
Agentic-бенчмарки (тесты, где модель действует как автономный агент) по написанию кода — SWE-bench и Terminal-Bench — стали стандартом для сравнения возможностей передовых моделей. Разрыв между лидерами таблиц часто составляет всего пару процентных пунктов. Эти цифры воспринимают как точные измерения, на основе которых принимают решения о деплое. Но мы выяснили, что одна лишь конфигурация инфраструктуры может дать разницу, превосходящую эти маржи. Во внутренних экспериментах разрыв между самым ресурсоёмким и самым экономным сценариями на Terminal-Bench 2.0 составил 6 процентных пунктов (p < 0.01).
Статические бенчмарки оценивают выход модели напрямую — среда выполнения на результат не влияет. Agentic-бенчмарки работают иначе: модель получает полноценную среду, где пишет программы, запускает тесты, ставит зависимости и итерирует за несколько ходов. Среда выполнения перестаёт быть пассивным контейнером и становится частью процесса решения. Два агента с разными лимитами ресурсов и времени сдают разные тесты.
Разработчики бенчмарков это понимают. Terminal-Bench 2.0, например, указывает рекомендованные CPU и RAM для каждой задачи. Но указать ресурсы — не значит обеспечить их единообразное применение. Более того, мы обнаружили, что методология принудительного применения ограничений (enforced-ограничений) меняет то, что бенчмарк в итоге измеряет.
Как мы к этому пришли
Мы запускали Terminal-Bench 2.0 на кластере Google Kubernetes Engine (GKE). При калибровке заметили, что наши оценки не совпадали с официальным лидербордом. Доля инфраструктурных ошибок была неожиданно высока: до 6% задач падали из-за ошибок подов (pod — минимальная единица развертывания в Kubernetes). При этом большинство ошибок не было связано со способностью модели решать задачи.
