
Kaito Baba, Satoshi Kodera Department of Cardiovascular Medicine, The University of Tokyo Hospital, Tokyo, Japan
Аннотация
Мы предлагаем MARL-Rad — новый фреймворк мультимодального мультиагентного обучения с подкреплением для генерации рентгеновских отчётов. Фреймворк координирует региональных агентов и глобальный интегрирующий агент. Оптимизация идёт через клинически верифицируемые награды. Предыдущие подходы ограничивались одиночной RL-моделью или объединяли независимо обученные модели уже постфактум. Наш метод совместно обучает множество агентов и оптимизирует всю систему через reinforcement learning. Эксперименты на датасетах MIMIC-CXR и IU X-ray показывают, что MARL-Rad последовательно улучшает метрики клинической эффективности (CE) — RadGraph, CheXbert и GREEN, достигая SOTA (State-of-the-Art, лучших на данный момент) результатов по CE. Дополнительный анализ подтверждает, что MARL-Rad повышает консистентность по латеральности и генерирует более точные, детализированные отчёты.
1 Введение
Последние достижения больших языковых моделей (LLM) продемонстрировали впечатляющие возможности рассуждения и генерации в широком спектре задач. Среди них — диалоговые системы, математический вывод, синтез кода, научные открытия и медицинская диагностика [23, 88, 31, 127]. Важный фактор этих достижений — Reinforcement Learning with Verifiable Rewards (RLVR). Метод усиливает модели через обратную связь, основанную на объективно верифицируемых метриках, а не на оценках людей [96, 99, 135, 144]. Параллельно агентные системы стали перспективным подходом для применения LLM в сложных задачах. Они разбивают задачу на управляемые подзадачи и координируют множество агентов ради общей цели [123, 33, 37, 57, 142, 5, 94, 52, 44, 59].
Медицина — одна из ключевых областей применения LLM и больших визуально-языковых моделей (LVLM — моделей, работающих одновременно с изображениями и текстом). Среди медицинских модальностей рентгенограмма грудной клетки (CXR) — один из самых распространённых диагностических инструментов. Она позволяет врачам исследовать лёгкие, сердце и скелетные структуры для выявления пневмонии, пневмоторакса, плеврального выпота и кардиомегалии [82, 11, 12, 2]. Радиологи тщательно изучают CXR-изображения и вручную составляют детальные диагностические отчёты. Но этот процесс трудоёмок. Рост спроса на диагностическую визуализацию ведёт к задержкам в диагнозе и снижению качества отчётов [21, 10, 98, 26]. Чтобы снизить нагрузку, автоматическая генерация рентгеновских отчётов (RRG) с помощью LLM привлекает всё большее внимание [72, 92, 145, 126, 55, 1, 119, 24, 62, 22, 116, 106, 24, 4, 125]. Недавние работы дополнительно применяют reinforcement learning [66, 18] и проектируют агентные системы [139, 79, 28, 131, 50] для повышения клинической точности.
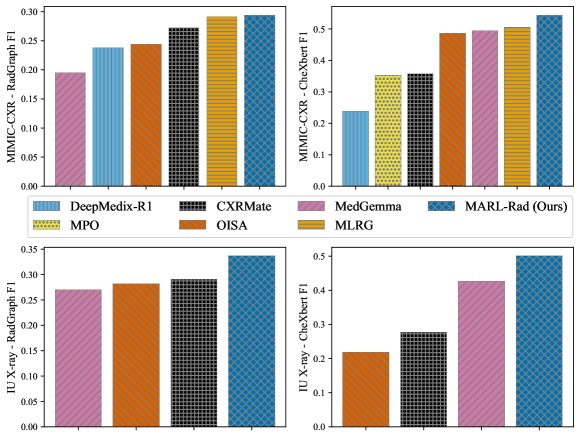
Рисунок 1: Сравнение с предыдущими SOTA-методами на датасетах MIMIC-CXR [48] и IU X-ray [25]. Наш метод достигает SOTA по метрикам клинической эффективности, показывая наивысшие баллы как по RadGraph F1, так и по CheXbert F1.
Несмотря на эти достижения, большинство RL-подходов по-прежнему ограничены оптимизацией одной модели. Это касается даже недавних работ по агентному RL с использованием инструментов или планирования [102, 81, 27, 137, 29, 95, 60, 104, 14]. Существующие агентные системы, как правило, не требуют обучения. Они комбинируют предобученные модели через промпты без end-to-end оптимизации (сквозного обучения всей системы от входа до выхода) [142, 94, 52, 44, 59]. Некоторые работы исследуют off-policy пост-обучение (обучение по ранее собранным данным, без прямого взаимодействия со средой) по траекториям агентов [83] или on-policy RL (обучение с прямым взаимодействием со средой) для одного центрального агента [63]. Но on-policy оптимизация всей агентной системы в рамках реальных рабочих процессов остаётся малоизученной. В частности, такое согласованное с рабочим процессом мультиагентное RL (MARL) почти не исследовано в мультимодальных и медицинских задачах [130, 85, 115, 61]. Без такого MARL существующие агентные системы принципиально субоптимальны. Отдельные агенты не обучены совместно сотрудничать так, как это происходит в реальных рабочих процессах.
