
Исследователи из Peking University и Meituan предлагают GIFT. Это метод инициализации для пост-тренинга Large Reasoning Models (LRM — больших моделей для логических рассуждений). Метод устраняет разрыв между Supervised Fine-Tuning (SFT — обучением с учителем на размеченных данных) и Reinforcement Learning (RL — обучением с подкреплением). Код доступен на GitHub.
Введение
Пайплайн обучения LRM устоялся в две стадии. Сначала SFT закладывает базовые навыки рассуждения на экспертных примерах. Затем RL заставляет модель искать собственные пути решения, выходя за рамки статического датасета. Именно так работают современные state-of-the-art системы.
Но между этапами есть теоретический разрыв. SFT минимизирует cross-entropy loss (потерю перекрёстной энтропии), имитируя токены эксперта. RL же максимизирует ожидаемую награду через поиск (exploration). Стандартный SFT агрессивно подавляет вероятности нецелевых токенов. Распределение вероятностей модели коллапсирует на детерминированных точках данных. Это явление называют distributional collapse (коллапсом распределения). Оно разрушает структурные приоры — базовые знания о языке и логике, полученные при pre-training. Это серьёзно ограничивает пространство для поиска в последующем RL.
Предыдущие работы пытались смягчить проблему настройкой датасетов или модификацией SFT-цели. Авторы GIFT не обходят RL-этап и не полагаются на эвристики. Они строят математически оптимальную связь между двумя фазами.
Ключевая идея: SFT не должен быть изолированной задачей имитации. Это строго определённая инициализация для RL в рамках единого фреймворка глобальной оптимизации.
Связанные работы
Пост-тренинг для рассуждений: парадигма SFT→RL
SFT выступает «холодным стартом», а RL с верифицируемыми наградами (RLVR) расширяет способности за пределы SFT-данных. Проблема перехода — во внутреннем конфликте оптимизации. SFT подгоняет модель под one-hot метки (где правильный ответ имеет вероятность 1, а остальные 0), подавляя альтернативы. RL требует высокоэнтропийного распределения для поиска. Этот mismatch (несоответствие) часто приводит к overfitting на SFT-данных и коллапсу вероятностного пространства.
Повышение обобщаемости SFT
Разные работы модифицируют обучающий loss. DFT перевзвешивает SFT-loss на основе предсказанных вероятностей. ASFT добавляет якорный термин KL-дивергенции (меру различия двух распределений). PSFT применяет PPO-клиппинг для отсечения токенов с экстремальными вероятностями. Другое направление — критический отбор токенов: CFT выделяет существенные токены рассуждения через контрфактические возмущения. Несмотря на это, повреждение распределения от SFT остаётся нерешённой проблемой.
Унифицированные парадигмы SFT и RL
Недавние работы чередуют SFT и RL или объединяют их цели. Эти подходы добавляют сложность и пока не вытеснили стандартный пайплайн SFT→RL. GIFT работает внутри этого стандарта, предлагая новый метод fine-tuning для оптимизации всего пост-тренинга.
Метод
GIFT основан на теоретическом фреймворке. Он объединяет SFT и RL в единую целевую функцию (объектив) глобальной оптимизации. Из гипотезы глобальной оптимальности выводится оптимальная инициализация — Gibbs distribution (распределение Гиббса). Это вероятностное распределение, взвешенное по награде и базовой модели.
Предварительные сведения
Supervised Fine-Tuning. Имея базовую модель $\pi_{\text{base}}$ и датасет $\mathcal{D}={(x,y^*)}$, SFT максимизирует log-likelihood целевых последовательностей:
$$\mathcal{L}{\text{SFT}}(\theta)=-\mathbb{E}{(x,y^)\sim\mathcal{D}}\log\pi_{\theta}(y^|x)=-\mathbb{E}{(x,y^*)\sim\mathcal{D}}\sum{t=1}^{|y^|}\left[\log\pi_{\theta}(y^{t}|x,y^*{<t})\right]$$
Reinforcement Learning с верифицируемыми наградами. После SFT модель $\pi_{\text{sft}}$ дообучается алгоритмами типа PPO или GRPO для максимизации:
$$J_{\text{RL}}(\theta)=\mathbb{E}{x\sim\mathcal{D},y\sim\pi{\theta}}\left[R(x,y)-\frac{1}{\eta}D_{\text{KL}}(\pi_{\theta}|\pi_{\text{sft}})\right]$$
где $\eta > 0$ — параметр обратной температуры. Он управляет силой KL-регуляризации (штрафом за отклонение от стартовой модели).
