
Аннотация
Современные системы text-to-speech (TTS) всё активнее интегрируют невербальные вокализации (NV) — звуки вне речи, такие как смех, вздохи или междометия. Но их оценка лишена стандартизированных метрик и надёжных референсов. Чтобы закрыть этот пробел, мы предлагаем NV-Bench — первый бенчмарк, основанный на функциональной таксономии. Она рассматривает NV как коммуникативные акты, а не просто побочные акустические эффекты. NV-Bench содержит 1 651 многоязычных референса из реальных записей с парным человеческим аудио, сбалансированных по 14 категориям NV.
Мы вводим двухмерный протокол оценки:
- Instruction Alignment — с предложенной paralinguistic character error rate (PCER, коэффициент ошибок в паралингвистических символах) для оценки управляемости.
- Acoustic Fidelity — измерение распределительного разрыва с реальными записями для оценки акустического реализма.
Мы оцениваем различные TTS-модели и разрабатываем два базовых решения. Результаты показывают сильную корреляцию наших объективных метрик с человеческим восприятием. Это закрепляет за NV-Bench роль стандартизированного фреймворка оценки.
Ключевые слова: Speech benchmark, Nonverbal vocalizations, Paralinguistic-aware ASR, Controllable TTS
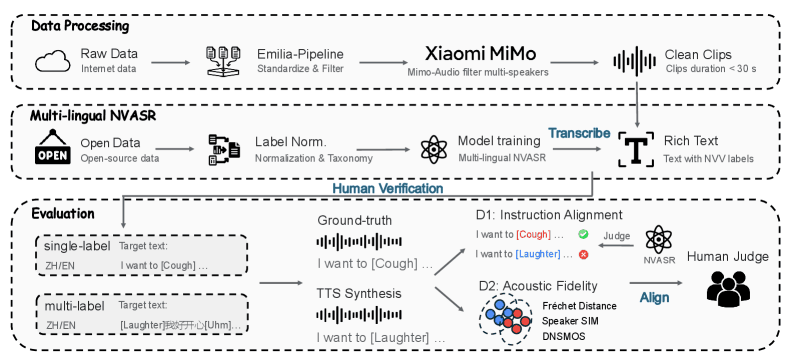
Рисунок 1: Обзор NV-Bench. (1) Обработка данных: сырой аудио фильтруется через Emilia-Pipeline и MiMo-Audio. (2) Многоязычный NVASR: мы обучаем многоязычную NVASR-модель на open-source данных с унифицированной таксономией меток. (3) Оценка: после верификации людьми бенчмарк оценивается по измерениям instruction alignment и acoustic fidelity, а также по субъективным оценкам.
1. Введение
Современные выразительные TTS-модели всё чаще интегрируют невербальные вокализации (NV) для повышения естественности коммуникации. Текущие подходы добавляют NV либо в виде дискретных токенов (например, NVTTS), либо в виде перекрывающихся слоёв (например, CapSpeech). Но большинство методов относится к NV как к универсальным «звуковым эффектам», приписанным к лингвистическому содержимому. Такой подход упускает суть: NV — это не просто акустические текстуры, а коммуникативные акты. Они передают физиологические состояния, эмоции и намерения в диалоге. Для развития области нужно перейти от проверки наличия звука к оценке его уместности в контексте.
Чтобы систематизировать эти явления, мы опираемся на функциональную таксономию Batliner et al., разделяя NV на три уровня, критичных для выразительного TTS:
- Вегетативные звуки — биологические рефлексы вроде дыхания и кашля, обеспечивающие физический реализм.
- Аффективные всплески — эмоциональные вокализации, кратко передающие состояние говорящего или мгновенную реакцию.
- Разговорные междометия — сигналы управления взаимодействием: заполнители пауз, просодические частицы, устраняющие неоднозначность (например, подтверждение или сомнение).
Эта таксономия показывает, что NV — это спектр нелексических, прагматически нагруженных вставок. Они необходимы для передачи эмоций и управления дискурсом.
