
Зиян Цай — Принстонский университет
Харкират Бехл — Microsoft Research
Аннотация
С появлением AI-агентов автоматические научные открытия стали реальной целью. Многие недавние работы строят агентные системы для ML-исследований, но не предлагают системного подхода к их обучению. Текущие LLM часто генерируют правдоподобные, но неработающие идеи. Чтобы продвинуться в обучении агентов на практике, мы предлагаем новый пайплайн генерации синтетических окружений для ML-агентов. Пайплайн автоматически создаёт ML-задачи, совместимые с фреймворком SWE-agent. Он покрывает выбор тем, предложение датасетов и генерацию кода. Полученные задачи обладают двумя свойствами. Во-первых, они основаны на реальных ML-датасетах — предложенные датасеты верифицируются через HuggingFace API. Во-вторых, они проходят дополнительную проверку через цикл self-debugging (самостоятельной отладки моделью собственных ошибок). Для валидации мы используем MLGym — бенчмарк ML-задач. Из синтетических задач мы собираем примеры решений от teacher-модели (GPT-5), затем используем их для обучения student-моделей (Qwen3-4B и Qwen3-8B). Обученные модели показывают улучшение на MLGym: метрика AUP (Area Under the Performance curve) растёт на 9% для Qwen3-4B и на 12% для Qwen3-8B.
1. Введение
Одна из ключевых целей ИИ — автономно проводить научные открытия: формулировать гипотезы, проектировать и запускать эксперименты, анализировать результаты, интегрировать новые знания. Системы вроде AI Scientist, Co-Scientist и AlphaEvolve показывают, что ИИ уже способен выполнять базовые исследования и алгоритмические улучшения. При этом LLM накопили обширные знания в теории машинного обучения, литературе и паттернах кода. Но знаний недостаточно. Чтобы превратить понимание в эффективные исследования, AI-агенты должны получить опыт выполнения многошаговых целенаправленных задач.
Существующие исследовательские агенты часто обучаются только на финальных артефактах — статьях, коде, датасетах. При этом игнорируются итерационные процессы, ведущие к открытиям: отладка, неудачи экспериментов, пошаговое рассуждение. Чтобы закрыть этот пробел, мы фокусируемся на полноценных ML-исследовательских задачах от начала до конца. Мы предлагаем масштабируемый пайплайн генерации синтетических ML-задач, который даёт богатые агентные траектории с минимальными ручными усилиями. Пайплайн совместим с фреймворком SWE-agent, не привязанным к конкретному типу задач. Это позволяет моделям учиться на разнообразных ML-задачах из разных доменов.
Мы применяем наш метод к бенчмарку MLGym, включающему 13 ML-задач разной сложности. Цель агента — улучшить базовую реализацию и достичь лучшего финального скора (accuracy, loss, win rate и т.д.). Агент работает в окружении на основе SWE-agent. Ему даётся 50 раундов. В каждом он выдаёт «рассуждение» и «действие»: просмотр файлов, редактирование кода, выполнение команд, отправку финального решения. Допускается несколько попыток отправки, что отражает итеративный процесс оптимизации.
Наш пайплайн генерирует около 500 задач, что даёт датасет из ~30k агентных траекторий. Обучение Qwen3-4B и Qwen3-8B на этих траекториях даёт прирост: улучшение на большинстве задач бенчмарка и рост AUP на 9% и 12% соответственно.
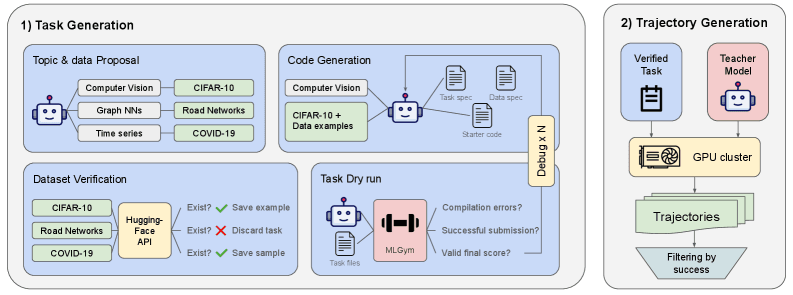
Рисунок 1. Иллюстрация пайплайна генерации задач и траекторий. Процесс генерации задач не требует человеческого контроля: он автоматически семплирует ML-темы и предлагает датасеты. Для разрешения ошибок компиляции используется debug-цикл вместо отбрасывания задачи.