Глобальный оптимум пост-тренинга
Авторы определяют глобальный объектив как поиск политики $\pi_{\text{global}}^*$. Эта политика максимизирует ожидаемые награды и сохраняет привязку к базовой модели:
$$\pi_{\text{global}}^*(\cdot|x)=\arg\max_{\pi}\mathbb{E}{x\sim\mathcal{D},y\sim\pi(\cdot|x)}\left[R(x,y)-\frac{1}{\eta}D{\text{KL}}(\pi(\cdot|x)|\pi_{\text{base}}(\cdot|x))\right]$$
Замкнутое решение — Gibbs distribution:
$$\pi_{\text{global}}^*(y|x)=\frac{1}{Z_{\text{base}}(x)}\pi_{\text{base}}(y|x)\mathrm{e}^{\eta R(x,y)}$$
где $Z_{\text{base}}(x)=\sum_{y}\pi_{\text{base}}(y|x)\mathrm{e}^{\eta R(x,y)}$ — нормализующая константа (функция раздела). Это распределение задаёт оптимальный баланс между максимизацией награды и сохранением структурных приоров базовой модели.
Вывод оптимальной начальной политики
Чтобы двухэтапный пост-тренинг достиг глобального оптимума, RL должен сойтись к $\pi_{\text{global}}^*$. RL, инициализированный из $\pi_{\text{sft}}$, сходится к:
$$\pi_{\text{stage2}}^*(y|x)=\frac{1}{Z_{\text{sft}}(x)}\pi_{\text{sft}}(y|x)\cdot\mathrm{e}^{\lambda R(x,y)}$$
Приравнивая $\pi_{\text{stage2}}^* \equiv \pi_{\text{global}}^*$ и решая относительно $\pi_{\text{sft}}$, получаем оптимальную начальную политику:
$$\pi_{\text{sft}}^*(y|x)=\frac{1}{Z(x)}\pi_{\text{base}}(y|x)\cdot\mathrm{e}^{\beta R(x,y)}$$
где $\beta = \eta - \lambda$ — конечная обратная температура. Это даёт термодинамическую критику текущих парадигм. Стандартный SFT фактически предполагает $\beta \to \infty$ (предел нулевой температуры). Это заставляет политику коллапсировать в Dirac distribution (сосредоточиться на единственной точке). GIFT поддерживает конечное $\beta$. Он действует как масштабирование, взвешенное по награде. Это усиливает качественные последовательности и сохраняет структурные приоры.
Для авторегрессивной реализации этому объективу применяют токен-уровневую декомпозицию. Это делается при допущении разреженных наград:
$$\pi_{\text{sft}}^(y_{t}|y_{<t},x)\propto\pi_{\text{base}}(y_{t}|y_{<t},x)\cdot\mathrm{e}^{\beta\cdot\mathbb{I}(y_{t}=y^_{t})}$$
Это переводит глобальный объектив в практический механизм soft-target (мягких целей). GIFT добавляет скаляр $\beta$ к logitам правильных токенов. Модель выравнивается с экспертной траекторией без «замораживания», характерного для one-hot супервизии.
Предложенный алгоритм: GIFT
Для реализации токен-уровневой инициализации минимизируется KL-дивергенция между целевым распределением $\pi_{\text{sft}}^*$ и моделью $\pi_{\theta}$:
$$\mathcal{L}(\theta)=-\mathbb{E}{(x,y^*)\sim\mathcal{D}}\left[\sum{t=1}^{|y^|}\sum_{y_{t}\in\mathcal{V}}\pi_{\text{sft}}^(y_{t}|x,y^{t-1})\log\pi{\theta}(y_{t}|x,y^_{t-1})\right]$$
Алгоритм 1: GIFT — Gibbs Initialization with Finite Temperature
- Вход: датасет $\mathcal{D}$, инициализированная модель $\pi_{\theta}$, базовая модель $\pi_{\text{base}}$
- Гиперпараметры: обратная температура $\beta$, learning rate $\alpha$
- Инициализация: $\theta \leftarrow \theta_{\text{base}}$
- Пока не сойдётся:
- Сэмплировать батч $(x, y^*) \sim \mathcal{D}$
- Forward pass базовой модели → logits $z_{\text{base}}$ для всех шагов $t$
- Вычислить log-вероятности: $\log p_{\text{ref}}(v|x,y^*{<t}) = \text{LogSoftmax}(z{\text{base}})_v$
- Для каждого шага $t$ построить logits целевого распределения с поправкой на advantage $\hat{z}$:
- $\hat{z}{t,k} = \log p{\text{ref}}(k|x,y^_{<t}) + \beta$, если $k = y^_t$
- $\hat{z}{t,k} = \log p{\text{ref}}(k|x,y^_{<t})$, если $k \neq y^_t$
- Вычислить целевое распределение: $\pi_{\text{sft}}^(\cdot \mid x,y^_{<t}) = \text{Softmax}(\hat{z}_t)$
- Обновить $\theta \leftarrow \theta - \alpha \nabla_{\theta}\mathcal{L}(\theta)$
- Вернуть $\theta$
Эксперименты
Экспериментальная установка
Датасеты. Использован DeepMath-103k — крупномасштабный математический датасет повышенной сложности. Он прошёл очистку от данных публичных бенчмарков (деконтаминацию). Из полного корпуса случайным образом выбраны три непересекающихся подмножества: 10 000 примеров для SFT, 10 000 для RL, 1 000 для валидации.
