
Мы обучаем Composer решать задачи с длинным горизонтом через reinforcement learning (обучение с подкреплением). Мы назвали этот метод self-summarization (самосжатие). Встроив самосжатие в процесс обучения, мы получаем обучающий сигнал из траекторий (последовательностей действий агента). Эти траектории значительно превышают максимальное контекстное окно модели. В результате Composer учится решать сложные кодинговые задачи, требующие сотен действий.
Ограничения методов сжатия контекста
В CursorBench, нашем внутреннем бенчмарке, мы видим прямую корреляцию: чем сложнее реальная задача по коду, тем больше нужно «мышления» и исследования кодовой базы. По мере того как пользователи поручают агентам всё более амбициозные задачи, отдача от глубокого анализа будет только расти.
Главная проблема — траектории агента удлиняются быстрее, чем растёт контекстное окно моделей. Многие agentic-фреймворки пытаются обойти это через compaction (сжатие) как промежуточный шаг в рабочем цикле: когда агент упирается в лимит контекста, фреймворк сжимает его и продолжает генерацию с того места, где агент остановился.
На практике сжатие обычно реализуется двумя путями: через текстовое пространство с помощью промптовой модели-саммаризатора, либо через скользящее окно, где модель отбрасывает старый контекст. Появляются и методы сжатия в latent space (скрытом пространстве — модель запоминает контекст в виде векторов, а не текста), но пока они значительно медленнее текстовых подходов.
У всех этих методов общий недостаток: модель может потерять критически важную информацию из контекста, что снижает её эффективность на длинных задачах.
Самосжатие как обучаемое поведение
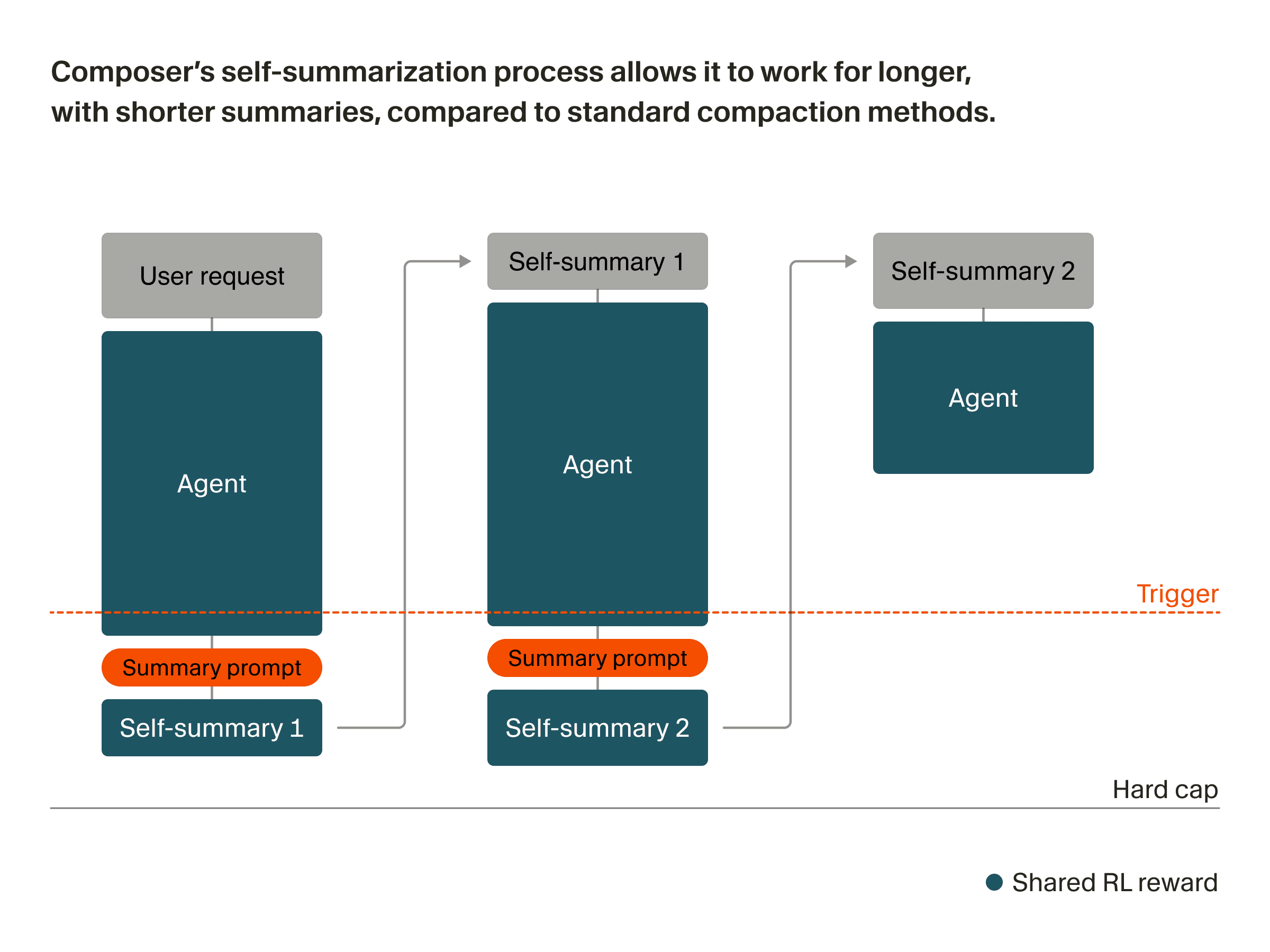
Composer — специализированная модель для agentic-кодинга, обученная через reinforcement learning внутри фреймворка Cursor. Это позволяет обучать её с compaction-in-the-loop (сжатием внутри цикла): сжатие встроено прямо в тренировочный цикл, и модель учится определять, какую информацию критически важно сохранить.
