

Через несколько минут после публикации этой статьи NVIDIA представит то, что ещё недавно считалось бы первым в отрасли: disaggregated-решение (архитектура с физически разделёнными компонентами для разных задач) для ИИ. Но Amazon оказалась быстрее — анонсировав свой вариант нового форм-фактора за несколько дней до Дженсена Хуанга. Форм-фактора, который меняет парадигму ИИ-оборудования.
Навстречу ИИ, ориентированному на память
Amazon объявила о партнёрстве с Cerebras: технология Cerebras будет использоваться для фазы декодирования при инференсе (генерации ответа), а собственные чипы Trainium — для prefill (предзаполнения, обработки входящего запроса). Это первая в истории разделённая специализация оборудования для инференса. Она уже сейчас выглядит как новый стандарт.
Дальше объясним эти процессы подробнее.
Больше мозгов, больше времени на раздумья
В мире ИИ любят говорить о важности вычислений. Не модель даёт преимущество — модели у всех практически одинаковые. Преимущество даёт объём вычислительных ресурсов. Как продвигаться вперёд? Один из двух путей (или их комбинация):
- Больше бюджетов на обучение. Больше данных, модель крупнее — но суть в объёме вычислений.
- Больше бюджетов на инференс. Позволить модели «думать дольше над каждой задачей».
Первое — как иметь мозг побольше и больший жизненный опыт. Второе — как иметь больше времени на раздумья. Оба пути транслируются в острую потребность в вычислительных мощностях. Но при фокусе именно на инференсе расклад смещается в сторону другого компонента: памяти.
Узкое место в памяти и главная метрика ИИ-железа
Для авторегрессионных LLM (моделей, генерирующих текст по одному токену за раз — фактически всех передовых моделей сегодня) главный фактор производительности не в мощности вычислительных чипов. Он в том, насколько быстро чипы перемещают данные из памяти и обратно.
Данные хранятся не в самом процессоре, а в отдельных чипах памяти. Чтобы процессоры их обработали, память должна их «подать». Это не мгновенный процесс, измеряемый байтами в секунду.
Во время инференса — который уже составляет основную долю всех ИИ-вычислений — ускорители работают с существенной «скидкой». Они слишком мощные для того объёма данных, который могут перемещать.
Это измеряется метрикой арифметическая интенсивность (arithmetic intensity, AR) — количеством операций с плавающей запятой (FLOP) на каждый перемещённый байт данных. Для NVIDIA B300: 9 петафлопс FP8 (8-битный формат данных) при пропускной способности HBM (High Bandwidth Memory — памяти с высокой пропускной способностью) 8 ТБ/с. Делим: 9 × 10¹⁵ / 8 × 10¹² ≈ 1 125 операций на байт.
Аналогия: вы курьер FedEx, вам нужно доставить 10 посылок, грузовик вмещает все 10. Но каждый раз на складе выдают только одну. Грузовик мог бы забрать всё разом, но неэффективность склада заставляет ездить туда-сюда. Именно это происходит с GPU: вычислительные чипы настолько мощнее чипов памяти, что работают с огромным недогрузом. При этом электричество потребляется в полном объёме. Доход на ватт гораздо ниже возможного.
Две фазы инференса
Все привыкли: инференс = упирается в память. Но это зависит от фазы.
Prefill (предзаполнение). Время от нажатия «Отправить» до первого слова ответа. Модель обрабатывает весь запрос целиком, «строит контекст».
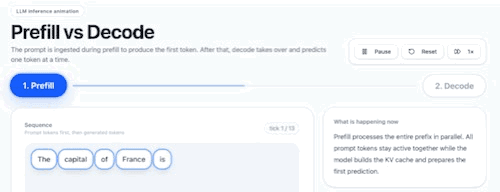
Decode (декодирование). Токены генерируются один за другим. Длится значительно дольше и заканчивается с завершением ответа.
Тезис про «упирается в память» касается в основном декодирования. Prefill в память практически не упирается: модель обрабатывает большой объём слов одновременно, вычислительная нагрузка на байт высокая.
К концу prefill происходят две вещи. Во-первых, модель построила KV-кэш (хранилище ключей и значений, содержащее контекст уже обработанного текста) для последовательности. Контекст создан, заново строить не нужно. Во-вторых, с этого момента единственный «новый контекст» — ровно один токен, который модель только что предсказала.
Каждое следующее слово требует меньше вычислений, но модель всё равно задействуется целиком. Весь вес модели прогоняется через память каждый раз. Реальной работы на каждый перемещённый байт — всё меньше. AR падает: при том же знаменателе (пропускная способность) числитель (полезные вычисления) уменьшается. Плюс KV-кэш тоже нужно прогонять через память — знаменатель растёт, AR падает ещё ниже.