Разница в оценках сводилась к методологии enforced-ограничений. Наша реализация на Kubernetes трактовала спецификации ресурсов для каждой задачи (per-task) одновременно как нижнюю границу (floor) и как жёсткий верхний предел (ceiling). Контейнер гарантированно получал указанный объём, но убивался при малейшем превышении. Container runtimes (среды выполнения контейнеров) управляют ресурсами через два отдельных параметра. Первый — гарантированное выделение (ресурсы, зарезервированные заранее). Второй — жёсткий лимит, при превышении которого контейнер убивается. Когда оба значения равны, нет запаса под всплески. Мгновенная флуктуация памяти может привести к OOM-kill (принудительному завершению из-за нехватки памяти). В противном случае контейнер справился бы с задачей. Чтобы учесть это, лидерборд Terminal-Bench использует другого sandboxing-провайдера (провайдера изолированных сред) с более мягкой реализацией. Он позволяет временное превышение выделения без терминации (завершения) контейнера ради стабильности.
Это подняло более широкий вопрос: насколько конфигурация ресурсов влияет на итоговую оценку?
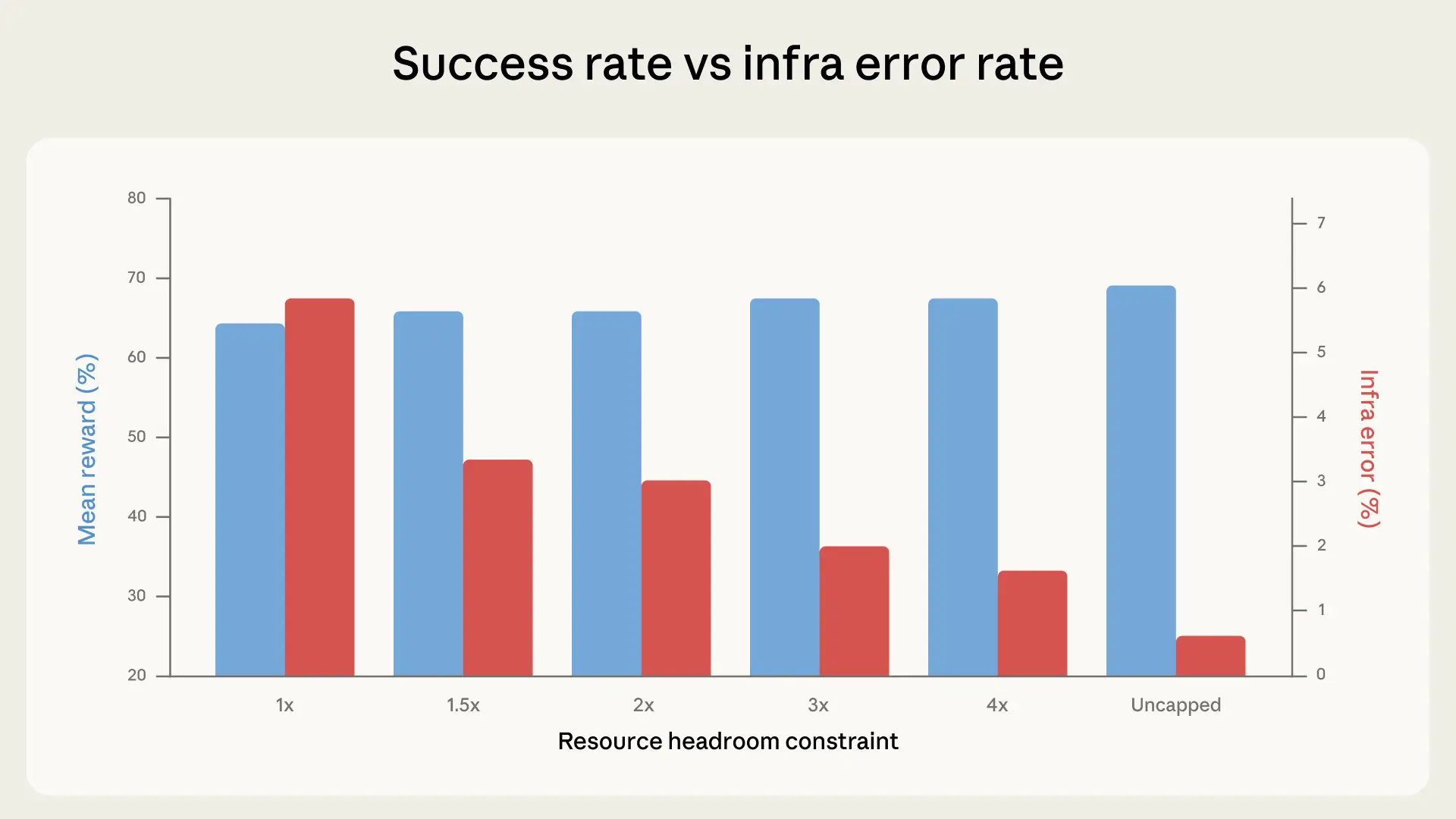
Чтобы количественно оценить влияние scaffold-а (инфраструктурного каркаса теста), мы прогнали Terminal-Bench 2.0 на шести конфигурациях ресурсов. Диапазон — от строгих enforced-ограничений per-task спецификаций (1x, где они выступают и floor, и ceiling) до полного отсутствия ограничений. Всё остальное оставалось неизменным: одна модель Claude, один harness (тестовый каркас), один набор задач.
В наших экспериментах success rate (доля успешно решённых задач) рос вместе с ресурсным запасом. Главным драйвером было монотонное падение доли инфраструктурных ошибок — с 5.8% при строгих ограничениях до 0.5% без ограничений. Падение между 1x и 3x (с 5.8% до 2.1%) статистически значимо (p < 0.001). При большем запасе меньше контейнеров убивается за превышение выделения.
От 1x до 3x оценки колеблются в пределах шума (p = 0.40). Большинство задач, падавших на 1x, всё равно бы не решились — это видно по данным. Агент исследует окружение, натыкается на ресурсный потолок и вытесняется, но он и не был на пути к правильному решению.
Начиная примерно с 3x тренд меняется: success rate растёт быстрее, чем падают инфраструктурные ошибки.
