
Yujia Yang, Yuanxiang Wang, Zhenyu Guan, Tiankun Yang, Chenxi Bao, Haopeng Jin, Jinwen Luo, Xinyu Zuo, Lisheng Duan, Haijin Liang, Jin Ma, Xinming Wang, Ruiwen Tao, Hongzhu Yi — University of Chinese Academy of Sciences, Tencent
https://github.com/Young-2000/OmniIIEBench
Модели редактирования изображений по текстовой инструкции (Instruction-based Image Editing, IIE) развиваются стремительно. Но существующие бенчмарки оценивают их по принципу «чем больше задач, тем лучше», смешивая разные типы правок. Это скрывает критическую проблему: модели ведут себя непоследовательно при переходе между задачами разного семантического масштаба (низкоуровневые правки — изменение атрибутов вроде цвета, высокоуровневые — замена объектов). Omni IIE Bench — новый бенчмарк с двумя диагностическими треками и многоступенчатой ручной фильтрацией, созданный для выявления таких слабостей.
Постановка проблемы
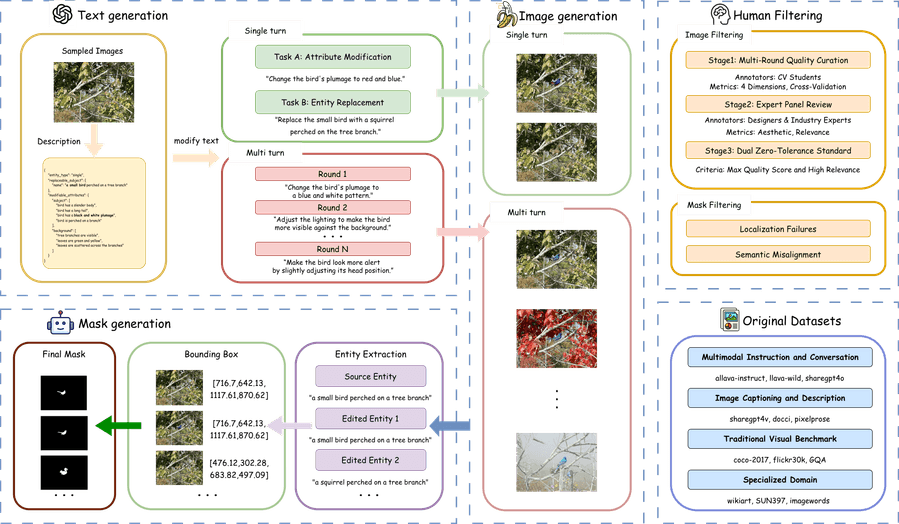
Рисунок 1: Omni IIE Bench собирает исходные изображения из 12 датасетов и использует GPT-4o для генерации описаний. Описания затем модифицируются с помощью GPT-4o. Для одноповоротных диалогов семантические масштабы задаются на низком и высоком уровнях; для многоповоротных — модификации чередуются между двумя уровнями. После этого оригинальные описания, модифицированные описания и оригинальные изображения подаются в Nano Banana (модель генерации изображений) для создания целевых изображений. Результаты обрабатываются через GroundingDINO (модель обнаружения объектов) и SAM (модель попиксельной сегментации) для получения масок. Все сгенерированные изображения и маски проходят строгую ручную проверку.
Ранние бенчмарки IIE оценивали только одноповоротные диалоги — может ли модель выполнить одну инструкцию. Инструкции делились на модификацию атрибутов (измени цвет) и замену сущностей (замени объект). Но в реальном рабочем процессе дизайнеры правят изображения итеративно, за множество шагов.
Недавние работы начали исследовать многоповоротное редактирование, но ограничиваются 2–3 раундами. Этого недостаточно для оценки реальных возможностей модели. Кроме того, ни один из существующих бенчмарков не валидирован практикующими дизайнерами — отсюда разрыв между идеализированными метриками и реальной применимостью.
Omni IIE Bench решает эти проблемы:
- Качественный датасет. 1 725 одноповоротных диалогов и 260 многоповоротных (до 16 шагов в каждом). Всё проходит через многоэтапную ручную фильтрацию.
