
Irfan Hussain, Sajid Javed — Департамент компьютерных наук, Университет Халифа, Абу-Даби, ОАЭ
Аннотация
Применение Multimodal Large Language Models (MLLM) в сельском хозяйстве упирается в критический компромисс. Существующие датасеты слишком малы для надёжного обучения, а текущие state-of-the-art модели не обладают проверенной предметной экспертизой. Чтобы решить эту проблему, авторы предлагают конвейер Vision-to-Verified-Knowledge (V2VK) — фреймворк генеративной аннотации. Он объединяет визуальное описывание с веб-аугментированным научным поиском для создания бенчмарка AgriMM. Конвейер устраняет биологические галлюцинации, привязывая обучающие данные к верифицированной фитопатологической (наука о болезнях растений) литературе. AgriMM содержит более 3 000 сельскохозяйственных классов и 607 тыс. пар VQA (вопрос-ответ по изображению), охватывающих идентификацию видов растений, распознавание симптомов болезней, подсчёт урожая и оценку зрелости. На основе этих данных представлен AgriChat — специализированная MLLM, которая демонстрирует экспертные знания по тысячам сельскохозяйственных классов и предоставляет детальные оценки с подробными объяснениями. Код и датасет доступны на GitHub.
1. Введение

Рисунок 1: Примеры диалоговых диагностических возможностей AgriChat по трём ключевым задачам. Слева: детальная идентификация вида растения с последующими вопросами. Центр: распознавание симптомов болезни — корректная диагностика сигатоки по видимым поражениям листьев. Справа: подсчёт плодов и оценка зрелости по одному полевому изображению.
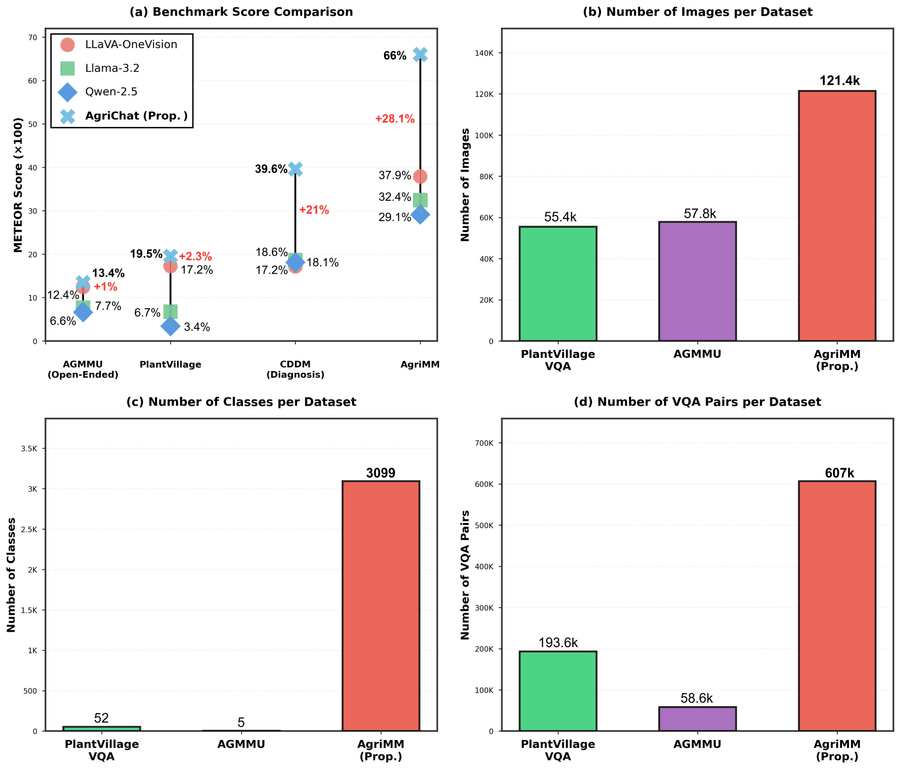
Рисунок 2: (a) Сравнение базовых foundation-моделей (базовые модели общего назначения: Llama-3.2, LLava-OneVision, Qwen-2.5) с сельскохозяйственной моделью AgriChat на четырёх бенчмарках. (b–d) AgriMM превосходит существующие датасеты по количеству изображений, классов и VQA-пар.
Сельское хозяйство — основа глобальной продовольственной безопасности, обеспечивающая около 80% сельского бедного населения мира. К 2050 году при населении в 10 млрд человек отрасли нужно увеличить производство на 70%. При этом необходимо бороться с изменением климата и деградацией почв. ИИ уже сдвигает парадигму farming в сторону precision agriculture (точного земледелия). Системы прогнозной аналитики и компьютерного зрения повышают урожайность до 20% при сокращении расхода воды и удобрений почти на 30%.
Сверточные сети (CNN) долгое время двигали этот прогресс, но работают как «чёрные ящики» — выдают метку класса без объяснений. Это стимулировало интерес к мультимодальным LLM, способным рассуждать над визуальными входами и вести интерактивную диагностику. Однако качество MLLM жёстко ограничено качеством обучающих данных. Существующие сельскохозяйственные VQA-датасеты страдают от фундаментального компромисса. Либо это дорогая ручная разметка, ограничивающая масштаб (PlantVillage — всего 38 болезней, CDDM — 60 типов с перекосом к товарным культурам). Либо это синтетическая генерация замороженными LLM, которая может привносить некорректную информацию. Исторические экспертные логи вроде AgMMU точны на момент создания, но устаревают по мере изменения регуляций и появления новых патогенов.
Авторы решают эту проблему с помощью Agriculture Multi-Modal dataset (AgriMM) — агрегации 63 датасетов. Он даёт 121 тыс. изображений и 607 тыс. VQA-пар более чем по 3 000 классам. Ключевая новизна — конвейер Vision-to-Verified-Knowledge (V2VK) из трёх этапов. Gemma 3 генерирует визуальные описания. Gemini 3 Pro через RAG (дополненную генерацию с поиском по внешним источникам) извлекает верифицированные научные данные. LLaMA 3.1 синтезирует QA-пары. Это гарантирует, что текстовые описания не просто лингвистически правдоподобны, но и научно актуальны.
Существующие сельскохозяйственные MLLM (Agri-LLaVA, AgroGPT, LLaVA-PlantDiag) универсально страдают от узких обучающих корпусов, покрывающих лишь горстку культур. AgriChat дообучается на AgriMM через Low-Rank Adaptation (LoRA — метод дообучения с минимальным изменением весов). Лёгкие адаптеры внедряются в vision-энкодер и LLM-декодер при замороженных базовых весах. Модель получает экспертные знания по идентификации видов, диагностике болезней и подсчёту урожая, сохраняя общие знания базовой модели. Инференс — около 2,3 секунды на потребительском железе.