Ряд крупных корпусов с NV уже появился: Emilia-NV, SMIIP-NV, NVTTS, DisfluencySpeech, NonverbalSpeech (NVS), SynParaSpeech. Но масштабирование тренировочных данных не даёт надёжного стандарта оценки. Текущие практики опираются на внутренние тестовые сеты или переписанные текстовые референсы вместо аутентичных парных записей. Без эталонных (ground-truth, GT) NV-записей оценка сводится к грубым проверкам (присутствие/отсутствие события). Это не позволяет измерить разрыв с реальным аудио. Кроме того, NV-события распределены с длинным хвостом — редкие категории встречаются намного чаще прочих. Несбалансированные тестовые сеты искажают агрегированные метрики и мешают честной диагностике.
Чтобы решить эти проблемы, мы представляем NV-Bench демо — комплексный бенчмарк для TTS с поддержкой NV. NV-Bench предоставляет публичный многоязычный тестсет из 1 651 высказывания. Они отобраны из онлайн-аудиовизуального контента 2025 года для минимизации утечки данных в тренировочные выборки. Для честного сравнения бенчмарк разбит на два подмножества: строго сбалансированное однометочное (50 примеров на категорию) и относительно сбалансированное многомечное с 14 типами NV. Все тестовые образцы содержат реальные NV с парным GT-аудио. Такая пара позволяет воспроизводимо оценивать instruction alignment через character error rate (CER) и его варианты. Acoustic fidelity оценивается через speaker similarity и fréchet distance (FD).
Основные вклады:
- NV-Bench — первый комплексный фреймворк оценки TTS с поддержкой NV, с публичным датасетом из реальных записей и парным человеческим GT-аудио.
- Стандартизированный и сбалансированный по распределению протокол оценки для честного и воспроизводимого сравнения моделей.
- Масштабное тестирование state-of-the-art (SOTA) TTS-моделей, раскрывающее их управляемость, разборчивость и акустическую точность.
Таблица 1: Сравнение датасетов невербальных вокализаций.
| Датасет | Язык | Тестсет | Баланс | Промпт |
|---|---|---|---|---|
| SynParaSpeech | zh | ✗ | – | – |
| NVS | zh/en | ✗ | – | – |
| Emilia-NV | zh | ✗ | – | – |
| NVTTS | en | ✓ | ✗ | ✗ |
| SMIIP-NV | zh | ✓ | ✗ | ✗ |
| NV-Bench | zh/en | ✓ | ✓ | ✓ |
2. Методы
Для построения NV-Bench мы используем двухфазный пайплайн. Он балансирует акустическое разнообразие и точность меток. На первой фазе разрабатывается устойчивая многоязычная NVASR-модель для транскрипции с учётом невербальных событий. На второй фазе проводится курирование реального аудио через строгую фильтрацию с человеческой верификацией GT.
2.1. Многоязычный NVASR
Для эффективного построения бенчмарка мы разрабатываем многоязычную NVASR-модель (nonverbal vocalization automatic speech recognition — автоматическое распознавание речи с поддержкой невербальных вокализаций). Следуя методологии из Emilia-NV, мы файнтюним архитектуру SenseVoice-Small и расширяем фреймворк для многоязычных сценариев.
2.1.1. Архитектура модели
SenseVoice-Small выбрана как базовая модель благодаря предварительному обучению на разнообразных задачах понимания аудио. Это позволяет ей извлекать богатые акустические признаки. Модель оптимизируется минимизацией CTC-потери (connectionist temporal classification — функция потерь для выравнивания последовательностей без явной разметки границ):
ℒ_CTC = −ln ∑_{π∈ℬ⁻¹(𝐲)} P(π∣𝐱)
где 𝐱 — входные акустические признаки, 𝐲 — целевая последовательность, ℬ⁻¹(𝐲) — все валидные пути CTC-выравнивания для 𝐲.