- Раздельная методология оценки. Три измерения: глобальное качество изображения, региональная точность (foreground и background отдельно) и соблюдение инструкции.
- Системная диагностика 8 моделей. Qwen-image-edit, MGIE, InstructPix2Pix, ICEdit, HIVE, HQEdit, FLUX, Step1X — с человеческой валидацией результатов.
Родственные работы
Таблица 1: Сравнение IIE-бенчмарков по ключевым диагностическим измерениям.
Одноповоротные бенчмарки стремятся к максимальному покрытию задач. Но смешанная оценка маскирует различия в поведении моделей на задачах разного семантического масштаба. I2EBench разделяет high-level и low-level правки через иерархический дизайн, но оценивает их изолированно — без проверки стабильности при переключении масштабов в рамках одного изображения.
Многоповоротные бенчмарки фокусируются на временной согласованности (temporal consistency). CompBench поддерживает многоповоротное редактирование и разделяет инструкции на четыре измерения, но тоже сообщает метрики изолированно — без количественной оценки согласованности между низко- и высокомасштабными задачами. ImgEdit-Bench оценивает память содержимого и откат версий, MUCIE — удержание инструкций и рассуждений. Ни одна из этих работ не рассматривает стабильность модели при динамическом изменении семантического масштаба правок.
Датасет Omni IIE Bench
Omni IIE Bench строится на двух ключевых принципах: диагностическая мощность (дополняющие друг друга одноповоротный и многоповоротный треки) и строгая проверка (ручная экспертиза профессиональных дизайнеров и CV-исследователей).
Сбор и источники данных
Начальный пул изображений выбран из 12 публичных датасетов, разбитых на четыре категории:
- Мультимодальные инструкции и диалоги: allava-instruct, llava-wild, sharegpt4o
- Подписи и описания изображений: sharegpt4v, docci, pixelprose
- Классические визуальные бенчмарки: coco2017val, flickr30k, GQA
- Специализированные домены: wikiart, SUN397, imageinwords
Все сэмплы используют фиксированный seed=42. Для одноповоротного трека из каждого датасета взяты по 200 изображений (2 400 штук). Для многоповоротного — по 58 (696 штук).
Пайплайн генерации и аннотации
Все сэмплы организованы как четвёрки (I_source, T_mod, I_gt, M_gt): исходное изображение, инструкция редактирования, целевое изображение и ground-truth маска (эталонная маска области правки).
Многоповоротный трек содержит 696 наборов диалогов с чередованием масштабов. В них инструкции динамически перемежают модификацию атрибутов и замену сущностей.
Этап 1: Автоматическая генерация кандидатов
- Описания изображений. GPT-4o генерирует детальные описания сцен для всех исходных изображений — объекты, атрибуты, действия, окружение.
- Генерация инструкций. GPT-4o создаёт наборы инструкций: для одноповоротного трека — пары с противоположной семантикой, для многоповоротного — последовательности с чередованием масштабов.
- GT-изображения. Nano Banana обеспечивает высокую точность генерации.
Этап 2: Автоматическая генерация масок
GroundingDINO требует чётких имён существительных, поэтому напрямую подавать полную инструкцию нельзя. GPT-4o выступает парсером: извлекает ключевое существительное — носитель атрибута или заменяемую сущность. Затем извлечённые существительные передаются в Grounded-SAM: GroundingDINO находит bounding boxes (прямоугольные рамки вокруг объектов), SAM выполняет instance segmentation (попиксельное выделение каждого объекта) и генерирует бинарную маску M_gt.