Оценка. Пять математических бенчмарков (GSM8K, Math500, OlympiadBench, AIME24, AIME25) и четыре общих (GPQA, MMLU-Pro, MMLU-Redux, ARC-Challenge). Все оценки проводились через VeRL с бэкендом vLLM. Максимальная длина ответа — 8 192 токена, температура $T=0.6$.
Бейзлайны и реализация. Два бэкбона — Qwen2.5-7B и Llama-3.1-8B. Три группы бейзлайнов: (1) Direct SFT/RL, (2) унифицированные парадигмы (LUFFY, ReLIFT), (3) SFT→RL со стандартным SFT, SFT+Entropy, DFT, ASFT, PSFT. На RL-этапе везде применялся GRPO. Обучение на 8× NVIDIA H200, одна эпоха.
Основные результаты
Математическое рассуждение. GIFT стабильно показывает лучший результат на обоих бэкбонах. На Qwen2.5-7B средний pass@1 (доля успешных решений с одной попыткой) составил 52.43%. Это превосходит сильные SFT-варианты (PSFT — 50.76%) и унифицированные парадигмы (LUFFY — 50.15%). На сложном бенчмарке AIME прирост составил почти 10% над Standard SFT (13.33% → 23.33%). На более слабом Llama-3.1-8B GIFT также лидирует с 35.60% против 29.20% у Standard SFT. DFT и ASFT показали серьёзную деградацию. Это подтверждает, что GIFT работает как надёжный стабилизатор там, где бейзлайны дают сбой.
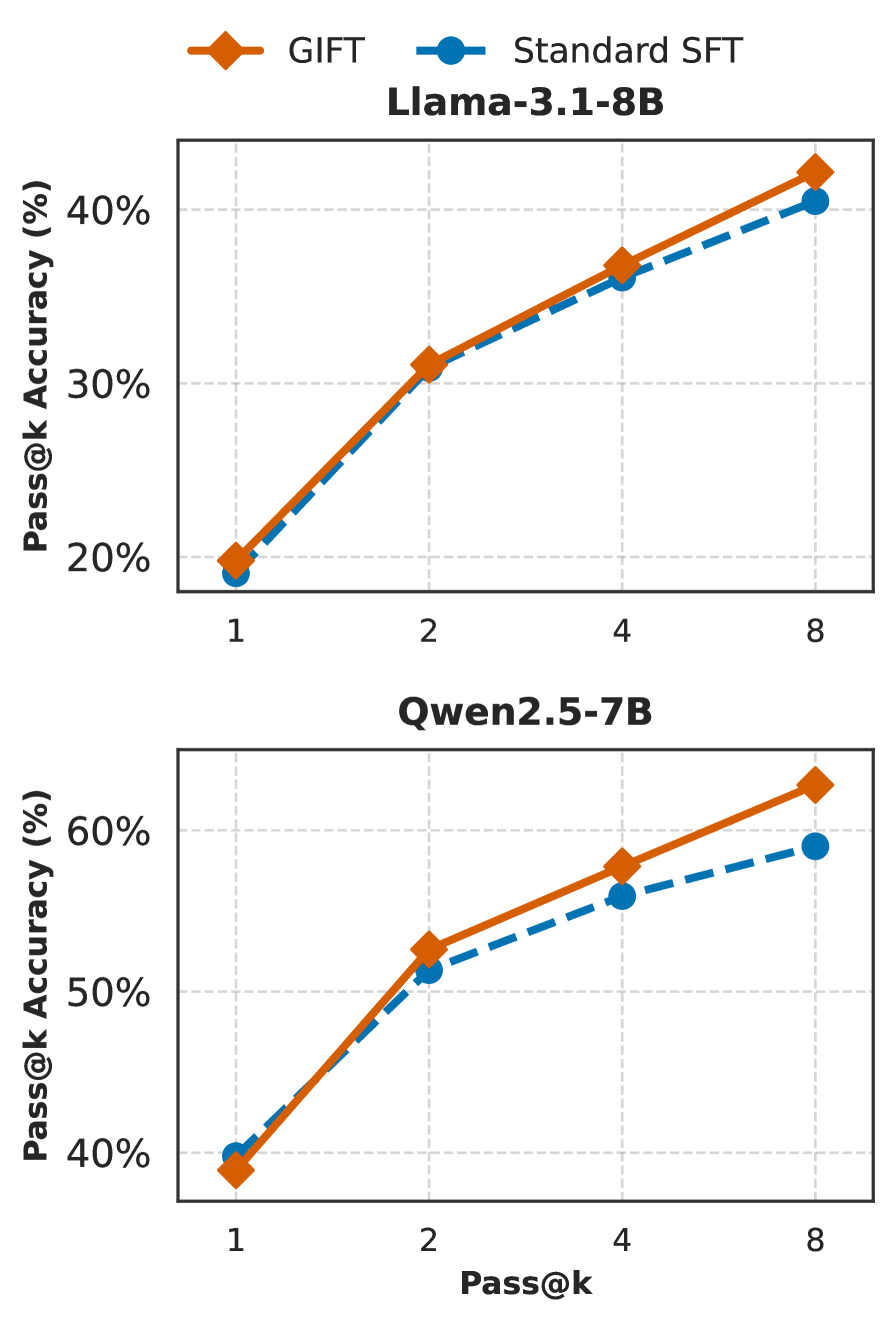 Рис. 1: Сравнение pass@k до RL-обучения. GIFT демонстрирует превосходное масштабирование с ростом числа сэмплов по сравнению со стандартным SFT.