Чтобы устранить это ограничение, мы предлагаем MARL-Rad — новый фреймворк мультимодального мультиагентного обучения с подкреплением. MARL-Rad состоит из региональных агентов, ответственных за локальные наблюдения, и глобального интегрирующего агента, который синтезирует их выходы. Фреймворк совместно обучает этих агентов в on-policy режиме на основе клинически верифицируемых наград. Вся агентная система оптимизируется в реалистичном рабочем процессе. Этот процесс зеркалит реальную практику радиологов: они тщательно исследуют каждую анатомическую область перед составлением комплексного отчёта. Эксперименты на MIMIC-CXR и IU X-ray показывают, что MARL-Rad последовательно улучшает метрики клинической эффективности — RadGraph F1 [43], CheXbert F1 [103] и GREEN [89], достигая SOTA. Кроме того, анализ показывает, что MARL-Rad улучшает консистентность по латеральности и генерирует более детализированные, клинически точные описания.
Наши ключевые вклады:
- End-to-end оптимизация кооперативных агентов. В отличие от подходов без обучения или методов одиночного RL, MARL-Rad выполняет on-policy оптимизацию всей агентной системы в рабочем процессе, зеркалящем реальную практику радиологов.
- SOTA по метрикам клинической эффективности. Эксперименты на MIMIC-CXR и IU X-ray демонстрируют лучшую производительность по RadGraph F1, CheXbert F1 и GREEN.
- Улучшенная консистентность по латеральности и более точные отчёты. MARL-Rad повышает согласованность лево-правой сторон и генерирует более детализированные клинически точные отчёты по сравнению с single-agent RL-базлайнами.
2 Связанные работы
2.1 Reinforcement learning для LLM
Reinforcement Learning with Verifiable Rewards (RLVR) недавно возник как альтернатива традиционному Reinforcement Learning from Human Feedback (RLHF). RLHF опирается на модели человеческих предпочтений, а RLVR обеспечивает объективную обратную связь через детерминистические функции верификации. Награждая корректность или соответствие правилам, RLVR улучшил рассуждения в структурированных областях — математике и генерации кода [122, 105, 99, 135, 144, 77, 78]. Появилось агентное RL, где модели взаимодействуют с внешними инструментами — Python-интерпретаторами или поисковыми движками — для повышения фактической точности [102, 81, 27, 137, 29, 95, 60, 104, 14]. Но большинство этих методов фокусируется на обучении одной модели, а не на совместной оптимизации нескольких агентов.
2.2 Агентные системы с LLM
Агентные системы используют LLM для целенаправленного рассуждения, планирования и сотрудничества через структурированные взаимодействия между агентами. Фреймворки вроде AutoGen [123], MetaGPT [33], CAMEL [57] показали, что предобученные LLM могут кооперироваться через тщательно спроектированные промпты и workflows [37, 5, 142, 94, 52, 44, 59, 64]. Однако большинство таких систем не требует обучения. Они опираются на предобученные модели без end-to-end оптимизации. Это приводит к субоптимальной координации и ограниченной адаптивности в сложных реальных задачах.
Некоторые работы начали исследовать RL внутри агентных систем. MALT [83] выполняет пост-обучение по траекториям агентов, но оптимизация остаётся off-policy и оторванной от реальных рабочих взаимодействий. MAPoRL [91] применяет мультиагентное RL для улучшения сотрудничества между языковыми моделями, но оптимизация реалистичных role-structured workflows (рабочих процессов с распределением ролей) в прикладных областях остаётся малоизученной. AgentFlow [63] вводит on-policy RL в реальном мультиагентном workflow, но оптимизация ограничена одним агентом-планировщиком, а не всей системой.
2.3 LLM для генерации рентгеновских отчётов (RRG)
Ранние RRG-системы в основном следовали парадигме encoder–decoder на базе Transformers. Например, R2Gen [15] установил сильные базовые результаты на MIMIC-CXR [48] и IU X-ray [25]. Более поздние LLM-ориентированные подходы выравнивают медицинский визуальный encoder с замороженным или файнтюнутым LLM для генерации более беглых, клинически обоснованных отчётов. Среди них — R2GenGPT [118], XrayGPT [110], MAIRA-1 [42], MAIRA-2 [7], CheXagent [17], а также другие подходы [75, 93, 128, 138, 133, 38, 56, 45, 20, 120, 80, 84, 136, 26, 30, 145, 126, 72, 92, 55, 1, 119, 24, 106, 32, 86, 3, 146, 49, 36, 121, 124, 74, 114, 141, 111, 39, 34, 140, 125, 51, 129, 8, 35, 46, 132, 40].