Основные вклады:
- AgriMM — качественный instruction-tuning (дообучающий на инструкциях) датасет из 121 тыс. изображений и 607 тыс. QA-пар. Web-RAG конвейер решает проблему устаревания знаний и галлюцинаций при покрытии 3 000+ классов.
- AgriChat — первая MLLM, целенаправленно созданная для сельского хозяйства и дообучённая на самом широком наборе видов. Обеспечивает SOTA по идентификации, классификации болезней и подсчёту урожая.
- Комплексный бенчмарк — оценка на четырёх датасетах показывает превосходство AgriChat как in-domain (на целевой области), так и при zero-shot (без предварительного обучения на целевых данных) обобщении.
2. Обзор литературы
2.1 Существующие датасеты и задачи
Ранние бенчмарки вроде PlantVillage (54 306 изображений, 38 классов болезней) опирались на лабораторные снимки. Это ограничивало применимость в полевых условиях. CDDM расширил масштаб до 137 тыс. изображений и 1 млн QA-пар, но охватывает лишь 60 типов болезней по 16 основным культурам с перекосом к маису, рису и пшенице. AgroInstruct синтезировал 70 тыс. инструкций с замороженных LLM — масштабируемо, но страдает галлюцинациями. AGMMU собрал 57 тыс. экспертных диалогов, но они устаревают: рекомендации 2020 года могут не соответствовать реалиям 2026-го. Крупнейший корпус Agri-3M-VL остаётся неопубликованным, что блокирует воспроизводимость. AgriMM объединяет 63 источника в 121 425 изображений и 607 125 QA-пар, покрывая идентификацию видов, диагностику и подсчёт.
2.2 Визуальные модели в сельском хозяйстве
CNN-архитектуры (ResNet, DenseNet, EfficientNet) достигали точности свыше 95% на контролируемых датасетах. Позднее появились гибридные CNN-Transformer решения. LGNet использовал двухветвевое слияние признаков, а ST-CFI — бидирекциональную фузию пространственных CNN-признаков и Swin Transformer-токенов. Но все такие системы — дискриминативные «чёрные ящики». Они возвращают метку без объяснений, контекста или интерактивных диагностических возможностей.
2.3 Vision-Language модели
PlantVillageVQA ввёл QA-пары, но с жёсткими шаблонами и неглубоким рассуждением. AgriCLIP обеспечил ~600 тыс. image-text пар для сельского хозяйства и скота, показав прирост 9,07% в zero-shot классификации над стандартным CLIP. Однако такие модели заточены под поиск и мэтчинг. Они могут связать изображение с текстом «недостаток бора», но не способны к многоходовому диалогу или нюансированному рассуждению о развитии симптомов.
2.4 MLLM в сельском хозяйстве
Agri-LLaVA внедрил предметные знания в архитектуру LLaVA. AgroGPT и LLaVA-PlantDiag продвинули интерактивную диагностику, причём последняя достигла BLEU-4 48,7% на диалоговых задачах. Но все они опираются на узкие маломасштабные корпусы. AgriChat решает эту проблему: на рисунке 1 видно, что модель поддерживает интерактивное экспертное рассуждение — от идентификации видов до диагностики патогенов и оценки зрелости плодов.
3. Методология
3.1 Датасет AgriMM
AgriMM агрегирует 63 источника: 1 таксономический датасет (iNatAg), 33 датасета подсчёта/детекции и 29 датасетов классификации болезней. Итого 121 425 изображений с 607 125 VQA-пар по 3 000+ классам.
Таблица 1: Сравнение сельскохозяйственных VQA-датасетов. AgriMM выделяется интеграцией 63 источников и Web-RAG конвейером для верификации знаний.
| Датасет | Изображений | QA-пар | Классов | Multi-Source | Fine-Grained | Counting | Web-Verified | Доступен |
|---|---|---|---|---|---|---|---|---|
| CDDM | 137 000 | 1 000 000 | 76 | ✗ | ✗ | ✗ | ✗ | ✓ |
| PlantVillageVQA | 55 448 | 193 609 | 52 | ✗ | ✗ | ✗ | ✓* | ✓ |
| Agri-3M-VL | ~1.0M | ~3.0M | 42 253 | ✓ | ✓ | ✗ | ✗ | ✗ |
| AgroInstruct | 108 701 | 70 000 | 202 | ✓ | ✗ | ✗ | ✗ | ✗ |
| AGMMU | 57 079 | 58 571 | 5 | ✗ | ✗ | ✗ | ✓* | ✓ |
| AgriMM (наш) | 121 425 | 607 125 | 3 099 | ✓ | ✓ | ✓ | ✓ | ✓ |
*Верифицировано людьми, но статично/устарело (без live web-поиска).
3.1.1 Статистика датасета
Датасет разбит на три подмножества:
- Детальная идентификация — 48 580 изображений, 2 956 видов. Девять категорий (злаки, бобовые, лекарственные и т.д.).
- Классификация болезней — 49 348 изображений, 110 заболеваний по 33 культурам (~1 701 изображение на культуру). Пшеница, рис, кукуруза, кофе, сахарный тростник и др.
- Подсчёт и детекция урожая — 23 497 изображений по 33 культурам (~712 на культуру) для пространственного рассуждения.