Рис. 1: Сравнение pass@k до RL-обучения. GIFT демонстрирует превосходное масштабирование с ростом числа сэмплов по сравнению со стандартным SFT.
Обобщающая способность. На OOD-бенчмарках (задачах вне распределения обучающих данных) GIFT достигает 64.10% на Qwen2.5-7B (Standard SFT — 59.78%) и 55.24% на Llama-3.1-8B, превосходя все бейзлайны. Конечная температура позволяет сохранить структурные приоры для широкого обобщения. Zero-temperature SFT склонен к overfitting.
Потенциал exploration. Анализ pass@k (k ∈ {1,2,4,8}) до RL показал важное свойство. Standard SFT показывает конкурентный pass@1, но его преимущества исчезают при росте k. Это признак mode collapse (схождения к одному шаблону ответа). GIFT, наоборот, расширяет отрыв. На Qwen2.5-7B при pass@8 разница составляет +3.8% (62.81% против 59.01%). Это подтверждает более разнообразное выходное распределение.
Анализ обратной температуры
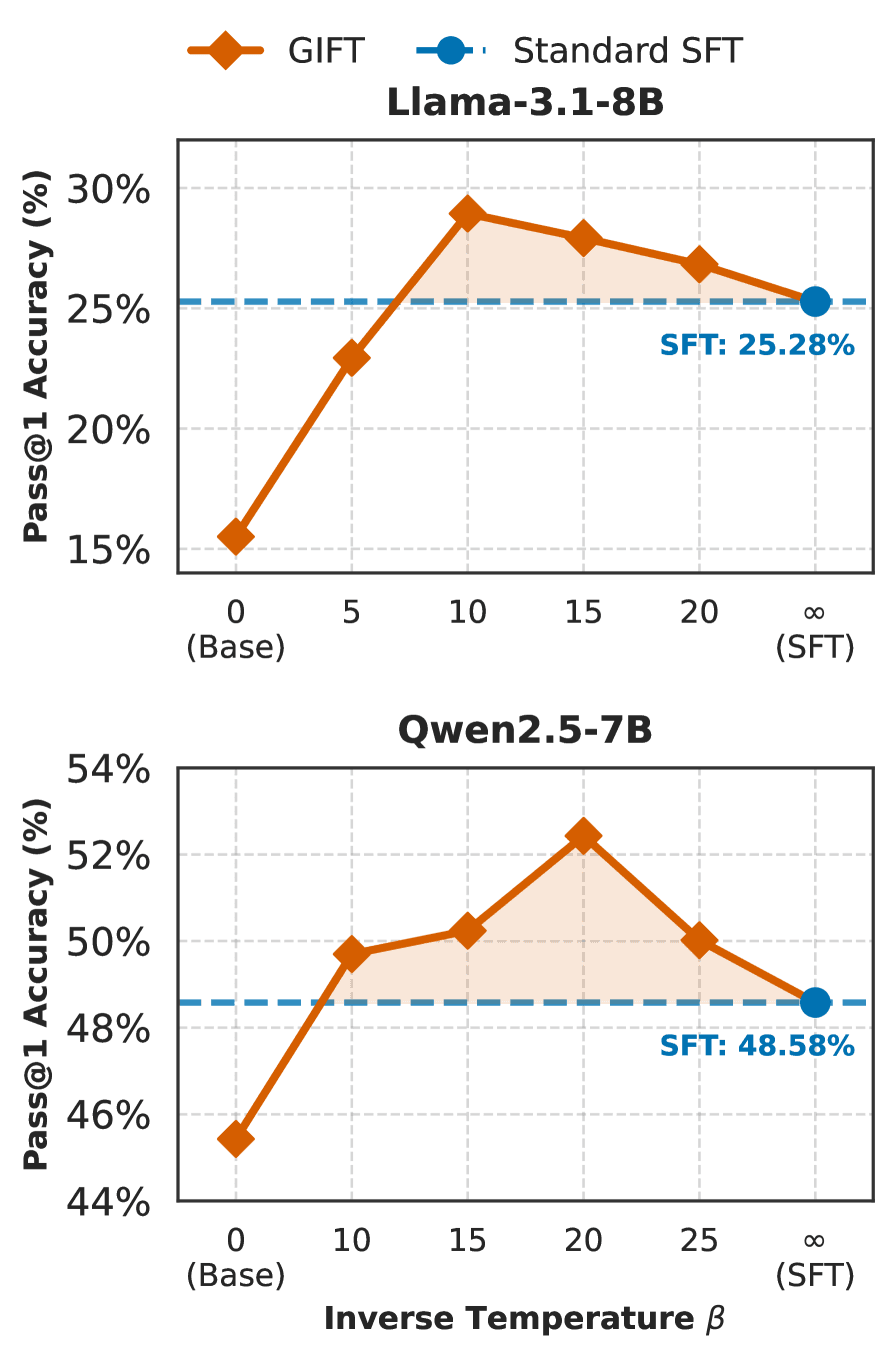 Рис. 2: Влияние обратной температуры β на RL-производительность. Средняя точность на математических бенчмарках достигает пика при конечном β, превосходя базовую линию SFT (пунктир).
Рис. 2: Влияние обратной температуры β на RL-производительность. Средняя точность на математических бенчмарках достигает пика при конечном β, превосходя базовую линию SFT (пунктир).
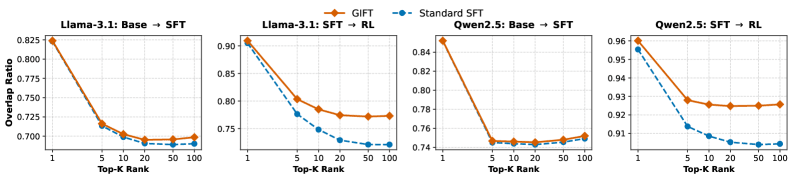 Рис. 3: Анализ top-K перекрытия токенов. GIFT показывает стабильно более высокое перекрытие, чем SFT-бейзлайн.