Возвращаясь к аналогии: грузовик на 100 посылок, а спрос упал до 20. Другого нет — едем на Ferrari 30 км/ч в пробке.
Иерархия памяти
Два типа памяти:
- SRAM — «на кристалле». Часть чипа, которую проектирует NVIDIA и производит TSMC. Наименее ёмкая, но самая быстрая. Физически ближе к вычислительным схемам, не требует обновления.
- DRAM — «вне кристалла». Часть корпуса GPU, соединённая с вычислительными кристаллами через кремниевый интерпозер (плату для связи чипов внутри корпуса). В ИИ используется HBM DRAM — она не «быстрее» обычной, но имеет значительно более широкую шину данных. Представьте шоссе: ограничение скорости как у всех, но полос — огромное количество.
Плюс два типа хранилища: флеш-память и HDD.

Ключевая идея: если рабочая нагрузка не помещается в быструю SRAM «на кристалле», в дело вступает DRAM — и пропускная способность падает. Для длинных последовательностей кэш «утекает» даже во флеш-память, создавая третье узкое место. Производительность ИИ-инференса определяется не мощностью чипов, а эффективностью перемещения данных между слоями памяти.
Выход за пределы HBM
Amazon объявила о создании гетерогенных серверов (систем, объединяющих разные типы процессоров) для инференса: Trainium3 для prefill и Wafer-Scale Engine (WSE — чип размером с целую кремниевую пластину) от Cerebras для decode.
Ключ в том, что решения вроде WSE от Cerebras или LPU (Language Processing Unit — специализированный чип для языковых моделей) от Groq (теперь принадлежащей NVIDIA) работают исключительно на SRAM. Это делает их экстремально эффективными для декодирования, где пропускная способность памяти — решающий фактор. Вся нагрузка выполняется «на кристалле». HBM нет вообще — значит, нет и узкого места.
Данные перемещаются с колоссальной скоростью. SRAM на NVIDIA B300 обеспечивает ~37 ТБ/с. HBM3e — 8 ТБ/с. Разница в разы.
Почему не использовать SRAM-чипы для всего инференса? Две причины. Во-первых, они лучше только для decode, но значительно уступают для обучения и prefill, которые вычислительно тяжелее. Во-вторых, это невероятно дорого.
Простой расчёт: для Kimi K2.5 нужно всего 4 GPU NVIDIA. Для SRAM-решений — 23 вейфера Cerebras (фактически целый кластер) или более 4 000 чипов Groq. Без учёта кэша, который может быть больше самой модели. Компромисс: жертвуете экономикой ради экстремальной производительности.
Что предложили Amazon и NVIDIA? Объединить оба мира в одной системе:
- Prefill — GPU-подобное оборудование (NVIDIA или Amazon)
- Decode — SRAM-оборудование (Cerebras, Groq)
Настоящее чудо disaggregated-инференса, которое скоро станет нормой. Конкурировать с этим буквально нечем.
Что это значит для рынка
NVIDIA сегодня объявит аналогичное решение. С приобретением Groq они представят новый ИИ-сервер: GPU NVIDIA для prefill и LPU Groq для decode. Это закроет разговоры о том, что NVIDIA рискует быть вытесненной специализированным железом. Теперь они тоже предлагают специализированные решения.
Производители DRAM — SK Hynix, Samsung, Micron — могут ощутить давление. Если значительная часть инференса перейдёт на оборудование без HBM, акции могут просесть. На практике DRAM по-прежнему критически нужна для GPU, CPU и кэша. Но не каждый инвестор будет вникать в нюансы.
Геополитический аспект. SRAM-чипы используют более старые техпроцессы (5 нм и выше), снижая нагрузку на 3-нанометровые линии. Теоретически можно уменьшить зависимость от Тайваня. Для этого используются менее продвинутые чипы, над которыми Тайвань не имеет столь жёсткого контроля.
AMD в непростом положении. Если тренд на разделённый инференс материализуется — а он материализуется, — AMD стоит задуматься о приобретении Cerebras (хотя те, похоже, готовят IPO) или хотя бы о партнёрстве. Иначе компания рискует упустить рынок инференса. Ей придётся фокусироваться на обучении и CPU, где AMD традиционно сильна.
Google полагается на масштаб и вертикальную интеграцию (полный контроль над всей цепочкой разработки и производства). TPU заточены под собственные модели, что естественно снижает давление в части разделения оборудования. К тому же разделённые серверы инференса по определению будут очень крупными — а масштаб как раз то, в чём Google преуспела.