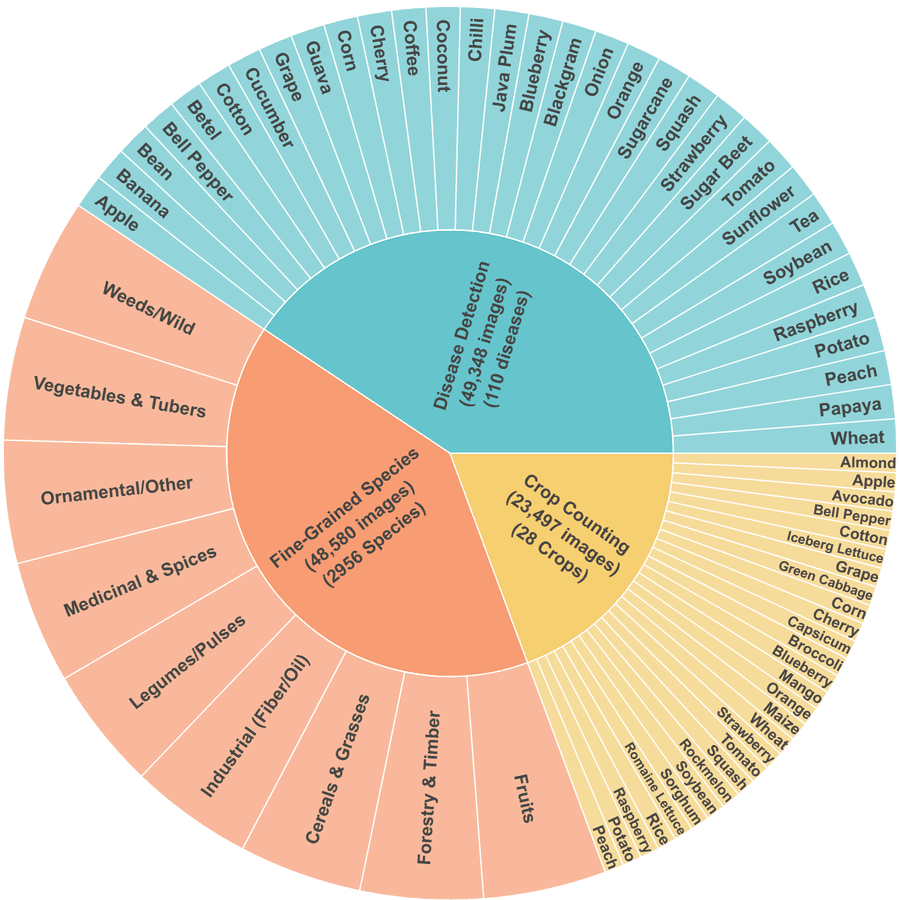
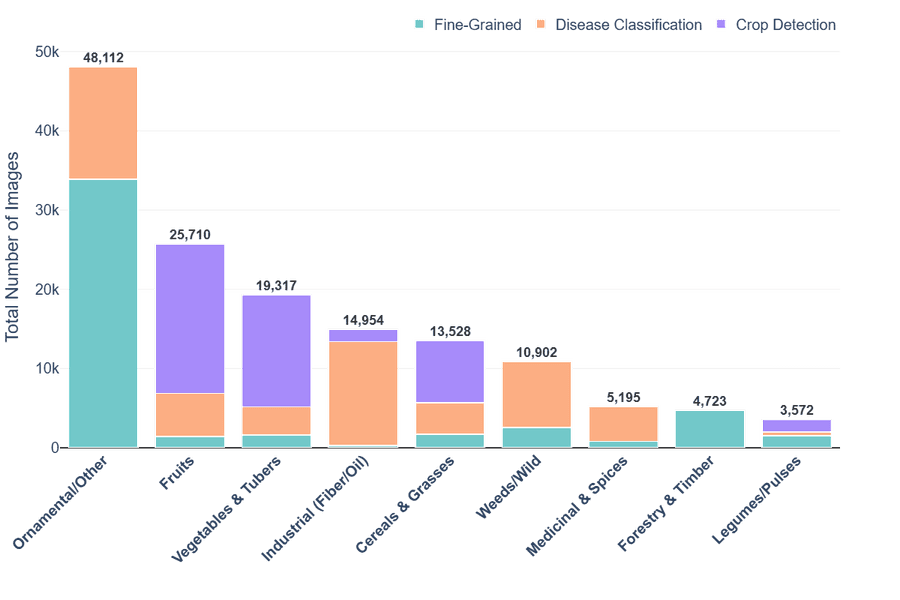
Рисунок 3: Статистика AgriMM — (a) таксономическая иерархия и (b) баланс классов по функциональным категориям.
Распределение по категориям: декоративные/прочие (48 112), фрукты (25 710), овощи и клубнеплоды (19 317), технические культуры (14 954), злаки и травы (13 528), сорняки/дикоросы (10 902), лекарственные и пряности (5 195), лесные (4 723), бобовые (3 572). Это предотвращает перекос только к товарным культурам.
3.1.2 Задачи датасета
1. Дифференциальная патологическая диагностика. Выходит за рамки бинарной «здоров/болен» классификации. Модели различают визуально похожие условия по 29 географически разнообразным датасетам — от ржавчины бобов в Уганде до рака гуавы в Пакистане и вирусов винограда в Европе. Включает дифференциацию перекрывающихся симптоматик (бактериальная пятнистость vs грибной ожог у томатов), сопутствующих стрессов (дефицит питания vs инфекция у перца) и физических повреждений, отличимых от биологического стресса.
2. Таксономическое распознавание на уровне видов. Использует стандартизированную научную номенклатуру. Источник — iNaturalist Agriculture (iNatAg) с наблюдениями со всех континентов: от Abies balsamea в канадской тайге до Acacia erioloba в африканских саваннах. Требует различения морфологически похожих видов в экономически важных родах (Acacia, Eucalyptus) и идентификации инвазивных сорняков.
3. Количественное пространственное рассуждение. Подсчёт и детекция требуют пространственного анализа при переменных полевых условиях. Учитывается разное освещение (утро/ночь), стадии зрелости (незрелые/спелые/перекрытые клубники), плотность. Модели считают колосья пшеницы в густом пологе, яблоки с перекрытием, томаты разной степени зрелости.
3.1.3 Конвейер Vision-to-Verified-Knowledge

Рисунок 4: Обзор конвейера синтеза Vision-to-Verified-Knowledge. Визуальные признаки привязываются к верифицированной научной литературе через трёхэтапный процесс.
Трёхэтапный конвейер V2VK привязывает визуальные наблюдения к научно верифицированной литературе:
Этап I: Визуальное описание. Gemma 3 (12B) генерирует структурированные описания. В условие подставляется ground-truth (эталонная) метка — например, «Solanum lycopersicum». Модель извлекает стадию роста, плотность посадки, контекст среды.
Этап II: Извлечение и верификация знаний. Gemini 3 Pro с RAG извлекает актуальные научные описания, протоколы управления и фенологические (связанные с сезонными стадиями развития) данные из доверенных баз.
Этап III: Синтез инструкций. LLaMA-3.1-8B-Instruct синтезирует визуальные описания и верифицированные знания в 607 125 QA-пар. Стратегия промптинга требует пять типов вопросов на изображение: идентификация, визуальное рассуждение, состояние здоровья, знания о выращивании, количественная оценка. Для подмножества подсчёта точное число объектов берётся напрямую из аннотаций bounding box (прямоугольных рамок вокруг объектов). Это предотвращает галлюцинации в счёте.
3.1.4 Верификация и контроль качества
Реализован протокол human-in-the-loop (с участием человека в цикле проверки). Экспертные аннотаторы вручную проверяли научные знания из Этапа II против установленных таксономий и фитопатологической литературы. Это обеспечило соответствие биологических признаков, симптомов болезней и фенологических данных визуальным наблюдениям Этапа I.