Рис. 3: Анализ top-K перекрытия токенов. GIFT показывает стабильно более высокое перекрытие, чем SFT-бейзлайн.
Параметр $\beta$ регулирует баланс между использованием экспертных данных и поиском на базе структурных приоров. Производительность растёт и достигает оптимального диапазона с увеличением $\beta$. Затем она деградирует к уровню Standard SFT. Ни незакреплённая базовая модель ($\beta \to 0$), ни перезакреплённый SFT-предел ($\beta \to \infty$) не оптимальны. Разные архитектуры требуют разных температур. Qwen2.5-7B даёт пик при $\beta \approx 20$, Llama-3.1-8B — при $\beta \approx 10$.
Геометрическая и распределительная согласованность
Чтобы проверить, сохраняет ли инициализация стабильную траекторию оптимизации, анализировали два типа свойств. Геометрические (косинусное сходство векторов и L2-расстояние в последнем слое трансформера). Распределительные (KL-дивергенция и top-K перекрытие токенов). Анализ проводился на двух переходах: Base → SFT и SFT → RL.
GIFT стабильно показывает более высокое косинусное сходство и меньшее L2-расстояние по сравнению со Standard SFT. Это наблюдается на обоих этапах и обеих моделях. GIFT эффективнее поглощает супервизию, оставаясь на семантическом многообразии базовой модели. KL-дивергенция на всём пайплайне в большинстве случаев ниже, а top-K перекрытие — выше. Приоры, сохранённые при SFT, эффективно используются на RL-этапе.