2.1.2. Конструкция данных и нормализация меток
Для широкой генерализации мы объединяем комплексный тренировочный корпус: Emilia-NV, NVTTS, DisfluencySpeech, NVS, SMIIP-NV и MNV-17.
Чтобы справиться с разнородностью исходных меток, мы проводим систематическую нормализацию. Неречевые метки маппятся на уровень 3 онтологии AudioSet (иерархии звуковых событий от Google). При этом сохраняются дискретные события вроде [Laughter]. Мы принимаем таксономию Emilia-NV, но проводим целевую ручную аннотацию на английских подмножествах NVTTS и DisfluencySpeech. Это критически важно для различения нюансных прагматических функций, таких как [Question-huh], которых ранее не было в английских датасетах. Итоговая унифицированная таксономия — в таблице 2.
Таблица 2: Унифицированный инвентарь меток по коммуникативной функции.
| Язык | Вегетативные звуки | Аффективные всплески | Разговорные междометия |
|---|---|---|---|
| Китайский | Breathing, Cough, Sigh | Laughter, Surprise-ah, Surprise-oh, Dissatisfaction-hnn | Uhm, Confirmation-en, Question-ei, Question-ah, Question-en, Question-oh |
| Английский | Breathing, Cough, Sigh | Laughter, Surprise-oh | Uhm, Question-huh |
2.2. Конструкция бенчмарк-датасета
Надёжный NV-бенчмарк требует баланса между реализмом реальных записей и распределением меток. Датасет полностью курирован из веб-аудио через сложный фильтрующий пайплайн (рисунок 1).
2.2.1. Сбор данных
NV-события естественным образом распределены с длинным хвостом. Для достаточного покрытия таксономии мы собрали массивную коллекцию аудиовизуального контента, загруженного за последний год. Из исходного пула в 565 316 аудиоклипов (≈1 560 часов) мы отфильтровали сегменты-кандидаты с целевыми NV.
2.2.2. Пайплайн фильтрации
Для гарантии акустической точности и чистоты диктора кандидаты проходят строгую очистку:
Стандартизация аудио. Сначала Emilia-Pipeline используется для первичной стандартизации и разделения источников. Несмотря на встроенную диаризацию (автоматическое разделение речи по дикторам), многоспикерные сегменты часто сохраняются.
Проверка одного диктора. Для устранения остаточных артефактов мы разворачиваем MiMo-Audio-7B-Instruct — SOTA аудио-LLM. Она детектирует тонкие перекрытия дикторов, пропущенные при первичной диаризации. Сохраняются только подтверждённо чистые однодикторские высказывания.
Человеческая верификация. На финальном этапе десять экспертов-аннотаторов проверяют и корректируют транскрипции от NVASR. Они валидируют прагматическую корректность NV-меток. Для консистентности 5% данных перекрёстно аннотировано — Cohen’s kappa (метрика согласованности оценщиков) выше 0.85. Итог — 1 651 пара промпт/GT (7.9 часов), стандартизированных в MP3 при 24 кГц.
3. NV-Bench
Несмотря на рост числа TTS-систем с поддержкой NV, в области нет стандартизированного бенчмарка. Без него невозможно разделить два типа ошибок: (i) неспособность сгенерировать целевое событие, (ii) генерация низкокачественного или неестественного аудио. NV-Bench оценивает системы по двум измерениям:
Instruction Alignment — способность модели строго следовать текстовому промпту. Оценивается, генерирует ли система целевые NV-события в точных лингвистических позициях без пропусков и галлюцинаций.
Acoustic Fidelity — реализм относительно реальных записей. Измеряется распределительный разрыв, консистентность тембра и качество восприятия.
Для проверки этих возможностей при разной сложности NV-Bench структурирован в два многоязычных подмножества:
Однометочное подмножество — строго сбалансированный тестсет. Каждое высказывание содержит ровно одно NV-событие (50 примеров на категорию, 650 китайских и 350 английских). Это изолирует базовые генеративные возможности.