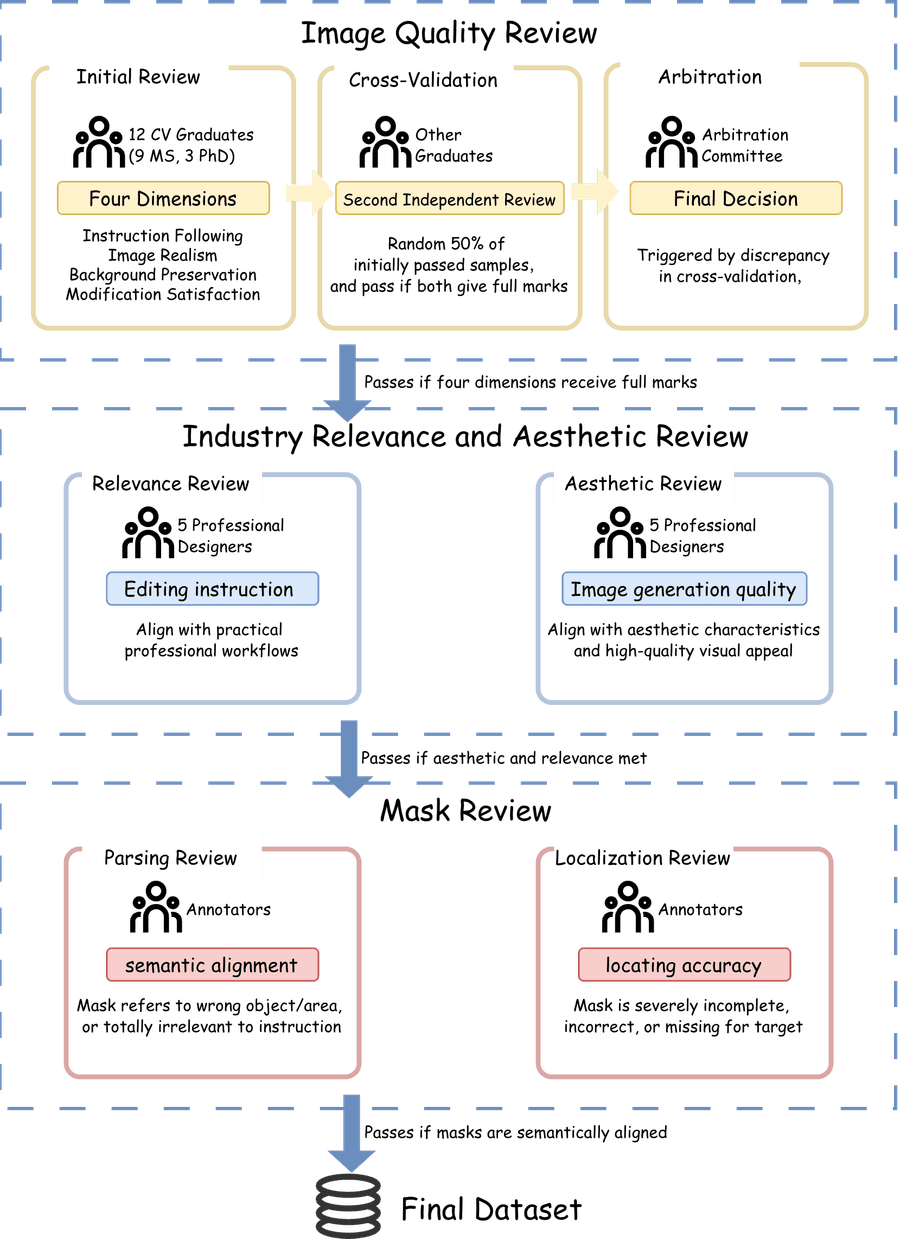
Рисунок 2: Обзор ручной кураторской фильтрации
Этап 3: Ручная кураторская фильтрация
Самый критичный этап. Команда: 12 аспирантов по компьютерному зрению и 5 AI-дизайнеров. Перед началом — калибровка: выравнивание стандартов по артефактам, семантическому дрейфу, загрязнению фона.
Оценка качества изображения по четырём измерениям (шкала 1–3):
- Instruction Following: соответствие инструкции
- Image Realism: естественность, отсутствие артефактов
- Background Preservation: целостность нередактируемых областей
- Modification Satisfaction: общая приемлемость результата
Workflow: 9 магистрантов и 3 аспиранта оценивают каждый сэмпл. 50% прошедших выборочно проверяются вторым аннотатором. При совпадении максимальных оценок — проход. При расхождении — Арбитражный комитет из 5 дизайнеров решает голосованием.