Между 3x и безлимитным режимом инфраструктурные ошибки падают ещё на 1.6 процентного пункта, а success rate вырастает почти на 4 пункта. Дополнительные ресурсы позволяют агенту пробовать подходы, работающие только при щедрых выделениях. Например, подтягивать тяжёлые зависимости, порождать дорогие subprocess-ы (дочерние процессы) и запускать потребляющие много памяти тест-сьюты (наборы тестов). При безлимитных ресурсах общий прирост над 1x составляет +6 процентных пунктов (p < 0.01). На маржинальных задачах вроде rstan-to-pystan и compile-compcert success rate значительно улучшается при наличии запаса по памяти.
Как это влияет на измерения
Вплоть до примерно 3x от спецификаций Terminal-Bench дополнительные ресурсы чинят проблемы инфраструктурной надёжности. А именно — транзиентные (кратковременные) всплески нагрузки. Sandboxing-провайдер, используемый мейнтейнерами (сопровождающими) Terminal-Bench, неявно делает это за кулисами: eval (оценка) становится стабильнее, но не проще.
А вот выше 3x дополнительные ресурсы начинают реально помогать агенту решать задачи, которые он раньше не мог. Это показывает, что лимиты меняют то, что измеряет eval. Жёсткие ограничения неосознанно вознаграждают максимально эффективные стратегии. Щедрые выделения более терпимы и вознаграждают агентов, умеющих полноценно использовать доступные ресурсы.
Агент, который пишет компактный эффективный код быстро, хорошо покажет себя при жёстких ограничениях. Агент, решающий задачи brute-force-ом (методом полного перебора) с тяжёлыми инструментами, преуспеет при щедрых. Оба сценария легитимны для тестирования. Но сворачивать их в одну оценку без указания ресурсной конфигурации — значит делать различия и реальную обобщаемость неинтерпретируемыми.
На задаче bn-fit-modify из Terminal-Bench, где требуется fitting (обучение) байесовской сети, первый ход некоторых моделей — установить стандартный Python data science stack. Это pandas, networkx, scikit-learn и весь их toolchain (набор инструментов). При щедрых лимитах это работает. При жёстких — поду не хватает памяти ещё на этапе установки, до того как агент напишет хотя бы одну строку решения. Существует и более лёгкая стратегия: реализовать математику с нуля на стандартной библиотеке. Некоторые модели по умолчанию выбирают её, другие — нет. У разных моделей разные подходы по умолчанию, и ресурсная конфигурация определяет, какие из них увенчаются успехом.
Мы воспроизвели основной вывод на разных моделях Anthropic. Направление эффекта было стабильным, хотя величина варьировалась. Похоже, те же тренды справедливы и для моделей вне Claude, но мы не проверяли это строго.
Мы также проверили, удерживается ли паттерн за пределами Terminal-Bench, проведя кроссоверный эксперимент на SWE-bench. Мы варьировали общий доступный RAM до 5x от baseline (базового значения) на 227 задачах по 10 сэмплов (запусков) каждая. Эффект сохранился, хотя величина оказалась меньше. Оценки снова монотонно росли с увеличением RAM, но при 5x были всего на 1.54 процентного пункта выше, чем при 1x. Задачи SWE-bench менее ресурсоёмки, так что меньший эффект ожидаем. Но это показывает, что выделение ресурсов не нейтрально и там.
Другие источники дисперсии
Выделение ресурсов — не единственная скрытая переменная. В определённых конфигурациях временны́е лимиты тоже начинают играть роль.
Каждый элемент setup-а (настройки окружения) eval-а может повлиять на итоговую оценку. Это включает состояние кластера, спецификации железа, уровень concurrency (параллельности) и исходящую пропускную способность. Agentic eval-ы по своей конструкции — end-to-end системные тесты (проверки от начала до конца). Любой компонент системы может выступить конфаундером (скрытой переменной, искажающей результат). Мы, например, анекдотически наблюдали, что pass rate (доля пройденных тестов) колеблется в зависимости от времени суток. Вероятно, это происходит потому, что API-латентность зависит от паттернов трафика и инцидентов. Мы не формализовали этот эффект, но он иллюстрирует более широкий тезис. Граница между «способностью модели» и «поведением инфраструктуры» размыта сильнее, чем предполагает единственная цифра бенчмарка. Провайдер модели может изолировать свою eval-инфраструктуру, выделив отдельное железо. Но внешним оценщикам это не так просто.