Заключение
Авторы построили унифицированный фреймворк глобального объектива пост-тренинга. Они выявили коллапс при нулевой температуре, который вызывает стандартный SFT. Теоретический вывод привёл к GIFT — оптимальной стратегии инициализации для RL. Эксперименты подтвердили эффективность на задачах математического рассуждения и OOD-обобщения. Анализ показал сохранённую геометрическую и распределительную согласованность на всём протяжении пост-тренинга.
Ограничения
Обратная температура $\beta$ сейчас — фиксированный гиперпараметр. Он определяется характеристиками модели и не учитывает различную сложность отдельных примеров. Также он не реагирует на меняющуюся уверенность модели. Разработка адаптивного подхода к настройке $\beta$ в процессе обучения — перспективное направление для повышения робастности (устойчивости) фреймворка.
Приложение A: Вывод замкнутого решения для глобального объектива
Задача — найти политику $\pi$, максимизирующую KL-регуляризованный наградный объектив. Раскрывая KL-дивергенцию и вводя функцию раздела $Z_{\text{base}}(x)=\sum_{y}\pi_{\text{base}}(y|x)\mathrm{e}^{\eta R(x,y)}$, объектив переписывается как:
$$J_{RL}=\frac{1}{\eta}\log Z_{\text{base}}(x)-\frac{1}{\eta}D_{\text{KL}}(\pi(y|x)|\pi^*(y|x))$$
где $\pi^(y|x)=\frac{1}{Z_{\text{base}}(x)}\pi_{\text{base}}(y|x)\mathrm{e}^{\eta R(x,y)}$. Поскольку KL-дивергенция неотрицательна и равна нулю только при совпадении распределений, максимум достигается при $\pi(y|x) = \pi^(y|x)$.
Приложение B: Вывод токен-уровневого выравнивания
B.1 Факторизация и функция advantage
Оптимальная последовательная политика факторизуется через условные вероятности. Вводя Soft Q-функцию (оценку совокупной будущей награды) $Q^*(y_{\leq t})=\log\sum_{y_{>t}}\pi_{\text{base}}(y_{>t}|y_{\leq t},x)\mathrm{e}^{\beta R(x,y)}$, получается:
$$\pi_{\text{sft}}^(y_{t}|y_{<t},x)\propto\pi_{\text{base}}(y_{t}|y_{<t},x)\cdot\mathrm{e}^{A^(y_{t},y_{<t})}$$
где $A^(y_{t},y_{<t})=Q^(y_{\leq t})-Q^*(y_{<t})$ — soft advantage function (функция преимущества выбора конкретного токена).
B.2 Аппроксимация при разреженности наград
Точное вычисление $Q^*$ требует перебора всех будущих завершений и невыполнимо. При двух допущениях — оптимальности oracle-пути и разреженном восстановлении — advantage принимает бинарную структуру:
$$A^(y_{t},y_{<t})\approx\begin{cases}\beta & \text{если } y_{t}=y^{t} \ 0 & \text{если } y{t}\neq y^*_{t}\end{cases}$$
Подстановка даёт итоговую обучающую цель:
$$\pi_{\text{sft}}^(y_{t}|y_{<t},x)\propto\pi_{\text{base}}(y_{t}|y_{<t},x)\cdot\mathrm{e}^{\beta\cdot\mathbb{I}(y_{t}=y^_{t})}$$
B.3 Согласованность последовательного и токен-уровневого объективов
Телескопическое перемножение токен-уровневых распределений восстанавливает последовательную Gibbs distribution: $\pi_{\text{sft}}^*(y|x)=\frac{1}{Z(x)}\pi_{\text{base}}(y|x)\mathrm{e}^{\beta R(x,y)}$.