Оценка индустриальной релевантности и эстетики. Прошедшие первичный фильтр сэмплы проверяются командой из 5 профессиональных дизайнеров: соответствует ли качество и инструкция реальным рабочим процессам в рекламе, e-commerce, концепт-арте. Неподходящие — отбрасываются.
Проверка масок. Быстрая оценка семантического соответствия маски инструкции (pass/fail). Цель — отсеять сэмплы с серьёзными ошибками локализации.
Итоговый критерий: строгий двойной фильтр. Сэмпл принимается только при максимальных оценках по всем четырём измерениям качества и признании релевантным дизайнерами. Осталось 2 856 изображений.
Статистика датасета
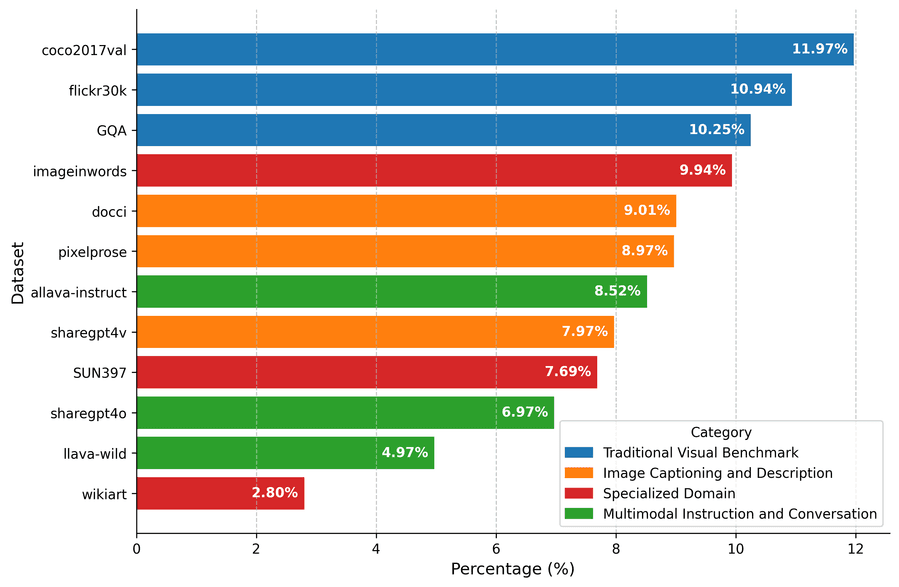
Рисунок 3: Распределение источников данных в Omni IIE Bench
Пайплайн фильтрации. Одноповоротный трек: из 4 800 кандидатов только 50,86% прошли оценку качества, затем ещё 29,33% отброшены дизайнерами за нерелевантность. Итоговый acceptance rate — 35,94% (1 725 сэмплов). Многоповоротный трек: из 696 диалогов (5 421 изображение) — 37,36% групп и 20,86% изображений. Общий итог: 2 856 из 10 221 кандидата.
Распределение по источникам сбалансировано — крупнейший источник занимает 11,97%, что исключает смещение к конкретному типу данных.
Атрибуты масок подтверждают разделение на семантические масштабы: площади масок при модификации атрибутов концентрируются в узком диапазоне, при замене сущностей — распределены шире.
Многоповоротные атрибуты: 260 диалогов, средняя глубина 4,35 шага. В 1 131 правке зафиксировано 322 переключения «атрибут → сущность» и 178 «сущность → атрибут».
Таблица 2: Сравнение IIE-моделей на одноповоротном треке. Цвета текста указывают на top performances: 1st, 2nd, 3rd. Стрелки (↑/↓) указывают, лучше ли большее или меньшее значение. Overall score вычисляется по формуле 1/4[(3−ΣLPIPS)/3 + ΣCLIP/3 + QA + SSIM], где ΣLPIPS и ΣCLIP — суммы по столбцам FG, BG и ALL.
Таблица 3: Сравнение IIE-моделей на многоповоротном треке. Цвета текста указывают на top performances: 1st, 2nd, 3rd. Стрелки (↑/↓) указывают, лучше ли большее или меньшее значение.
Методология оценки
Раздельный фреймворк с тремя измерениями: глобальное качество, региональная точность, соблюдение инструкции.