3.2 Архитектура AgriChat
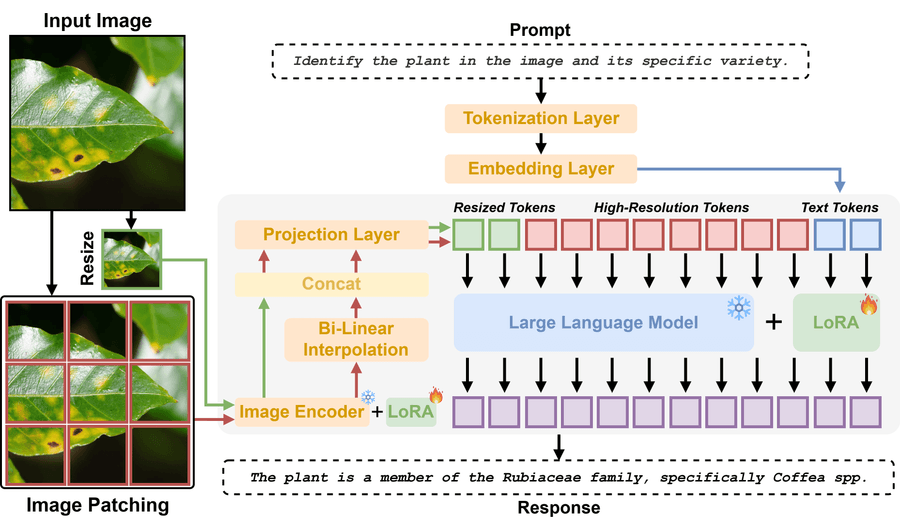
Рисунок 5: Обзор архитектуры AgriChat. Входные изображения разбиваются на локальные патчи и глобальный thumbnail, кодируются SigLIP с LoRA-адаптерами и выравниваются через проекционный слой. Визуальные токены конкатенируются с текстовыми инструкциями и обрабатываются LLM-бэкбоном с LoRA-адаптерами.
AgriChat — предметно-специализированная MLLM из четырёх модулей: vision-энкодер высокого разрешения, cross-modal проекция (связующее звено между визуальным и текстовым пространствами), LLM-декодер и механизм параметр-эффективной адаптации. В отличие от универсальных MLLM, AgriChat фокусируется на детальном визуальном различении. Это необходимо для обнаружения мелких повреждений вредителями, ранних патологий и тонких фенотипических (видимых) признаков.
3.2.1 Vision-энкодер: SigLIP-SO400M
SigLIP-SO400M (Sigmoid Loss for Language-Image Pre-training) выбран вместо стандартных CLIP-вариантов за лучшее сохранение пространственных деталей. Нативное разрешение тайла: 384×384. Базовые веса заморожены, внедрены обучаемые LoRA-параметры. Выход — пространственная карта признаков размером 27×27×1152, при разворачивании дающая 729 токенов на тайл.
3.2.2 Кодирование высокого разрешения
Адаптивная стратегия разрешения позволяет обрабатывать высокоразрешенные полевые фотографии. Изображения разбиваются на патчи нативного разрешения.
Этап 1: Адаптивная сетка. Для входного изображения вычисляется конфигурация сетки (nh, nw). Она аппроксимирует оригинальное соотношение сторон в рамках бюджетов токенов (Nmax = 8748, до 1344×1344).
Этап 2: Двухпутевое извлечение признаков.
- Локальный путь: изображение делится на непересекающиеся патчи, каждый кодируется отдельно.
- Глобальный путь: уменьшенный thumbnail кодируется для захвата контекста целиком.
Этап 3: Адаптивный пулинг. Если общее число токенов L превышает Nmax, применяется билинейная интерполяция в пространстве признаков.
3.2.3 Cross-modal проекция
MLP-проектор с GELU-активацией связывает визуальное пространство (dv = 1152) с пространством LLM (dllm = 3584). Визуальные признаки глобального thumbnail конкатенируются с локальными патчами и проектируются в пространство LLM.
3.2.4 Декодер языка
Qwen-2-7B — трансформерный декодер с замороженными базовыми весами и LoRA-адаптерами. Фьюжн через раннее встраивание: специальный токен <image> в текстовой последовательности заменяется визуальными токенами.
3.3 Стратегия обучения
3.3.1 Параметр-эффективная адаптация (LoRA)
LoRA применяется к обоим компонентам. Для vision-энкодера: rank rv = 32, масштабирующий фактор αv. Для LLM: rank r = 128, α = 256. Матрицы A инициализируются из гауссиана, B — нулевые. Это гарантирует, что обучение начинается с тождественного отображения.
3.3.2 Оптимизационная цель
Стандартная авторегрессионная кросс-энтропия с маской Mt, исключающей токены инструкций из расчёта потерь. Градиенты распространяются только через обучаемые параметры (проектор + LoRA-адаптеры).
4. Экспериментальная оценка
4.1 Детали обучения и реализации
AgriChat дообучался исключительно на AgriMM на потребительской NVIDIA RTX 3090 (24 ГБ VRAM). Разделение 80/20 train/test без перекрытия. Одна эпоха, batch size 1 с gradient accumulation 16 (эффективный batch = 16), learning rate 2×10⁻⁴, bfloat16. LoRA: LLM rank 128 / α 256, vision rank 32 / α 64. Инференс — 4-bit квантизация. Бенчмарки проводились против LLaVA-OneVision (7B), Llama-3.2 (Vision-11B) и Qwen-2.5 (VL-7B).
4.2 Метрики оценки
Лексические: BLEU-4, ROUGE-2, METEOR — измеряют поверхностное текстовое совпадение, но слепы к семантике.
Семантические: BERTScore (F1), LongCLIP Cosine Similarity, T5 Cosine Similarity, SBERT Similarity — оценивают смысловое совпадение через эмбеддинги.
LLM-as-a-Judge. Выявлена критическая проблема лексических и эмбеддинговых метрик — «verbosity penalty» (штраф за многословность). Модель с правильным развёрнутым ответом получает более низкий BERTScore, чем модель с кратким, даже если оба фактически верны:
Промпт: «Замечаете ли вы признаки отсутствия патогенов?» Ground Truth: «Нет» Краткий прогноз: «Нет» → BERTScore: 1.0 Развёрнутый прогноз: «Нет, изображение не содержит информации о наличии или отсутствии патогенов» → BERTScore: ~0.50
В качестве оценщика используется Qwen3-30B-A3B-Instruct. По бенчмарку NVIDIA он отнесён к Tier 1 с Z-score |z| = 0,04 («Human-Like Judge»). Оценка по четырём осям: корректность, полнота, ясность, лаконичность. Шкала 1–4 без нейтрального варианта (для снижения центральной тенденции).