2. Методология
Чтобы продвинуть границу возможностей ML-агентов, мы масштабируем автоматическую генерацию агентных задач. Поскольку цель — развитие ML-навыков, мы синтезируем множество задач по машинному обучению. Затем teacher-модель генерирует траектории по этим задачам, которые становятся обучающими данными для итоговых моделей.
2.1 Фаза 1: Синтез окружения
Основной драйвер метода — синтетическая генерация окружений ML-задач. Мы используем многостадийный пайплайн с фокусом на разнообразие и валидность задач.
1. Семплирование тем
Семплируем n различных ML-тем из модели.
2. Предложение задачи и датасета
Для каждой темы teacher-модель генерирует описание задачи и предлагает датасет на HuggingFace. Через HuggingFace Search API ищем ближайшее совпадение с предложением модели. Допускаются задачи без датасета (например, теоретико-игровые). При совпадении обогащаем описание датасета примерами строк, полученных из HuggingFace. При отсутствии совпадения задача отбрасывается.
3. Генерация конфигов и стартового кода
Из описаний задачи и датасета генерируем конфиг-файлы, совместимые со средой выполнения MLGym. Также генерируем весь стартовый код и вспомогательные утилиты. На выходе — базовая реализация и файл оценки.
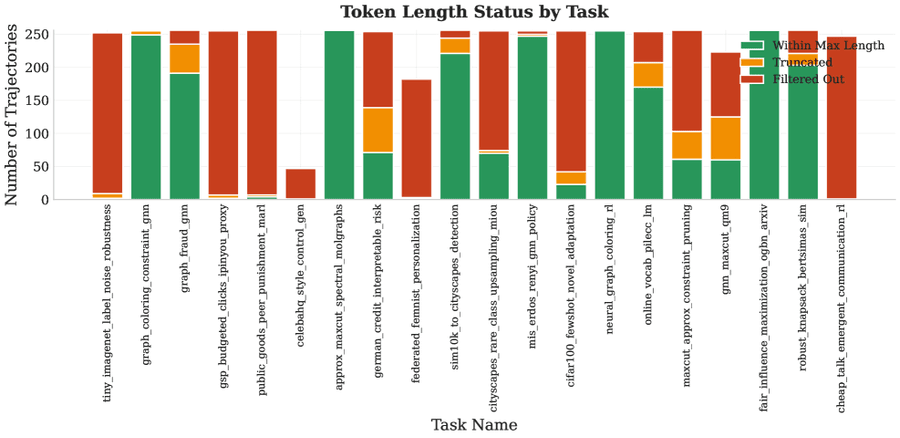
Рисунок 2. Количество сгенерированных траекторий по задачам. Показаны 20 задач и число успешных траекторий для каждой. Из-за ненадзорной природы пайплайна не все задачи успешно генерируют все 256 траекторий.
2.2 Фаза 2: Верификация окружения
Поскольку каждый шаг пайплайна подвержен ошибкам, необходимо верифицировать задачи. Для этого подключаем новую задачу к MLGym и запускаем её агентом на GPT-5. Так получаем базовую производительность и хотя бы одну агентную траекторию. При ошибке выполнения собираем ошибки и отправляем их обратно в модель на этапе 3 (генерация стартового кода) с вероятностью p_debug. Либо перезапускаем с этапа 3 с вероятностью 1 − p_debug. Итеративный debug может продолжаться максимум k раз. Если задача всё ещё падает — отбрасываем.