Приложение C: Ablation — влияние uniform smoothing
На практике базовые модели со слабыми приорами могут столкнуться с численным underflow (исчезновением значений из-за слишком малых вероятностей при вычислениях) при $p_{\text{ref}}(y^*_t) \approx 0$. Для этого применяется optional uniform smoothing (добавление равномерного шума к вероятностям):
$$\hat{z}{t,k}=\log\left((1-\lambda)p{\text{ref}}(k)+\frac{\lambda}{|\mathcal{V}|}\right)+\beta\cdot\mathbb{I}(k=y^*_t)$$
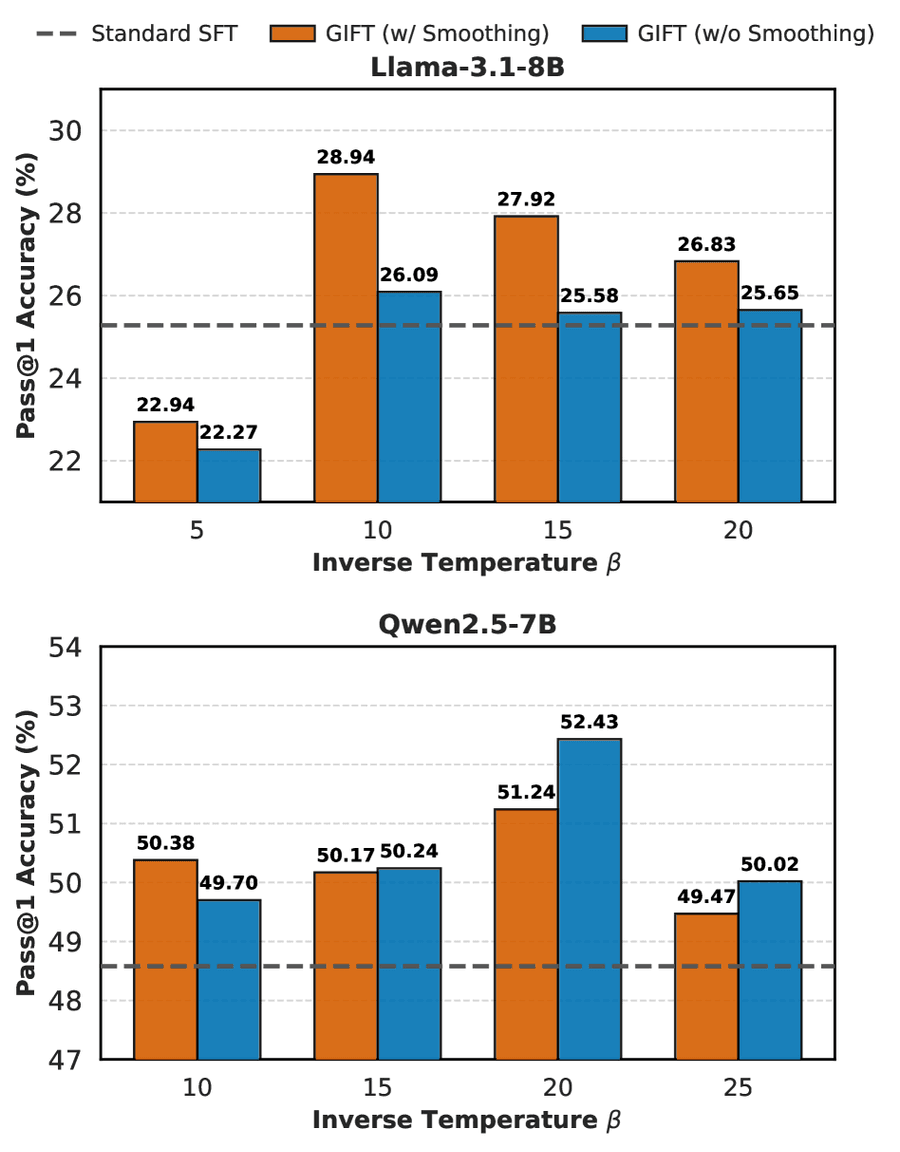 Рис. 4: Ablation uniform smoothing. Для Llama-3.1-8B со слабыми приорами smoothing предотвращает расходимость (28.94% vs 26.09% при β=10). Для Qwen2.5-7B с хорошей калибровкой smoothing избыточен и даёт небольшой проигрыш.
Рис. 4: Ablation uniform smoothing. Для Llama-3.1-8B со слабыми приорами smoothing предотвращает расходимость (28.94% vs 26.09% при β=10). Для Qwen2.5-7B с хорошей калибровкой smoothing избыточен и даёт небольшой проигрыш.