Многомечное подмножество — более сложный набор. Высказывания содержат несколько (2+) NV-событий для проверки устойчивости при плотных паралингвистических условиях. Учитывая длиннохвостовое распределение совместных встречаемостей, обеспечивается относительный баланс. Китайский: 41–91 пример на метку, английский: 75–112. Это даёт достаточное покрытие всех типов событий при отражении реальной сложности.
Таблица 3: Сравнение CER и OCER (%) по тестсетам, значения в скобках — OCER, остальные — CER.
| Датасет | SV | Qwen2.5-Omni | NVASR |
|---|---|---|---|
| WS-net | 5.77 | 20.14 | 5.55 |
| LS-other | 12.79 | 23.35 | 9.90 |
| SMIIP-NV | 3.12 | 3.59 (4.17) | 1.29 (1.36) |
| NVTTS | 14.45 | 21.69 (26.95) | 13.52 (16.10) |
Таблица 4: Детальные результаты по каждому подмножеству NV-Bench. Жирный — лучший в столбце, подчёркнутый — второй. Первые пять столбцов — однометочное подмножество (Alignment: CER, PCER, OCER; Fidelity: SIM, DNSMOS), последние пять — многомечное (Alignment: CER, PCER, OCER; Fidelity: SIM, DNSMOS).
| Система | CER (%) | PCER (%) | OCER (%) | SIM | DNSMOS | CER (%) | PCER (%) | OCER (%) | SIM | DNSMOS |
|---|---|---|---|---|---|---|---|---|---|---|
| Китайский | ||||||||||
| GT | 3.86 | 9.38 | 4.07 | 0.781 | 3.12 | 3.79 | 23.71 | 5.07 | 0.794 | 3.12 |
| Orpheus-TTS | 11.36 | 88.77 | 13.91 | - | 3.43 | 19.83 | 84.85 | 24.38 | - | 3.40 |
| SMIIP-NV-CV2 | 8.80 | 75.64 | 11.34 | 0.719 | 3.22 | 10.66 | 77.20 | 14.79 | 0.715 | 3.07 |
| Emilia-NV-CV2 | 5.05 | 40.00 | 6.64 | 0.740 | 3.21 | 5.54 | 48.74 | 8.09 | 0.746 | 3.24 |
| CosyVoice3 | 3.85 | 57.69 | 5.86 | 0.764 | 3.30 | 4.75 | 61.94 | 8.26 | 0.715 | 3.31 |
| NV-FlexiVoice | 6.98 | 31.08 | 8.15 | 0.748 | 3.22 | 8.20 | 39.37 | 10.39 | 0.750 | 3.07 |
| NV-CV3 | 3.80 | 27.69 | 4.90 | 0.768 | 3.29 | 3.44 | 30.04 | 4.84 | 0.776 | 3.29 |
| Английский | ||||||||||
| GT | 6.73 | 8.31 | 6.90 | 0.772 | 3.11 | 7.26 | 21.41 | 8.62 | 0.775 | 3.14 |
| Orpheus-TTS | 9.03 | 71.92 | 10.63 | - | 3.33 | 8.68 | 71.46 | 11.89 | - | 3.34 |
| SMIIP-NV-CV2 | 17.92 | 56.80 | 19.47 | 0.583 | 2.97 | 20.93 | 54.49 | 23.87 | 0.580 | 2.97 |
| Emilia-NV-CV2 | 12.50 | 55.30 | 13.21 | 0.639 | 3.21 | 11.71 | 60.28 | 14.63 | 0.655 | 3.26 |
| CosyVoice3 | 7.87 | 62.75 | 9.06 | 0.701 | 3.27 | 6.39 | 57.84 | 10.69 | 0.715 | 3.31 |
| NV-FlexiVoice | 11.88 | 50.43 | 13.21 | 0.685 | 3.15 | 9.60 | 51.32 | 13.76 | 0.708 | 3.07 |
| NV-CV3 | 8.33 | 46.13 | 9.44 | 0.698 | 3.24 | 6.70 | 47.13 | 10.10 | 0.721 | 3.30 |
4. Эксперименты
4.1. Эксперименты с многоязычным NVASR
Многоязычный NVASR выступает базовой моделью-оценщиком (backbone) в NV-Bench. Её нужно проверить как на стандартных ASR-тестсетах, так и на NV-специфичных.