Пайплайн синтеза окружений не требует человеческого участия и масштабируется через параллельные вычисления.
2.3 Фаза 3: Генерация и фильтрация траекторий
Масштабный семплинг
Для сбора большого количества траекторий запускаем синтетические задачи параллельно на вычислительном кластере (HPC — High-Performance Computing). Каждая задача занимает один GPU, цель — 256 траекторий на задачу. Несмотря на валидацию, задачи могут падать по разным причинам. Кластерное окружение также влияет на генерацию через нестабильность файловой системы и контейнеризации. Рисунок 2 качественно показывает разнообразие сгенерированных задач.
Фильтрация траекторий
Собранные траектории фильтруются по результативности агента. Сейчас мы просто берём траектории, где агент совершил хотя бы одну успешную отправку. Это отсекает патологические случаи, когда агент застревает в циклах отладки. Также фильтруем по длине, отбрасывая траектории длиннее 48K токенов. При обучении траектории дополнительно обрезаются до 32K токенов.
3. Эксперименты
Бенчмарк MLGym
Мы работаем с бенчмарком MLGym, состоящим из 13 ML-задач разной сложности и тематики. Среди них: простые игровые агенты, компьютерное зрение, языковое моделирование, reinforcement learning (обучение с подкреплением). Каждая задача включает описание, описание датасета (если используется) и стартовый код. Агент работает в стандартном окружении SWE-agent с инструментами для чтения и модификации кода и выполнения bash-команд. Задача агента — улучшить текущее решение из стартового кода.
Синтез окружений и генерация траекторий
На протяжении пайплайна генерации данных используется GPT-5. Из 1000 ML-тем сгенерировано и валидировано 500 задач. Для каждой задачи целевой объём — 256 траекторий. После агрегации и фильтрации получено ~34 000 траекторий, формирующих обучающий набор для SFT (supervised fine-tuning — дообучение с учителем). Рисунок 2 показывает выборку сгенерированных задач и количество валидных траекторий. Рисунок 3 — сводная статистика финального обучающего датасета.
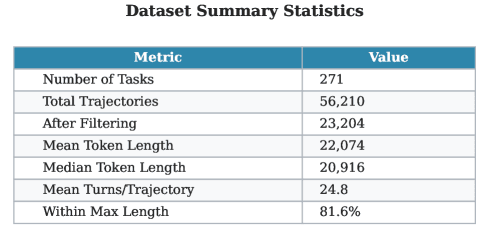
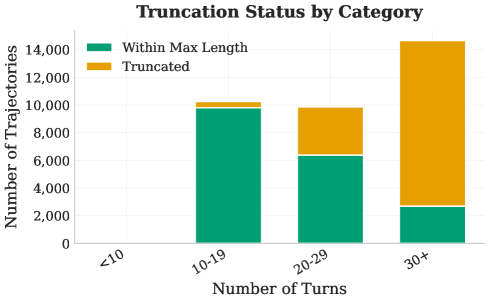
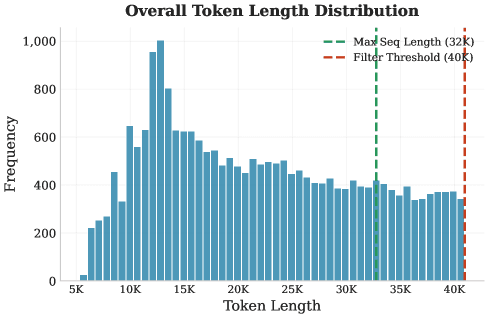
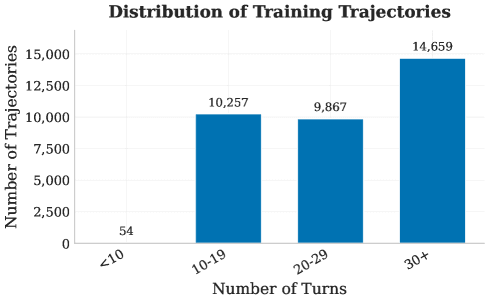
Рисунок 3. Верхний левый: сводная статистика финальных траекторий. Верхний правый: статистика обрезанных траекторий. Нижний левый: распределение задач по длине в токенах. Нижний правый: распределение по числу ходов в траектории.