Публичные бенчмарки обычно задумываются как измерение чистых возможностей модели. Но на практике рискуют смешать их с инфраструктурными причудами. Иногда это может быть полезно — как end-to-end тест всего стека, — но чаще нет. Для кодовых eval-ов, предназначенных для публичного обмена, запуск в разное время и в разные дни помог бы усреднить шум.
Что мы рекомендуем
Идеальный сценарий — прогонять каждый eval в абсолютно одинаковых аппаратных условиях. Это касается и scaffold-а, и inference-стека (стека вывода модели). Такой подход обеспечил бы полную воспроизводимость. Но это не всегда практично.
Учитывая, как container runtimes реально enforced-яют (принудительно применяют) ресурсы, мы рекомендуем указывать в eval-ах оба параметра для каждой задачи. Это гарантированное выделение и отдельный порог kill-а (завершения), а не одно фиксированное значение. Единственная точечная спецификация приравнивает гарантированное выделение к kill-порогу, не оставляя запаса. Транзиентные всплески памяти, которые мы задокументировали на 1x, достаточны, чтобы дестабилизировать eval. Разделение параметров позволяет дать контейнерам достаточно свободы, чтобы избежать ложных OOM-kill-ов. При этом сохраняется жёсткий потолок, предотвращающий раздувание оценок.
Полоса между ними должна быть откалибрована так, чтобы оценки на floor и ceiling укладывались в шум друг друга. Например, на Terminal-Bench 2.0 потолок 3x от per-task спецификаций снизил долю инфраструктурных ошибок примерно на две трети (с 5.8% до 2.1%, p < 0.001). При этом рост оценки остался скромным и в пределах шума (p = 0.40). Это разумный компромисс. Инфраструктурный конфаундер в основном нейтрализован без снятия содержательного ресурсного давления. Точный мультипликатор будет зависеть от бенчмарка и распределения задач — его следует фиксировать в отчёте. Но принцип эмпирической калибровки универсален.
Почему это важно
Эти выводы имеют практические последствия за пределами eval-инфраструктуры. Оценки бенчмарков всё активнее используют как входные данные для принятия решений. Но это возросшее внимание не всегда сопровождается соответствующей строгостью в том, как запуски проводятся и репортируются. В нынешнем положении дел отрыв в 2 пункта на лидерборде может отражать реальную разницу в возможностях. А может отражать тот факт, что один eval прогнали на более мощном железе или просто в более удачное время суток. Либо и то, и другое одновременно. Без опубликованных или стандартизированных конфигураций setup-а со стороны это не определить. Заинтересованные стороны должны пойти на лишние усилия по воспроизведению результатов в идентичных условиях.
Для лабораторий вроде Anthropic вывод в том, что ресурсную конфигурацию для agentic eval-ов следует рассматривать как first-class (первостепенную) экспериментальную переменную. Её нужно документировать и контролировать с той же строгостью, что и формат промпта или sampling temperature (параметр случайности при генерации). Для мейнтейнеров бенчмарков публикация рекомендованных спецификаций ресурсов (как это делает Terminal-Bench 2.0) — уже большой шаг. Фиксация enforcement-методологии закрыла бы выявленный нами разрыв. А для всех, кто потребляет результаты бенчмарков, главный вывод следующий. Небольшие различия в оценках на agentic eval-ах несут больше неопределённости, чем предполагает точность заявленных цифр. Особенно поскольку часть конфаундеров просто слишком трудно проконтролировать.
Пока ресурсная методология не стандартизирована, наши данные говорят о том, что разрывам на лидербордах ниже 3 процентных пунктов стоит относиться скептически. Особенно пока конфигурация eval-а не задокументирована и не совпала. Наблюдаемый разброс в умеренном диапазоне ресурсных конфигураций на Terminal-Bench — чуть ниже 2 процентных пунктов. Стандартные биномиальные доверительные интервалы и так покрывают 1–2 пункта. Инфраструктурные конфаундеры, которые мы задокументировали, наслаиваются поверх этих интервалов, а не внутри них. На экстремумах диапазона выделений разброс достигает 6 пунктов.
Отрыв в несколько пунктов может сигнализировать о реальном разрыве в возможностях. А может быть просто более крупной VM (виртуальной машиной).