Пайплайн и препроцессинг
Все изображения ресемплируются до 768×768 (lanczos-интерполяция). Маски — до 768×768 (nearest-интерполяция для сохранения резкости бинарных границ). Foreground-маска M_fg = M_gt, background-маска M_bg = 1 − M_gt.
Глобальные метрики качества
Четыре стандартные метрики для сравнения I_gen и I_gt: PSNR и SSIM — пиксельная точность и структурное сходство. LPIPS — перцептивное сходство как взвешенное расстояние между глубокими признаками:
LPIPS(x, x₀) = Σ_l (1 / H_l·W_l) Σ_{h,w} ‖w_l ⊙ (Ĥ^l_{hw}(x) − Ĥ^l_{hw}(x₀))‖₂²
CLIP Score — глобальная семантическая согласованность как косинусное сходство между CLIP-эмбеддингами:
CLIP(I₁, I₂) = E_I(I₁) · E_I(I₂) / (‖E_I(I₁)‖ · ‖E_I(I₂)‖)
Раздельные метрики региональной точности
Глобальные метрики усредняют локальные ошибки, поэтому оценка разделяется на foreground (область правки) и background (остальное изображение).
Editing Fidelity (точность редактирования). Сравнение I_gen и I_gt в области M_fg. Пиксели вне M_fg обнуляются, затем вычисляются FG-LPIPS и FG-CLIP:
FG-LPIPS = LPIPS(I_gen^fg, I_gt^fg) FG-CLIP = CLIP(I_gen^fg, I_gt^fg)
Background Fidelity (точность сохранения фона). Аналогично для M_bg — foreground-пиксели обнуляются, вычисляются BG-LPIPS и BG-CLIP:
BG-LPIPS = LPIPS(I_gen^bg, I_gt^bg) BG-CLIP = CLIP(I_gen^bg, I_gt^bg)

Рисунок 4: Визуализация одноповоротной и многоповоротной согласованности для нескольких моделей
Эксперименты
Метрики соблюдения инструкции
Метрики image-to-image не оценивают, следует ли I_gen инструкции T_mod. Решение — автоматическая генерация QA-пар и MLLM-рефери (мультимодальная языковая модель, способная анализировать изображения).
- Генерация QA-пар. GPT-4o генерирует 1–3 верифицируемых вопроса с правильными ответами для каждой инструкции.
- MLLM-рефери. GPT-4o получает I_gen, вопрос и ответ, возвращает True/False.
- Оценка. Жёсткая политика: 1.0 только если все QA-пары True, иначе 0.0.
Экспериментальная настройка
Оценены 8 моделей: Qwen-image-edit, MGIE, InstructPix2Pix, ICEdit, HIVE, HQEdit, FLUX, Step1X. Метрики — раздельный фреймворк из раздела 4.
Диагностика одноповоротной согласованности
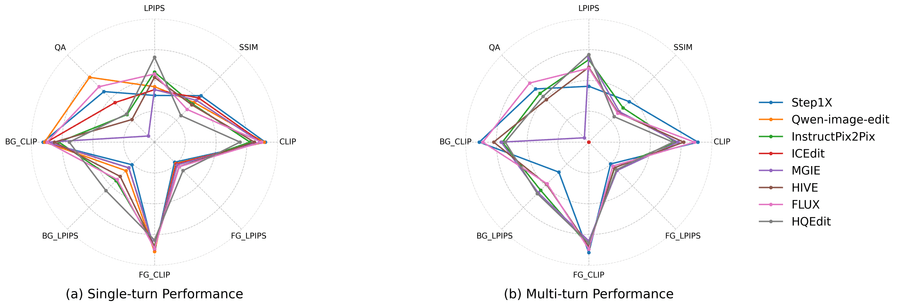
Рисунок 5: Сравнение 8 IIE-моделей по 8 метрикам на Omni IIE Bench. Нормализованные оценки для (a) одноповоротного и (b) многоповоротного треков.