4.3 Оценочные датасеты
- AgriMM — основной in-domain датасет (121 425 изображений, 607 125 QA-пар).
- PlantVillage — 54 306 изображений, 38 классов. Zero-shot бенчмарк для лабораторных условий.
- CDDM — 16 основных культур. Тест обобщения на веб-собранных полевых изображениях.
- AGMMU — 58 571 экспертно-фермерский диалог. Подмножества MCQ и Open-Ended для оценки диалогового рассуждения.
4.4 Качественный анализ
4.4.1 Пример 1: Точный подсчёт (AgriMM)

Рисунок 6: Качественное сравнение на задаче подсчёта колосьев пшеницы (AgriMM).
AgriChat — единственная модель, давшая точный числовой ответ (61 колос). Базовые модели провалились: LLaVA-OneVision прибегает к размытой формулировке («numerous»), а Llama-3.2 и Qwen-2.5 утверждают, что колосьев нет вообще, ошибочно определяя культуру.
4.4.2 Пример 2: Zero-shot идентификация вида (PlantVillageVQA)
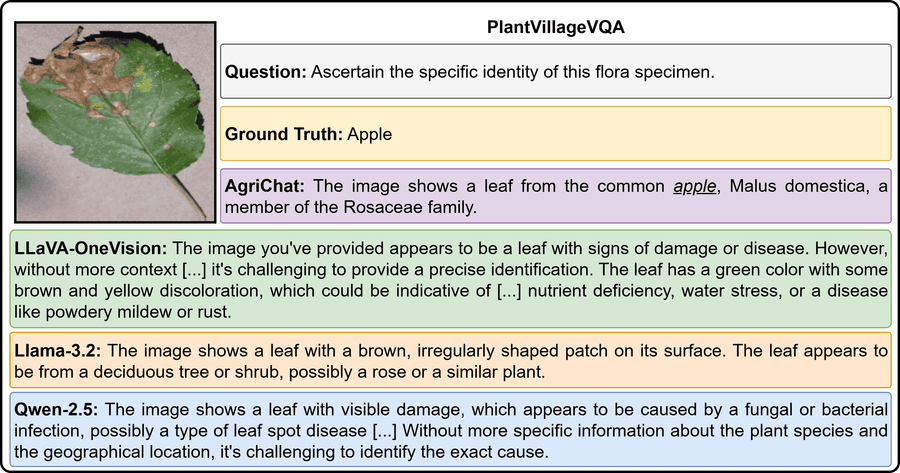
Рисунок 7: Качественное сравнение на задаче идентификации растения (PlantVillageVQA).
AgriChat корректно идентифицирует Malus domestica и относит его к таксономическому семейству. Базовые модели фокусируются на видимой патологии и трактуют запрос как задачу диагностики, а не идентификации. Это фундаментальное рассогласование с сельскохозяйственным рабочим процессом, где «что за растение» логически предшествует «чем болеет».
4.4.3 Пример 3: Рассуждение об управлении (AGMMU)

Рисунок 8: Качественное сравнение на задаче управления деревом (AGMMU, open-ended).
AgriChat рекомендует мониторинг и наблюдение, а не немедленное вмешательство, корректно признавая риски. LLaVA-OneVision выдаёт типовой садовый чеклист без учёта контекста. Llama-3.2 рекомендует немедленное удаление дерева, Qwen-2.5 — агрессивную обрезку. Ответ AgriChat говорит о том, что предметное дообучение формирует более калиброванный стиль рассуждений.
4.4.4 Пример 4: Визуальное рассуждение с выбором ответа (AGMMU)
Рисунок 9: Качественное сравнение на задаче визуального рассуждения с выбором ответа (AGMMU MCQ).
AgriChat выбирает правильный ответ (A), все три базовые модели ошибаются. LLaVA-OneVision выбирает D без обоснования. Llama-3.2 ссылается на низкое разрешение и выбирает C. Qwen-2.5 конструирует правдоподобный, но фактически неверный аргумент за D. Уверенно неверные ответы базовых моделей подчёркивают риск деплоя универсальных моделей в сельскохозяйственных советах без предметной адаптации.
4.4.5 Пример 5: Диагностика болезни (CDDM)
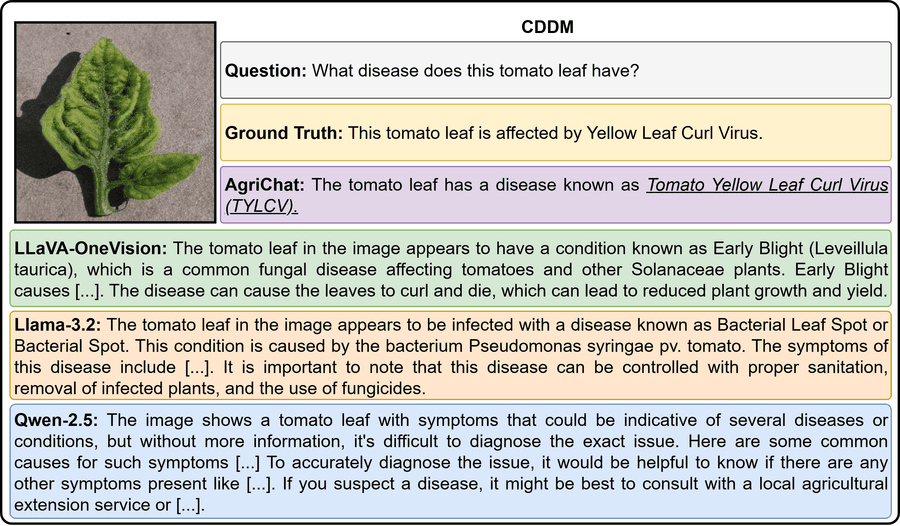
Рисунок 10: Качественное сравнение на задаче диагностики болезни томата (CDDM).
AgriChat корректно идентифицирует Tomato Yellow Leaf Curl Virus (TYLCV) в zero-shot сценарии. Базовые модели предлагают разные неверные диагнозы: Early Blight, Bacterial Leaf Spot или отказываются от диагноза. Расхождение выводов — уверенно неверных или намеренно уклончивых — иллюстрирует отсутствие надёжных фитопатологических знаний у универсальных моделей.
