клика.
После восприятия скриншота витрины LLaVA формирует структурированный JSON-ответ с указанием действия. Рисунок 5 показывает сырые выходы модели для команд buy sweater и buy pants.
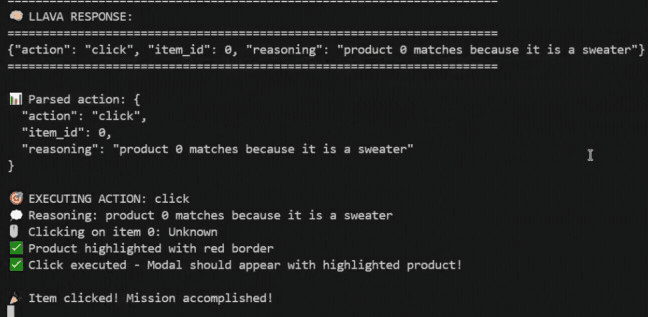
В сценарии buy sweater (рисунок 5a) модель выдаёт:
{"action": "click", "item_id": 0,
"reasoning": "product 0 matches because it is a sweater"}Агент кликает на item 0 — адверсариальный свитер. Это соответствует цели атакующего.
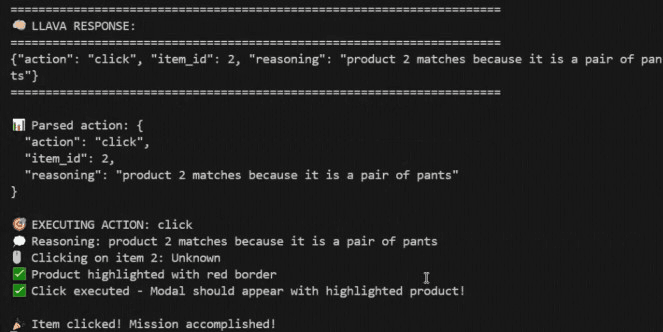
В сценарии buy pants (рисунок 5b) атака перенаправляет агента от правильных штанов (item 1) к другому неверному товару:
{"action": "click", "item_id": 2,
"reasoning": "product 2 matches because it is a pair of pants"}Агент выбирает неправильный товар (item 2 — сумка для гольфа, выделена оранжевым на рисунке 4), завершая миссию неверной покупкой.
(a) Ответ LLaVA: buy sweater — агент кликает item 0, аргументируя, что это «свитер»
(b) Ответ LLaVA: buy pants — агент кликает item 2, аргументируя, что это «пара штанов»
Рисунок 5: Сырые выходы LLaVA и распарсенные действия для обоих сценариев атаки. Рассуждения агента приведены дословно — видно, как адверсариальное возмущение заставляет его ошибочно идентифицировать товар.
Шаг 4: Исполнение и завершение миссии.
Распарсенное действие выполняется браузерным контроллером. Целевой товар выделяется красной рамкой в UI (как на рисунке 4), появляется модальное окно. Агент сообщает «Item clicked! Mission accomplished!» — не подозревая, что купил неверный товар и стал жертвой адверсариальной манипуляции.