4.1.1. Сетап и базовые модели
Мы сравниваем NVASR с двумя сильными базовыми моделями:
- SenseVoice-Small (SV) — оригинальная ASR-модель до файнтюнинга, как базовый уровень общего распознавания речи.
- Qwen2.5-Omni — 7B multimodal LLM с поддержкой понимания речи. Используется файнтюн-чекпоинт для NV-распознавания из MNV-17.
Оценка проводится на четырёх тестсетах: WenetSpeech test-net и LibriSpeech test-other для общего ASR; SMIIP-NV и NVTTS для NV-специфичной производительности.
4.1.2. Метрики оценки
Для совместной оценки лингвистической и паралингвистической точности мы расширяем стандартный CER до Overall CER (OCER):
OCER = (S + D + I) / (N_text + N_nvv) × 100%
где S, D, I — substitutions, deletions и insertions (замены, удаления и вставки), вычисленные по полной последовательности, включая NV-метки. N_text и N_nvv — количество текстовых символов и NV-символов соответственно.
4.1.3. Результаты
Как показано в таблице 3, наш многоязычный NVASR демонстрирует двойную компетентность. Во-первых, он сохраняет и даже незначительно улучшает качество транскрипции оригинальной SenseVoice на стандартных датасетах. Во-вторых, он значительно превосходит файнтюн-чекпоинт Qwen2.5-Omni в точности детекции и классификации NV-меток. На тестсете SMIIP-NV NVASR достигает 1.29% CER и 1.36% OCER, подтверждая свою надёжность как автоматического оценщика для NV-Bench.
Таблица 5: Оценка на полном NV-Bench.
| Система | FAD | FD | IMOS | NMOS |
|---|---|---|---|---|
| GT | - | - | 4.39 ± 0.18 | 4.39 ± 0.15 |
| Orpheus-TTS | 5.71 | 24.49 | 3.27 ± 0.23 | 3.53 ± 0.22 |
| SMIIP-NV-CV2 | 1.32 | 6.71 | 3.28 ± 0.22 | 3.28 ± 0.19 |
| Emilia-NV-CV2 | 1.08 | 5.57 | 3.89 ± 0.18 | 3.99 ± 0.14 |
| CosyVoice3 | 0.90 | 9.46 | 3.56 ± 0.22 | 3.94 ± 0.20 |
| NV-FlexiVoice | 0.29 | 2.72 | 3.94 ± 0.23 | 4.00 ± 0.18 |
| NV-CV3 | 0.86 | 3.94 | 3.95 ± 0.18 | 4.08 ± 0.16 |
4.2. Бенчмаркинг TTS-моделей с поддержкой NV
Мы проводим комплексную оценку на NV-Bench по двум измерениям. Instruction Alignment измеряет управляемость промптом и паралингвистическую разборчивость. Acoustic Fidelity оценивает распределительный разрыв, speaker similarity и перцептивное качество.
4.2.1. TTS-системы
- Orpheus-TTS — однодикторская Llama-based 3B-модель с явным NV-контролем.
- SMIIP-NV-CV2 и Emilia-NV-CV2 — две вариации 0.5B-модели CosyVoice2 (zero-shot TTS), файнтюненные соответственно на SMIIP-NV и Emilia-NV.
- CosyVoice3 (CV3) — базовая zero-shot модель как сильный бейзлайн для общего синтеза речи.