Приложение D: Динамика обучения
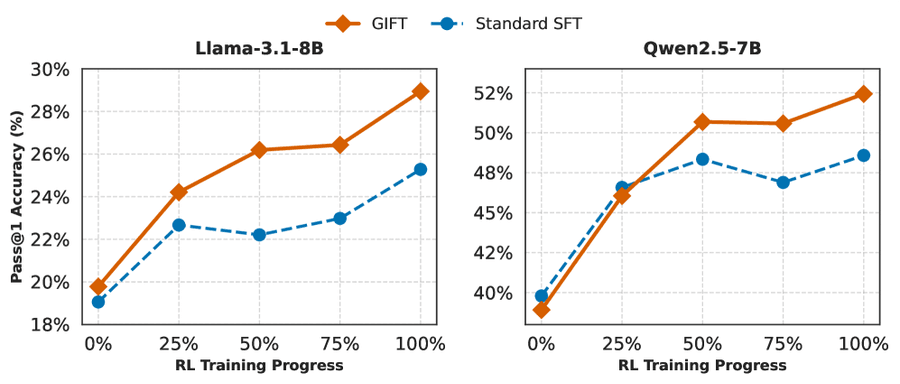 Рис. 5: Средняя pass@1 точность в процессе RL-обучения. GIFT показывает лучшую sample efficiency (эффективность обучения на выборке) и асимптотическую производительность. На Qwen2.5-7B наблюдается crossover-эффект (точка пересечения графиков): GIFT стартует чуть ниже, но обгоняет SFT-бейзлайн в первые 25% шагов.
Рис. 5: Средняя pass@1 точность в процессе RL-обучения. GIFT показывает лучшую sample efficiency (эффективность обучения на выборке) и асимптотическую производительность. На Qwen2.5-7B наблюдается crossover-эффект (точка пересечения графиков): GIFT стартует чуть ниже, но обгоняет SFT-бейзлайн в первые 25% шагов.
На Llama-3.1-8B GIFT сохраняет преимущество на всём процессе оптимизации. На Qwen2.5-7B GIFT жертвует пренебрежимым начальным поиском в обмен на существенно больший потенциал exploration и лучший долгосрочный результат.
Приложение E: Детали реализации
E.1 Supervised Fine-Tuning
Оптимизатор AdamW ($\beta_1=0.9$, $\beta_2=0.95$, weight decay 0.01), глобальный batch size 128, постоянный learning rate $1\times 10^{-5}$ без warmup (без плавного увеличения шага в начале), максимальная длина последовательности 8 192 токена. Для Llama-3.1-8B применялся uniform label smoothing.
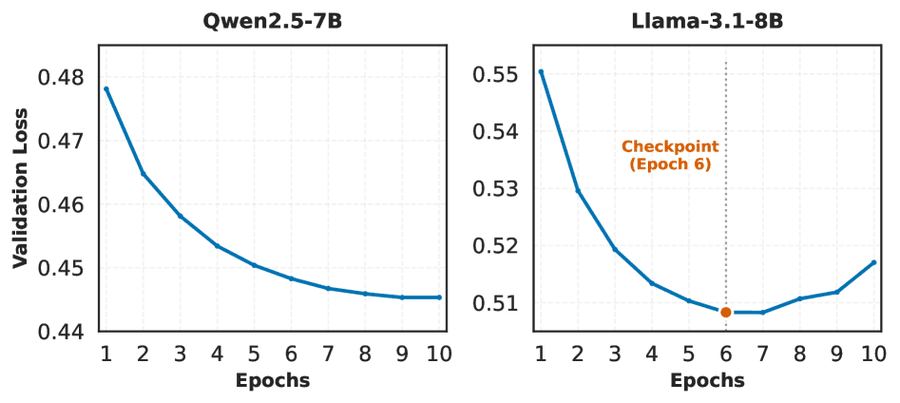 Рис. 6: Validation loss на этапе SFT. Qwen2.5-7B показывает непрерывное улучшение, Llama-3.1-8B начинает overfitting после 6-й эпохи.
Рис. 6: Validation loss на этапе SFT. Qwen2.5-7B показывает непрерывное улучшение, Llama-3.1-8B начинает overfitting после 6-й эпохи.
Для RL-инициализации равномерно выбран чекпойнт 6-й эпохи. На Llama-3.1-8B после неё loss растёт. На Qwen2.5-7B этот чекпойнт обеспечивает баланс эффективности и производительности.
E.2 Reinforcement Learning
GRPO с $G=8$ выходами на промпт, температура сэмплирования $T=1.0$, learning rate $1\times 10^{-6}$, глобальный batch size 128 (mini-batch 64), clip ratio 0.2, advantage normalization отключён, KL coefficient 0.0. Для предотвращения reward hacking (находления моделью уязвимостей системы наград вместо решения задачи) — 1 эпоха.
E.3 Оценка и награды
Средняя pass@1 точность по четырём запускам. Для Llama-3.1-8B на AIME24/25 использовался pass@32 из-за ограниченных возможностей модели. Инференс через vLLM при $T=0.6$, максимальная длина 8 192 токена. Каскадная бинарная функция награды с правилами извлечения OpenMathInstruct и парсером MathVerify. Таймаут — 10 секунд, награда 1.0 при валидации любым методом.