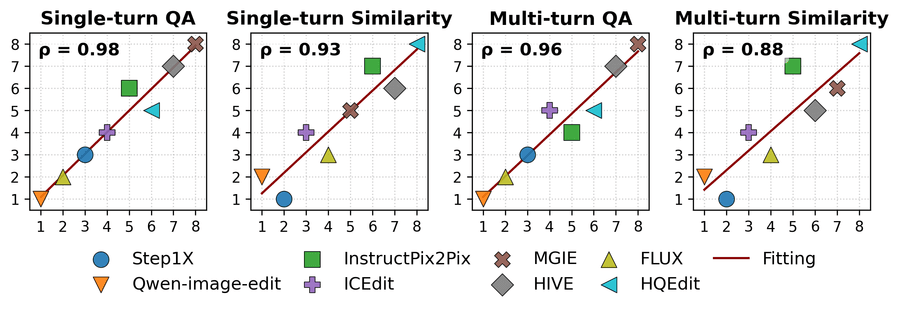
Рисунок 6: Согласованность ранжировок Omni IIE Bench (ось Y) и человеческой оценки (ось X).
Общие результаты. Qwen-image-edit показывает лучший результат, HQEdit — худший. Выявлен существенный разрыв между качеством генерации и соблюдением инструкции: MGIE генерирует качественные изображения, но практически не следует инструкциям. На бенчмарках без оценки instruction compliance MGIE получал бы высокие оценки — Omni IIE Bench эту проблему выявляет. На примерах (Рисунок 4) видно, что Qwen-Image-Edit превосходит остальные модели, тогда как выходы MGIE почти идентичны оригиналу.
Влияние семантического масштаба. Детальный анализ приведён в Приложении B. Кратко: переход от низкого к высокому семантическому масштабу приводит к деградации практически у всех моделей.
Диагностика многоповоротной координации
Общие результаты. Из-за накопления ошибок производительность всех моделей на многоповоротном треке снижается. Qwen-Image-Edit и Step1X остаются относительно стабильными, MGIE деградирует ещё сильнее.
Соблюдение инструкций. В многоповоротном сценарии инструкции короче, поэтому QA-генерация проще и оценки выше, чем в одноповоротном треке. Это артефакт настройки оценки, а не реальное улучшение моделей.
Сохранение фона. Многоповоротные диалоги вызывают заметное падение качества сохранения фона у всех моделей. В реальных сценариях, где дизайнеры выполняют множество правок подряд, ошибки накапливаются — это ключевое ограничение текущих моделей.
Согласованность с человеческой оценкой
Для валидации метрик проведён эксперимент: четыре оценщика (два PhD по CS и два профессиональных дизайнера) ранжировали 100 одноповоротных и 20 многоповоротных диалогов по соблюдению инструкции и сходству с GT (шкала 1–3).
Ранжировки Omni IIE Bench сопоставлены с человеческими на 2D-графике. Коэффициенты корреляции всех метрик превышают 0,85, что подтверждает точность и репрезентативность оценки.
Выводы
Omni IIE Bench заполняет пробел между бенчмарковой производительностью и реальной применимостью IIE-моделей. Ключевые находки:
- Даже state-of-the-art модели существенно теряют в точности, семантической корректности и сохранении фона при переходе от низко- к высокомасштабным задачам.
- В многоповоротных диалогах накопление ошибок приводит к деградации почти всех моделей.
- Существенный разрыв между качеством генерации и соблюдением инструкции — проблема, которую большинство бенчмарков не замечают.
Omni IIE Bench даёт диагностические инструменты для разработки более надёжных и стабильных моделей редактирования изображений.
Приложение A. Примеры из Omni IIE Bench
Примеры GT-изображений и соответствующих инструкций для одноповоротных диалогов на низком и высоком семантических уровнях, а также многоповоротных диалогов.

Рисунок 7: Примеры одноповоротных правок низкого уровня

Рисунок 8: Примеры одноповоротных правок высокого уровня

Рисунок 9: Примеры многоповоротных правок
Приложение B. Детали метрик одноповоротных диалогов
Независимо от модели, правки высокого семантического масштаба выполняются хуже, чем низкого. Подробности — в Таблицах 4 и 5.