Обучение моделей
Мы обучаем Qwen3-4B и Qwen3-8B через SFT на отфильтрованных траекториях. Детальные гиперпараметры — в приложении.
Производительность оценена на MLGym и сравнена с GPT-4o, GPT-5, Qwen3-4B и Qwen3-8B в базовых версиях. Результаты по отдельным задачам и агрегированные — на рисунках 4 и 5.
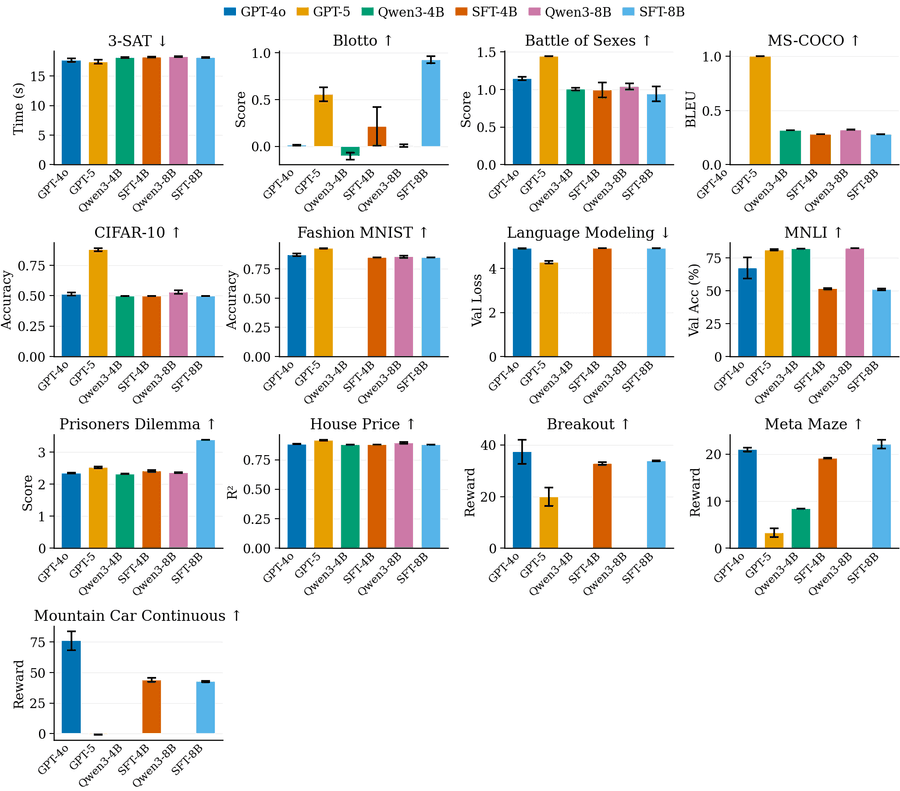
Рисунок 4. Сравнение производительности: базовые модели (GPT-4o, GPT-5, Qwen3-4B, Qwen3-8B) и обученные модели (SFT-Qwen3-4B, SFT-Qwen3-8B). Результаты агрегированы по 64 запускам, отображены как violin plots для каждой подзадачи MLGym. Пустой столбец означает, что все запуски завершились неудачей. В 9 из 13 задач обученные модели превосходят базовый Qwen3-4B.