Процесс самосжатия выглядит так:
- Composer генерирует ответ до тех пор, пока не достигнет триггера по длине в токенах.
- Мы вставляем синтетический запрос, прося модель сжать текущий контекст.
- Модель получает черновое пространство (scratch space) для размышлений, а затем генерирует сжатый контекст.
- Composer возвращается к шагу 1 с сжатым контекстом, который включает саммари плюс состояние разговора (текущий план, оставшиеся задачи, количество предыдущих сжатий и т. д.).
Чтобы модель хорошо справлялась с этим на инференсе (при генерации ответов), мы встраиваем ту же процедуру сжатия в обучение. Каждый training rollout (прогон модели во время обучения) может содержать несколько генераций, связанных саммари, — а не одну пару «промпт–ответ». Это значит, что сами саммари становятся частью того, что получает награду.
Технически это не требует серьёзных изменений в обучении. Мы используем финальную награду для всех токенов, сгенерированных моделью в цепочке. Это повышает вес как удачных ответов агента, так и самосжатий, которые к ним привели. Параллельно понижается вес плохих саммари, потерявших критическую информацию. В процессе обучения Composer учится использовать самосжатие для построения более длинного контекста. На сложных примерах он часто сжимает себя многократно.
Экономное сжатие по токенам
Для проверки самосжатия мы сравнили его с тщательно настроенным промптовым baseline-методом (базовым методом для сравнения). Тестировали на наборе сложных инженерных задач, варьируя триггер сжатия.
В baseline-подходе промпт для сжатия занимает тысячи токенов и содержит около десятка тщательно сформулированных секций с описанием того, что нужно сохранить. Сжатый контекст в среднем превышает 5 000 токенов и содержит множество структурированных секций.
У Composer всё иначе: поскольку модель обучена самосжиматься, ей нужен минимальный промпт, по сути — «Пожалуйста, сожми разговор». Выходные саммари в среднем составляют около 1 000 токенов — модель контекстуально учится выбирать высокоценную информацию для сохранения.
Мы тестировали Composer в двух средах с ограниченным контекстом: с триггером 80k токенов и с триггером 40k (более частое сжатие). В обоих сценариях самосжатие показывает значительно лучшие результаты на CursorBench при гораздо более экономном расходе токенов. Самосжатие стабильно снижает ошибку от compaction на 50% даже по сравнению с целевым baseline-подходом. При этом используется пятая часть токенов и переиспользуется KV cache (хранящиеся промежуточные вычисления от предыдущих токенов).

Решение сложных задач
Главная перспектива сжатия — позволить моделям решать за один проход задачи, требующие длинных цепочек рассуждений. При текущем обучении Composer 2 мы регулярно наблюдаем именно это. В качестве кейса возьмём задачу из Terminal-Bench 2.0 — make-doom-for-mips. Формулировка кратка, но задача нетривиальна:
Я предоставил /app/doomgeneric/ — исходный код Doom. Также я написал специальный doomgeneric_img.c, который будет записывать каждый отрисованный кадр в /tmp/frame.bmp. Наконец, я дал vm.js, который ожидает файл doomgeneric_mips и запустит его. Разберись с остальным сам…
Описание простое, но задача настолько сложна, что несколько мощных моделей не справляются с ней по официальным результатам.
При тестировании раннего research-чекпоинта (промежуточной версии из исследовательского этапа) Composer мы обнаружили, что модель смогла решить эту задачу корректно. Решение потребовало написания и тестирования большого объёма кода, а также исследования альтернативных реализаций. Вот кадр, отрисованный в процессе решения:

Всего Composer проработал 170 ходов, чтобы найти точное решение, создавая по пути самосжатия в компактной, структурированной и читаемой форме. Модель сжала более 100 000 токенов до 1 000 — тех, которые, по её оценке, больше всего помогли бы в решении.
К будущему с длинным горизонтом
Встроив сжатие в тренировочный цикл, Composer получил явный механизм для эффективного переноса критической информации вперёд — и стал более способен решать сложные задачи. Наша работа над самосжатием — шаг к более широкой цели: обучать Composer на ещё более длинных и сложных процессах, таких как multi-agent coordination (взаимодействие нескольких агентов). Мы продолжаем рассматривать улучшение обучения моделей как способ расширения масштаба и интеллекта agentic-систем.
Вскоре мы поделимся подробностями о следующей версии Composer.