- NV-FlexiVoice — файнтюн 0.5B-модели FlexiVoice, предварительно обученной на Emilia без NV-событий.
- NV-CV3 — референсный бейзлайн высокого уровня: файнтюн CV3 на объединённом корпусе.
4.2.2. Экспериментальный сетап
Конфигурация обучения. CV3 и FlexiVoice файнтюнятся на объединённом корпусе из Emilia-NV, SMIIP-NV, NVTTS, Disfluency и NVS. Нормализованные NV-метки инжектируются в текст как специальные управляющие символы. Оптимизация — AdamW (lr=1×10⁻⁵) на 4 NVIDIA A800.
Инференс. Все модели следуют протоколу нормализации меток. Для базовых моделей с ограниченной NV-поддержкой оценивается только пересечение поддерживаемых событий. Неподдерживаемые междометия (например, [Question-huh]) маппятся на ближайшие лексические эквиваленты с пунктуацией (например, «huh?»). Это позволяет аппроксимировать прагматическую функцию.
4.2.3. Метрики оценки
Instruction alignment. NVASR используется для вычисления CER, OCER и PCER. Для изоляции точности генерации NV PCER вычисляется только на извлечённых NV-символах: PCER = (S_nvv + D_nvv + I_nvv) / N_nvv. Здесь S_nvv, D_nvv, I_nvv — операции редактирования (замены, удаления, вставки) над NV, а N_nvv — целевое количество NV.
Acoustic Fidelity. Перцептивное качество и консистентность тембра измеряются через DNSMOS (метрика качества речи от Microsoft) и WavLM-based Speaker Similarity (SIM). Распределительный разрыв оценивается через Fréchet Audio Distance (FAD) и FD от PANNs (расстояние между распределениями аудиопризнаков).
Человеческая оценка. Десять аннотаторов оценивали по 100 высказываний на модель по 5-балльной шкале. Оценка проводилась по двум измерениям:
- NMOS (Naturalness) — акустическая точность, просодическая непрерывность текст-NV и консистентность диктора.
- IMOS (Instruction Accuracy) — точность исполнения NV без пропусков, галлюцинаций и ошибок произношения.
4.2.4. Результаты и анализ
Таблица 4 показывает результаты по китайскому и английскому подмножествам. По instruction alignment NV-CV3 достигает минимального PCER (27.69%) и OCER (4.90%) на китайском однометочном подмножестве. Это демонстрирует превосходную управляемость благодаря масштабным и диверсифицированным тренировочным данным.
По acoustic fidelity NV-CV3 сохраняет сильную консистентность тембра CV3, а Orpheus-TTS набирает высший балл DNSMOS. Таблица 5 показывает, что NV-FlexiVoice достигает минимальных FAD и FD. Сгенерированная речь и NV-события ближе всего к реальному распределению.
Субъективные оценки подтверждают эти результаты: NV-CV3 получает высшие NMOS и IMOS. Важно, что IMOS показывает значимую отрицательную корреляцию Спирмена с PCER (ρ=−0.65, p<0.001), а NMOS коррелирует с FD. Это валидирует надёжность объективных метрик NV-Bench.
5. Заключение
Мы представляем NV-Bench — первый комплексный бенчмарк для TTS-систем с поддержкой NV. Основанный на функциональной таксономии, бенчмарк содержит 1 651 многоязычных референса из реальных записей с парным человеческим ground-truth. Они сбалансированы по 14 категориям в однометочных и многомечных подмножествах. NV-Bench раздельно оценивает acoustic fidelity и instruction alignment, разделяя качество аудио и паралингвистическую управляемость. Масштабные эксперименты подтверждают, что наши объективные метрики сильно коррелируют с человеческими оценками. Это закрепляет за NV-Bench роль стандартизированного фреймворка оценки.
6. Раскрытие использования генеративного ИИ
LLM использовался исключительно для улучшения ясности и грамматики текста. Авторы проверили и отредактировали результат для обеспечения точности.