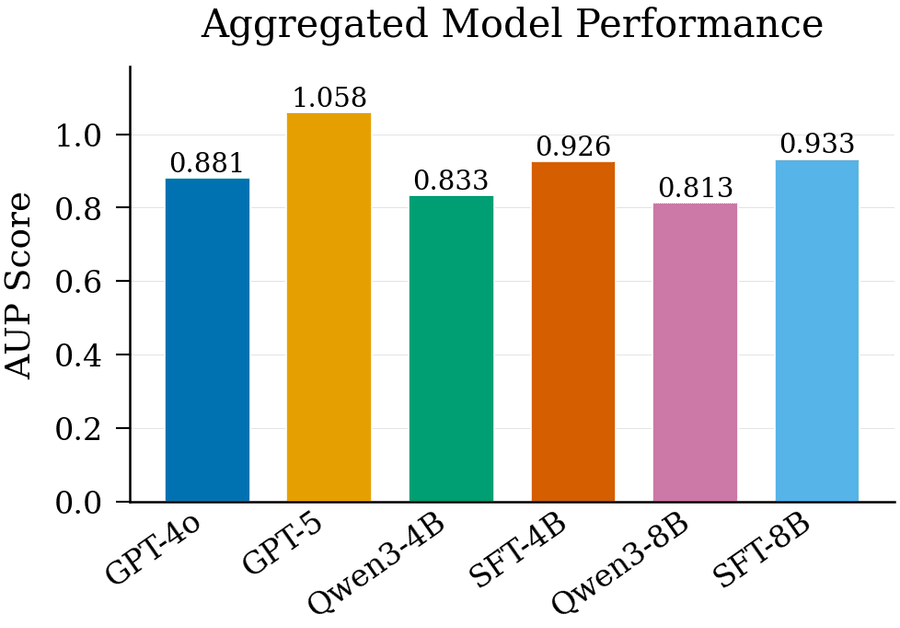
Рисунок 5. Агрегированная производительность на MLGym. Поскольку подзадачи имеют разные шкалы скора и направления сравнения, используется метрика AUP (Area Under the Performance curve).
4. Обсуждение
Режимы отказов
Текущий пайплайн покрывает большинство, но не все задачи MLGym. Например, для задачи MS-COCO прироста нет. Вероятно, пайплайн плохо покрывает распределение более сложных стартовых файлов. Направление улучшения — обусловить синтез задач на существующих качественных кодовых базах (например, NanoGPT), чтобы генерировать более сложные задачи.
Расширение на другие бенчмарки
Пайплайн полностью универсален и легко расширяется на другие агентные задачи по коду. Хороший кандидат — MLE-Bench, использующий задачи Kaggle. Поскольку модели обучены на широком спектре ML-задач, ожидается прирост без дополнительной настройки (zero-shot) на MLE-Bench.
Оптимизация на открытие новых идей
Пайплайн — первый шаг к обучению LLM-агентов для ML-задач. Но можно явно поощрять агентов формировать новые идеи при сборе траекторий, включив поиск по литературе.
Reinforcement learning
Вся текущая тренировка — SFT. Но синтетические задачи можно использовать и для RL, где reward-сигнал — финальный скор задачи. Применение RL к ML-задачам сложно. Каждый проход агента по задаче может включать длинные GPU-тренировки, а финальный reward имеет сильно различающиеся шкалы. Решение этих проблем — перспективное направление.
Формат бенчмарка vs общие способности
Естественное беспокойство: не отражает ли прирост на MLGym лучшую адаптацию к формату бенчмарка (SWE-agent/MLGym), а не реальное улучшение ML-исследовательских способностей? Наши синтетические задачи генерируются из 1000 независимо семплированных ML-тем и основаны на разнообразных датасетах HuggingFace. Поэтому содержание задач существенно шире 13 задач MLGym. Однако структурный каркас (формат взаимодействия SWE-agent, циклы рассуждение-действие) общий по дизайну. Мы не можем полностью разделить знакомство с форматом и реальное улучшение навыков. Расширение оценки на бенчмарки с другими тестовыми оболочками (MLE-Bench, MLRC-Bench, NanoGPT Speedrunning) — важное направление.