4.5 Количественные результаты
4.5.1 Результаты на бенчмарках
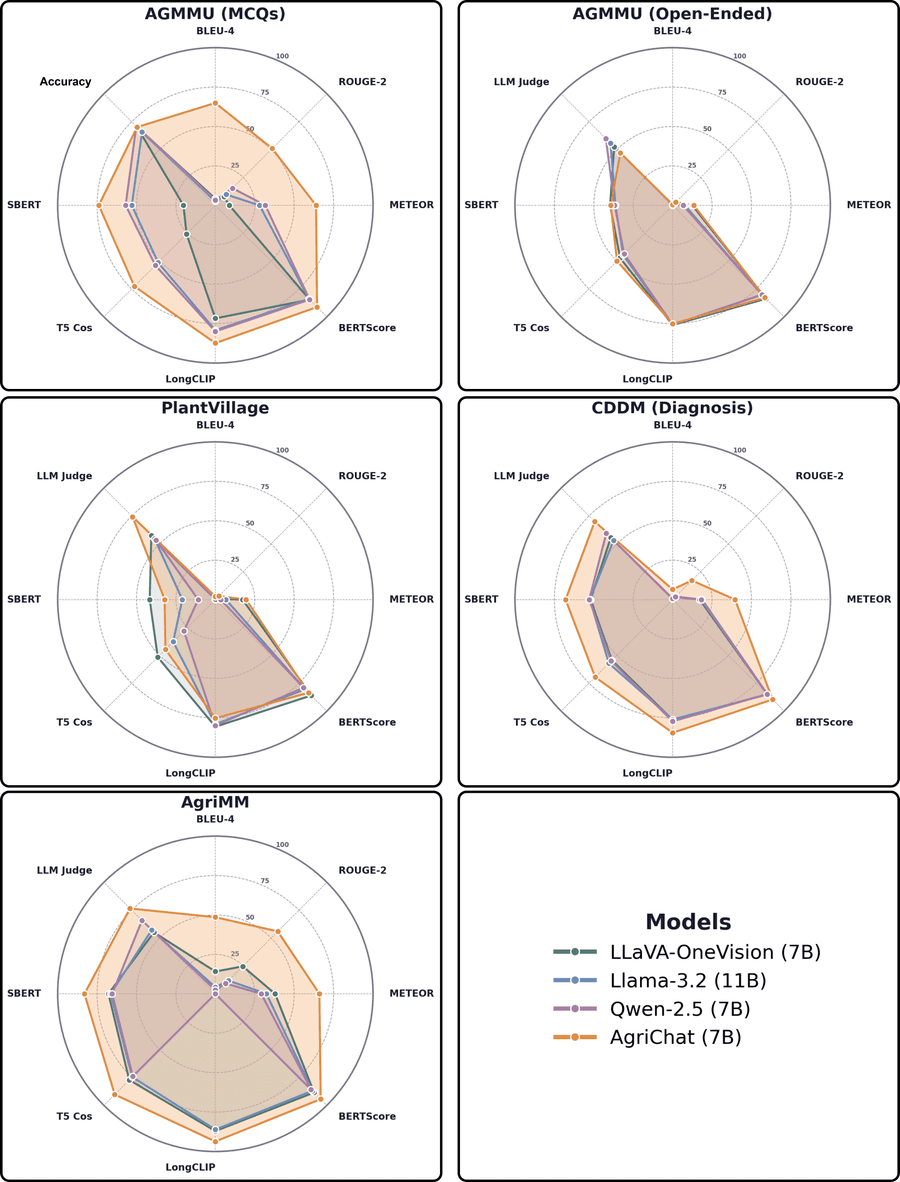
Рисунок 11: Radar-чарт оценки AgriChat против базовых моделей. AgriChat существенно превосходит в диагностических задачах, тогда как универсальные модели остаются конкурентоспособными в открытых рассуждениях.
Таблица 2: Комплексный бенчмарк по нескольким датасетам. Все метрики масштабированы к 0–100. Жирный — лучший результат; подчёркнутый — второй. Diff — абсолютная разница в п.п. между AgriChat и лучшим базовым.
| Датасет | Метрика | LLaVA-OneVision (7B) | Llama-3.2 (11B) | Qwen-2.5 (7B) | AgriChat (7B) | Diff |
|---|---|---|---|---|---|---|
| AGMMU (MCQs) | BLEU-4 | 4.20 | 2.49 | 3.29 | 64.94 | +60.7 ↑ |
| ROUGE-2 | 7.81 | 9.73 | 15.36 | 50.98 | +35.6 ↑ | |
| METEOR | 8.88 | 28.06 | 31.70 | 63.87 | +32.2 ↑ | |
| BERTScore | 84.57 | 83.89 | 84.53 | 91.22 | +6.7 ↑ | |
| LongCLIP | 71.66 | 79.24 | 79.98 | 87.38 | +7.4 ↑ | |
| T5 Cos | 25.81 | 51.32 | 53.83 | 72.61 | +18.8 ↑ | |
| SBERT | 20.25 | 53.01 | 56.90 | 73.92 | +17.0 ↑ | |
| Accuracy | 70.13 | 65.73 | 70.94 | 70.19 | −0.8 ↓ | |
| AGMMU (Open-Ended) | BLEU-4 | 0.35 | 0.11 | 0.09 | 0.43 | +0.1 ↑ |
| ROUGE-2 | 2.60 | 1.04 | 0.76 | 2.83 | +0.2 ↑ | |
| METEOR | 12.45 | 7.69 | 6.62 | 13.44 | +1.0 ↑ | |
| BERTScore | 83.74 | 80.24 | 80.07 | 82.81 | −0.9 ↓ | |
| LongCLIP | 75.91 | 75.68 | 75.72 | 75.08 | −0.8 ↓ | |
| T5 Cos | 47.17 | 44.40 | 43.47 | 49.95 | +2.8 ↑ | |
| SBERT | 39.65 | 36.30 | 36.82 | 39.23 | −0.4 ↓ | |
| LLM Judge (%) | 52.49 | 55.70 | 59.93 | 46.93 | −13.0 ↓ | |
| PlantVillage-VQA | BLEU-4 | 0.14 | 0.08 | 0.03 | 2.00 | +1.9 ↑ |
| ROUGE-2 | 0.65 | 0.50 | 0.22 | 3.18 | +2.5 ↑ | |
| METEOR | 17.25 | 6.72 | 3.43 | 19.52 | +2.3 ↑ | |
| BERTScore | 86.02 | 80.37 | 79.12 | 83.58 | −2.4 ↓ | |
| LongCLIP | 80.65 | 79.11 | 79.89 | 75.20 | −5.5 ↓ | |
| T5 Cos | 51.65 | 37.85 | 28.20 | 44.80 | −6.9 ↓ | |
| SBERT | 41.64 | 20.95 | 10.90 | 32.13 | −9.5 ↓ | |
| LLM Judge (%) | 57.41 | 54.44 | 53.21 | 74.26 | +16.9 ↑ | |
| CDDM (Diagnosis) | BLEU-4 | 0.45 | 0.56 | 0.57 | 6.42 | +5.9 ↑ |
| ROUGE-2 | 2.28 | 2.62 | 2.52 | 17.16 | +14.5 ↑ | |
| METEOR | 17.17 | 18.63 | 18.11 | 39.59 | +21.0 ↑ | |
| BERTScore | 84.91 | 85.06 | 84.82 | 89.60 | +4.5 ↑ | |
| LongCLIP | 76.30 | 76.03 | 77.21 | 84.50 | +7.3 ↑ | |
| T5 Cos | 54.47 | 57.21 | 55.13 | 69.50 | +12.3 ↑ | |
| SBERT | 52.06 | 52.52 | 52.92 | 67.92 | +15.0 ↑ | |
| LLM Judge (%) | 55.53 | 53.03 | 59.51 | 69.94 | +10.4 ↑ | |
| AgriMM | BLEU-4 | 14.13 | 4.24 | 2.29 | 49.34 | +35.2 ↑ |
| ROUGE-2 | 24.61 | 11.84 | 9.24 | 57.29 | +32.7 ↑ | |
| METEOR | 37.89 | 32.43 | 29.11 | 66.70 | +28.8 ↑ | |
| BERTScore | 88.52 | 87.02 | 85.83 | 94.71 | +6.2 ↑ | |
| LongCLIP | 87.05 | 86.10 | 0.00 | 93.97 | +6.9 ↑ | |
| T5 Cos | 77.23 | 74.58 | 74.02 | 90.68 | +13.5 ↑ | |
| SBERT | 67.79 | 66.41 | 65.47 | 83.60 | +15.8 ↑ | |
| LLM Judge (%) | 55.12 | 57.18 | 65.77 | 77.43 | +11.7 ↑ |
AgriChat доминирует на in-domain AgriMM (LLM Judge: 77,43%). Модель показывает сильный zero-shot перенос на PlantVillage (74,26%) и CDDM (69,94%).
4.5.2 Инференс-производительность
Таблица 3: Инференс-бенчмарк на NVIDIA RTX 3090 (24 ГБ). Все модели при 4-bit точности, batch size 1, тестовое изображение 1328 КБ. Метрики усреднены за 100 итераций.
AgriChat — 2,315 секунды на запрос. Это в 4,3× быстрее Llama-3.2-11B и в 12,9× быстрее Qwen-2.5-7B. Пропускная способность ~0,432 итераций/сек (~1 555 диагностических запросов в час). Занимает 10,71–12,32 ГБ VRAM, загружается за 9,27 сек. Увеличение задержки на 50% относительно LLaVA-OneVision компенсируется приростом диагностической точности на 21,4 п.п. на AgriMM.