Таблица 4: Сравнение IIE-моделей на группе Low (метрики сгруппированы по категориям). Цвета текста указывают на top performances: 1st, 2nd, 3rd. Стрелки (↑/↓) указывают, лучше ли большее или меньшее значение. Overall score вычисляется по формуле 1/4[(3−ΣLPIPS)/3 + ΣCLIP/3 + QA + SSIM], где ΣLPIPS и ΣCLIP — суммы по столбцам FG, BG и ALL.
Таблица 5: Сравнение IIE-моделей на группе High (метрики сгруппированы по категориям). Цвета текста указывают на top performances: 1st, 2nd, 3rd. Стрелки (↑/↓) указывают, лучше ли большее или меньшее значение. Overall score вычисляется по формуле 1/4[(3−ΣLPIPS)/3 + ΣCLIP/3 + QA + SSIM], где ΣLPIPS и ΣCLIP — суммы по столбцам FG, BG и ALL.
Приложение C. Примеры описаний изображений и инструкций редактирования
Рисунок 10: Пример JSON-описания в бенчмарке.
{
"replaceable_subject": {
"name": "a hooded figure in a brown robe"
},
"modifiable_attributes": {
"subject": [
"robe is brown",
"figure is hooded",
"hands are clasped",
"posture is upright"
],
"background": [
"background is dark and shadowy",
"lighting is dramatic and focused on the figure"
]
}
}Рисунок 11: Пример JSON-описания в бенчмарке.
{
"replaceable_subject": {
"name": "a brown bird with a long tail"
},
"modifiable_attributes": {
"subject": [
"feathers are brown",
"tail is long and dark",
"beak is curved and pointed",
"legs are slender and gray"
],
"background": [
"floor is tiled and beige",
"pillar is gray and cylindrical",
"partial view of a black object (possibly a chair or table)"
]
}
}Рисунок 12: Пример JSON-описания в бенчмарке.
{
"replaceable_subject": {
"name": "a modern bathroom interior"
},
"modifiable_attributes": {
"subject": [
"vanity cabinet is dark wood",
"sink is white ceramic",
"toilet is white ceramic",
"shower curtain is beige with a floral pattern",
"tub is white ceramic",
"mirror is framed in gold"
],
"background": [
"walls are painted beige",
"floor is light wood",
"lighting is warm and ambient"
]
}
}Рисунок 13: Пример JSON одноповоротной модификации в бенчмарке.
{
"modifications": [
{
"level": "low",
"modification_text": "Change the color of the robe from brown to black."
},
{
"level": "high",
"modification_text": "Replace the hooded figure in a brown robe with a cloaked wizard wearing a pointy hat."
}
]
}Рисунок 14: Пример JSON одноповоротной модификации в бенчмарке.
{
"modifications": [
{
"level": "low",
"modification_text": "Change the feathers of the brown bird to be white."
},
{
"level": "high",
"modification_text": "Replace the brown bird with a gray rabbit."
}
]
}Рисунок 15: Пример JSON многоповоротной модификации в бенчмарке.
{
"modifications": [
{ "level": "1", "modification_text": "Change the color of the vanity cabinet to a lighter oak tone." },
{ "level": "2", "modification_text": "Replace the floral pattern of the shower curtain with a geometric pattern." },
{ "level": "3", "modification_text": "Change the lighting to a cooler, brighter tone." },
{ "level": "4", "modification_text": "Replace the gold frame of the mirror with a silver frame." },
{ "level": "5", "modification_text": "Change the color of the walls to a light gray." },
{ "level": "6", "modification_text": "Replace the white ceramic sink with a black granite sink." },
{ "level": "7", "modification_text": "Change the floor to a darker wood tone." },
{ "level": "8", "modification_text": "Replace the white ceramic toilet with a black ceramic toilet." },
{ "level": "9", "modification_text": "Change the white ceramic tub to a black granite tub." },
{ "level": "10", "modification_text": "Replace the light gray walls with a dark gray color." },
{ "level": "11", "modification_text": "Replace the vanity cabinet with a marble countertop and a black frame." },
{ "level": "12", "modification_text": "Replace the shower curtain with a clear glass shower door." }
]
}