Ограничения
Во-первых, оценка ограничена одним бенчмарком (MLGym), что ограничивает доказательства генерализации. Во-вторых, нет абляции (поэлементной проверки вклада) отдельных компонентов пайплайна. Верификация через HuggingFace, self-debug-цикл, фильтрация по успешности, обрезка траекторий, качество teacher-модели — каждый мог самостоятельно внести вклад. В-третьих, пайплайн наследует биасы и слабости teacher-модели (GPT-5). Задачи и траектории, которые teacher не может решить, отсутствуют в обучении. Наконец, SFT не оптимизирует exploration или novelty. Внедрение RL с соответствующим формированием награды (reward shaping) могло бы дать дальнейший прирост.
5. Родственные работы
Недавние работы исследуют использование LLM-агентов для поддержки научных исследований на этапах идеации, исполнения и оценки. Для идеации мультиагентные системы вроде AI Co-Scientist генерируют и итеративно уточняют гипотезы. Контролируемые сравнения показывают, что LLM могут производить идеи, оцениваемые как более новаторские, чем предложения экспертов. Но часто эти идеи имеют меньшую осуществимость. Последующие исследования выявляют выраженный разрыв между идеацией и исполнением при попытке реализовать LLM-сгенерированные идеи.
Для оценки исполнительских способностей несколько бенчмарков проверяют, могут ли агенты воспроизвести реальные ML-инженерные и исследовательские workflow. MLE-Bench семплирует задачи в стиле Kaggle. PaperBench измеряет воспроизведение современных ICML-статей через множество подзадач с оцениванием по заданным критериям. Родственные бенчмарки тестируют целевые навыки: reimplement и улучшение training-скриптов в NanoGPT «speedruns». Для software engineering SWE-Smith масштабирует генерацию задач через синтез тестовых случаев, нарушающих работу кода, и улучшает производительность на SWE-bench Verified.
Работы по автоматическому рецензированию и end-to-end пайплайнам подчёркивают как перспективы, так и ограничения. DeepReview обучает рецензентские модели со структурированным поиском и аргументацией. Но более широкие оценки показывают, что LLM-рецензенты всё ещё несовершенны. The AI Scientist-v2 демонстрирует циклы от гипотезы до статьи с автоматизированными экспериментами и написанием. Бенчмарки MLAgentBench, MLGym/MLGym-Bench и MLRC-Bench изучают многошаговое исследовательское поведение. Обычно они находят, что агенты могут тюнить и исполнять устоявшиеся пайплайны, но всё ещё испытывают трудности с устойчивым планированием и поиском по-настоящему новых методов.
6. Заключение
Мы представили масштабируемый пайплайн обучения ML-исследовательских агентов через синтетическое масштабирование задач. Наш подход автоматически генерирует разнообразные ML-задачи, совместимые с SWE-agent. Он семплирует темы, предлагает и верифицирует реальные датасеты HuggingFace, синтезирует полнофункциональные исполняемые окружения с конфигами, стартовым кодом и скриптами оценки. Для обеспечения валидности на масштабе мы ввели автоматическую верификацию и self-debugging-цикл. Это позволяет отсеивать сломанные окружения без участия человека.
С помощью пайплайна сгенерировано ~500 синтетических ML-задач и собрано ~30k–34k teacher-траекторий от GPT-5. Fine-tuning Qwen3-4B и Qwen3-8B на этих траекториях даёт стабильный прирост на MLGym. AUP вырастает на 9% и 12% соответственно, с улучшением на большинстве отдельных задач. Результаты показывают, что синтетические окружения могут предоставлять эффективный обучающий сигнал для многошагового агентного поведения: итеративной отладки, экспериментирования, улучшения реализации.
В более широком смысле наша работа поддерживает практическое направление создания AI-учёных. Вместо опоры исключительно на статические корпуса статей и кода, можно обучать агентов через масштабный опыт в исполняемых исследовательских окружениях. Это открывает путь к будущим работам по RL поверх ML-задач, более богатым распределениям задач на реальных кодовых базах и агентам, которые выходят за рамки оптимизации к подлинным открытиям.