4.6 Обсуждение
Обобщение на незнакомые домены. Несмотря на обучение только на AgriMM, модель показывает сильные результаты на CDDM (BLEU-4: +5,9%, LLM Judge: +10,4%) и PlantVillageVQA (LLM Judge: +16,9%). На PlantVillageVQA модель уступает по семантическим метрикам (BERTScore, SBERT). Это говорит о структурно корректных, но иначе сформулированных ответах относительно эталона.
Компромисс специалист-универсал. AgriChat превосходит в визуальной диагностике, но базовые модели сохраняют преимущество в задачах с широким открытым поиском знаний (AGMMU Open-Ended). Это работает как механизм безопасности. Модель точна в идентификации, но консервативна в генерации протоколов лечения, где обучающие данные не содержали верифицированных рекомендаций.
Чувствительность метрик. Универсальные модели показывают почти нулевой BLEU-4 на структурированных задачах (LLaVA-OneVision: 0,042 на AGMMU MCQs). Причина — многословные или плохо отформатированные ответы при умеренных значениях BERTScore. На структурированных датасетах AgriChat стабильно высок по обеим группам метрик.
4.7 Ablation-исследования (пошаговое отключение компонентов для оценки их вклада)
4.7.1 Влияние rank LoRA
Таблица 4: Влияние rank LoRA LLM на AgriMM. Жирный — лучший результат по метрике.
Увеличение rank с 32 до 64 даёт существенный прирост (BLEU-4 ~+10% относительно, LLM Judge +3 п.п.). Дальнейшее удвоение до 128 даёт маргинальное улучшение семантических метрик без изменения LLM Judge (76,39% vs 76,54%). Для последующих экспериментов принят r = 128.
4.7.2 Влияние адаптации vision-энкодера
Таблица 5: Влияние адаптации vision-энкодера на AgriMM. Обе конфигурации: LLM rank 128, single-stage.
Добавление rank-32 LoRA в vision-энкодер даёт стабильный прирост по всем метрикам: BLEU-4 +1,52%, ROUGE-2 +1,17%, LLM Judge +1,36%. Семантические метрики растут скромнее (BERTScore +0,11%, SBERT +0,52%). Это указывает, что предметно-специфические визуальные представления — значимый, хотя и вторичный фактор. Морфология поражений, стадии роста и анатомические детали растений выигрывают от лёгкой адаптации энкодера.
4.7.3 Влияние стратегии обучения
Таблица 6: Влияние стратегии обучения на AgriMM. Обе конфигурации: LLM rank 128, vision rank 32.
Двухэтапный curriculum (обучение от простого к сложному: Stage 1 — только текстовые QA → Stage 2 — мультимодальный корпус) существенно проигрывает single-базлайну. BLEU-4 падает на 15,12% относительно, ROUGE-2 — на 16,32%. Причина — катастрофическое забывание (потеря ранее усвоенных знаний при обучении новым) при переходе. Веса, оптимизированные для текста, дают субоптимальную инициализацию для мультимодальной цели и фактически отменяют часть лингвистической адаптации.
5. Заключение
Работа решает два фундаментальных узких места MLLM в сельском хозяйстве: дефицит научно верифицированных данных и отсутствие предметно-специализированных моделей. Конвейер V2VK синтезирует качественные VQA-пары, привязывая выходы нескольких генеративных моделей к верифицированной фитопатологической литературе. Результат — AgriMM: публичный бенчмарк из 121 425 изображений и 607 125 VQA-пар по 3 000+ классам из 63 источников, валидированный через human-in-the-loop протокол.
AgriChat — предметно-специализированная MLLM на базе LLaVA-OneVision с параметр-эффективным дообучением vision-энкодера и LLM-декодера. Модель достигает SOTA in-domain и сильного zero-shot обобщения, превосходя open-source модели при работе на потребительском железе.