2.4 Reinforcement learning для RRG
Недавние работы интегрируют RL для повышения клинической точности в RRG. LM-RRG [145] встраивает RL клинического качества, напрямую оптимизируя RadCliQ [134] как сигнал награды. BoxMed-RL [47] связывает chain-of-thought (пошаговое рассуждение) с пространственно верифицируемым RL, привязывая текстуальные находки к bounding-box-доказательствам (прямоугольным областям на изображении). DeepMedix-R1 [66] использует трёхстадийный пайплайн: instruction fine-tuning, экспозицию синтетических reasoning-семплов и online RL. OraPO [18] предлагает oracle-educated GRPO (Group Relative Policy Optimization — вариант RL, оптимизирующий политику на основе относительных преимуществ в группе) для RRG с fact-level reward (FactScore). Med-R1 [54] применяет GRPO-based RL к медицинским VLM на восьми модальностях визуализации и пяти типах VQA-задач. Однако все эти RL-подходы фокусируются на оптимизации одной модели, а не всей мультиагентной системы.
2.5 Агентные системы для RRG
Мультиагентные фреймворки начинают появляться в RRG. Они согласуются со стадиями клинического рассуждения или комбинируют мультиагентную RAG (retrieval-augmented generation — генерацию с поиском по внешней базе знаний). RadAgents [139] предлагает подобный работе радиолога мультиагентный workflow для интерпретации CXR. CXRAgent [79] вводит director-оркестрируемый многостадийный агент для интерпретации CXR с evidence-driven валидатором. Yi et al. [131] декомпозирует отчётность по CXR на агенты извлечения, черновика, уточнения, зрения и синтеза. Elboardy et al. [28] предлагают модельно-agnostic фреймворк из десяти агентов, объединяющий генерацию и оценку отчётов. Но эти агентные RRG-системы в основном не требуют обучения. Они опираются на предобученные модели без end-to-end оптимизации всей системы.
3 Метод
3.1 Предварительные сведения
В этом разделе мы вводим необходимые обозначения и вкратце описываем Group Sequence Policy Optimization (GSPO) [144] — вариант на уровне последовательностей от GRPO, показавший улучшенную производительность.
Пусть 𝒟\mathcal{D} обозначает распределение данных над парами запрос–ответ (q,a)(q,a). Как и GRPO, GSPO для каждого запроса qq семплирует группу из GG ответов ({xi}i=1G∼πθold(⋅∣q))({x_{i}}{i=1}^{G}\sim\pi{\theta_{\text{old}}}(\cdot\mid q)), где πθold\pi_{\theta_{\text{old}}} — политика, используемая для генерации выходов до обновления. Каждый семплированный ответ xix_{i} оценивается верифицируемой наградой r(xi,a)r(x_{i},a), а групповое относительное преимущество вычисляется так:
A^i≔r(xi,a)−mean({r(xi,a)}i=1G)std({r(xi,a)}i=1G).\hat{A}{i}\coloneqq\frac{r(x{i},a)-\operatorname{mean}({r(x_{i},a)}{i=1}^{G})}{\operatorname{std}({r(x{i},a)}_{i=1}^{G})}.
(1)
Затем GSPO выполняет оптимизацию политики, максимизируя следующий объектив:
𝒥GSPO(θ)≔𝔼(q,a)∼𝒟,{xi}i=1G∼πθold(⋅∣q)[1G∑i=1G\displaystyle\mathcal{J}{\text{GSPO}}(\theta)\coloneqq\mathbb{E}{(q,a)\sim\mathcal{D},{x_{i}}{i=1}^{G}\sim\pi{\theta_{\text{old}}}(\cdot\mid q)}\Bigg[\frac{1}{G}\sum_{i=1}^{G}
min(si(θ)A^i,clip(si(θ),1−ε,1+ε)A^i)],\displaystyle\hskip 28.45274pt\min\left(s_{i}(\theta)\hat{A}{i},\operatorname{clip}(s{i}(\theta),1-\varepsilon,1+\varepsilon)\hat{A}_{i}\right)\Bigg],
(2)
где
si(θ)\displaystyle s_{i}(\theta)
≔(πθ(xi∣q)πθold(xi∣q))1/|xi|\displaystyle\coloneqq\left(\frac{\pi_{\theta}(x_{i}\mid q)}{\pi_{\theta_{\text{old}}}(x_{i}\mid q)}\right)^{!1/|x_{i}|}
=(∏t=1|xi|πθ(xi,t∣q,xi,<t)∏t=1|xi|πθold(xi,t∣q,xi,<t))1/|xi|\displaystyle=\left(\frac{\prod_{t=1}^{|x_{i}|}\pi_{\theta}(x_{i,t}\mid q,x_{i,<t})}{\prod_{t=1}^{|x_{i}|}\pi_{\theta_{\text{old}}}(x_{i,t}\mid q,x_{i,<t})}\right)^{!1/|x_{i}|}
(3)
— отношение важности на основе правдоподобия последовательностей, а |xi||x_{i}| — количество токенов ответа xix_{i}.