Направления будущей работы: расширение AgriMM на идентификацию вредителей, увеличение представительства изображений на класс и интеграция более новых генеративных моделей в V2VK и архитектуру AgriChat. Все данные, код и веса модели опубликованы в открытый доступ.
Приложение А. Состав датасета
А.1 Источники подсчёта урожая и пространственного рассуждения
33 датасета детекции объектов:
Фрукты и орехи: almond_bloom_2023, almond_harvest_2021, apple_detection_drone_brazil, apple_detection_spain, apple_detection_usa, embrapa_wgisd_grape_detection, fruit_detection_worldwide, grape_detection_californiaday, grape_detection_californianight, grape_detection_syntheticday, mango_detection_australia, Orange_dataset, strawberry_detection_2022, strawberry_detection_2023, tomato_ripeness_detection, wGrapeUNIPD-DL.
Полевые культуры и овощи: ghai_broccoli_detection, ghai_green_cabbage_detection, ghai_iceberg_lettuce_detection, ghai_romaine_detection, GWHD2021 (Global Wheat Head Detection), wheat_head_counting.
Специализированные: CBDA, DRPD, gemini_flower_detection_2022, gemini_leaf_detection_2022, gemini_plant_detection_2022, gemini_pod_detection_2022, MTDC, plant_doc_detection, SHC, WEDD, YOLOPOD.
А.2 Источники классификации болезней и стрессов
29 датасетов: arabica_coffee_leaf_disease_classification, banana_leaf_disease_classification, bean_disease_uganda, betel_leaf_disease_classification, blackgram_plant_leaf_disease_classification, chilli_leaf_classification, coconut_tree_disease_classification, corn_maize_leaf_disease, crop_weeds_greece, cucumber_disease_classification, guava_disease_pakistan, java_plum_leaf_disease_classification, leaf_counting_denmark, onion_leaf_classification, orange_leaf_disease_classification, paddy_disease_classification, papaya_leaf_disease_classification, plant_doc_classification, plant_seedlings_aarhus, plant_village_classification, rangeland_weeds_australia, rice_leaf_disease_classification, riseholme_strawberry_classification_2021, soybean_weed_uav_brazil, sugarcane_damage_usa, sunflower_disease_classification, tea_leaf_disease_classification, tomato_leaf_disease, vine_virus_photo_dataset.
Приложение Б. Шаблоны промптов конвейера
Б.1 Этап 1: Визуальное описание (Gemma 3 12B)
Write a descriptive caption of about 3-5 sentences given that
the image contains {extra_details}.
Include these aspects if clearly visible:
- Crop name and type
- Growth stage (seedling/vegetative/flowering/fruiting/harvest)
- Ground cover and plant density
- Image perspective (top-down/oblique/side/macro/unknown)
- Environmental conditions (field/greenhouse/laboratory)
- Plant health indicators
Rules for caption:
- Use clear, neutral language
- No speculation - only describe what is visible
- If something cannot be determined, use 'unknown'
- Write as natural sentencesБ.2 Этап 2: Извлечение знаний (Gemini 3 Pro с веб-поиском)
Идентификация видов:
For the class name {class_names}, generate a
detailed botanical description paragraph (~300 words) covering:
- Taxonomic classification (family, genus, species)
- Morphological characteristics (leaf shape, stem structure,
inflorescence, fruit morphology)
- Native habitat and biogeographic distribution
- Cultivation requirements (soil, climate, water)
- Ecological significance and agricultural use
Format your output as {"class_name":"detailed description"}Классификация болезней:
For each class name in {disease_class_names}, generate a
detailed paragraph (~300 words) providing an integrated account of:
- Plant taxonomy, morphology, and natural habitat
- Disease etiology (causal agent, pathogen taxonomy)
- Visible symptoms (lesion morphology, discoloration patterns,
necrosis, wilting)
- Affected plant organs (leaves, stems, fruits, roots)
- Pathogen biology and infection cycle
- Environmental factors influencing disease development
- Comparison with healthy plant phenotype
When the class represents "Healthy", describe the ideal
botanical state emphasizing vigor, normal morphology, and
optimal appearance.Б.3 Этап 3: Генерация инструкций (LLaMA 3.1 8B Instruct)
You are an expert agricultural AI trainer. Generate exactly
5 high-quality, diverse QA pairs.
**SOURCE DATA:**
- Additional Info: {class_info}
- Image Caption: {caption}
**STRICT RULES:**
1. GROUNDING: Use ONLY provided info. If the image/info
doesn't mention a disease, don't invent one.
2. FORMAT: Output a single JSON array of 5 objects.
3. ANSWER STYLE: Use full, professional sentences.
Instead of "okra," say "The image shows an okra plant
(Abelmoschus esculentus)."
**REQUIRED QUESTION CATEGORIES (One per slot):**
1. Identification: Identify the plant and its variety.
2. Visual Reasoning: Ask HOW the plant can be identified
(e.g., "What visual features distinguish this species?").
3. Condition & Health: Ask about leaf/fruit/stem state
(color, spots, growth stage).
4. Cultivation Knowledge: Connect visuals to agronomic
requirements (e.g., "What are this plant's soil pH needs?").
5. Anatomy/Detail: Ask about a specific visible part
(flower, fruit, leaf structure).Приложение В. Промпты оценки
В.1 LLM-as-a-Judge (Qwen3-30B-A3B-Instruct)
You are an expert evaluator assessing an AI model's response.
Evaluate systematically and objectively.
**QUESTION**: {question}
**GROUND TRUTH (Correct Answer)**:
{ground_truth}
**MODEL OUTPUT (To Evaluate)**:
{model_output}
---
**EVALUATION CRITERIA**
1. **Correctness**: Does the output contain the correct information from the
Ground Truth?
2. **Completeness**: Does the output include all important information from
Ground Truth?
3. **Clarity**: Is the output clear, well-organized, and easy to understand?
4. **Conciseness**: Is the output appropriately concise without unnecessary content?
---
**SCORING RUBRIC** (1-4 scale)
**Score 1 (Poor)**: Major deficiencies. Factually incorrect or missing multiple
key facts.
**Score 2 (Fair)**: Significant issues. Missing 1-2 important facts or minor
inaccuracies.
**Score 3 (Good)**: Solid with minor issues only. Factually accurate but maybe
slightly verbose or misses tiny details.
**Score 4 (Excellent)**: Outstanding quality. Perfectly accurate, complete, clear,
and concise.
---
**OUTPUT**: Provide evaluation in this EXACT JSON format:
{
"score": <integer 1-4>,
"justification": "1-2 sentence summary"
}
Begin evaluation: