

Научный подход не допускает веры на слово — любое утверждение становится фактом только после проверки. Знания не исключение: школы и университеты измеряют их экзаменами. С появлением генеративных ИИ не утихают споры о достоверности выдаваемой ими информации. Старые тесты перестали работать: модели попросту решают их с высокой точностью. Поэтому исследователи из Техасского университета A&M создали HLE (Humanity’s Last Exam) — всеобъемлющий бенчмарк экспертного уровня. Как устроен тест и что показали ведущие модели — разбираемся по их докладу.
Основа исследования
Возможности больших языковых моделей (LLM от large language model) значительно продвинулись. Во многих задачах они уже превосходят человека. Для систематической оценки используются бенчмарки — наборы вопросов по математике, программированию, биологии и другим дисциплинам. Проблема в том, что современные LLM достигают более 90% точности на бенчмарках вроде MMLU (Measuring Massive Multitask Language Understanding), которые ещё недавно считались крайне сложными. Существующие тесты исчерпали себя: по ним невозможно точно измерять прогресс, нужны более сложные оценки.
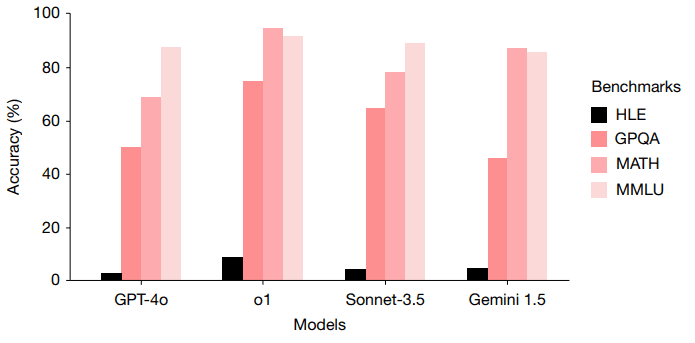
HLE — бенчмарк из 2500 вопросов экспертного уровня. Он охватывает десятки предметных областей — от гуманитарных до естественных наук. Вопросы составлены учёными и предметными экспертами. Они оригинальны, однозначны и не гуглятся. Тест многомодальный (содержит как текст, так и изображения). Форматы два: с точным совпадением ответа и с множественным выбором (из пяти и более вариантов). Акцент сделан на математических задачах высокого уровня, которые проверяют глубокие навыки рассуждения.
Каждый вопрос перед включением проходил многоэтапную фильтрацию. Сначала его проверяли на современных LLM: если модель сразу давала правильный ответ — вопрос отбраковывался. Затем следовала двухэтапная экспертная рецензия. Сначала — обратная связь от магистрантов и аспирантов. Потом — утверждение организатором и рецензентом-экспертом.
Подготовка к экзамену
Набор данных
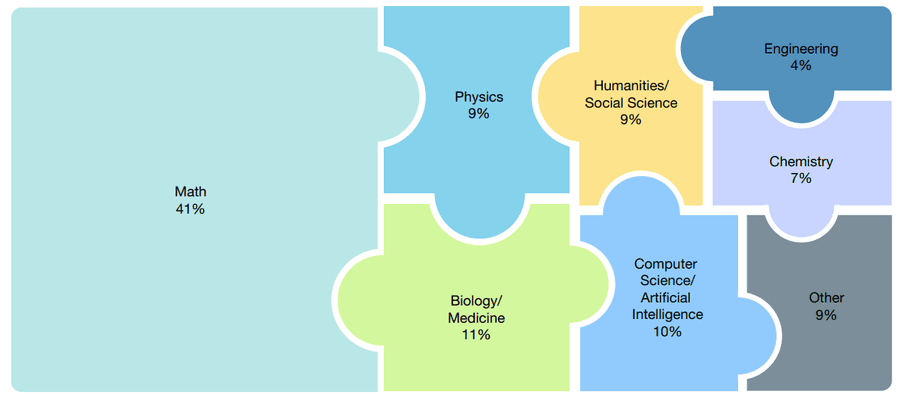
HLE — глобальный проект. Около 1000 экспертов из 500+ учреждений в 50 странах (в основном профессора и исследователи) подготовили вопросы по более чем 100 предметам. Примеры задач показаны ниже.

Около 14% вопросов — многомодальные (требуют понимания текста и изображения), 24% — с множественным выбором, остальные — с точным совпадением ответа.
Каждый вопрос содержал текст задачи, описание ответа, подробное обоснование решения, академическую специальность, имя автора и принадлежность к учреждению. Требования к вопросам были жёсткими: точность, однозначность, решаемость, невозможность найти ответ поиском. Вопросы должны были требовать знаний уровня магистратуры или касаться узкоспециализированных тем. Если LLM давала правильный ответ с ошибочными рассуждениями — авторам предписывалось менять параметры (например, число вариантов). Использовался ясный английский с точной терминологией и нотацией LaTeX где нужно. Открытые вопросы, субъективные интерпретации и контент про оружие массового поражения запрещались.
Проверка вопросов
Каждый вопрос сначала прогонялся через несколько передовых LLM. Если модели не решали его (или в среднем показывали результат хуже случайного угадывания в задачах с выбором), вопрос уходил на экспертную оценку. Всего было зафиксировано более 70 000 попыток. В результате около 13 000 вопросов, поставивших LLM в тупик, поступили к экспертам.
Экспертная рецензия состояла из двух этапов. Первый — итеративное улучшение: каждый вопрос получал от одного до трёх отзывов. Авторы по отзывам формулировали задачу так, чтобы она была закрытой, надёжной и пригодной для автоматической оценки. Второй — финальный отбор и утверждение лучших вопросов организаторами и рецензентами для включения в HLE.
Для финальной оценки использовалась стандартизированная системная подсказка (system prompt). Она требовала от модели явного обоснования с последующим окончательным ответом. Поскольку ответы точные и закрытые, для проверки правильности применялась модель o3-mini как оценщик. При этом учитывались эквивалентные форматы (например, десятичные дроби vs обыкновенные).
Результаты исследования
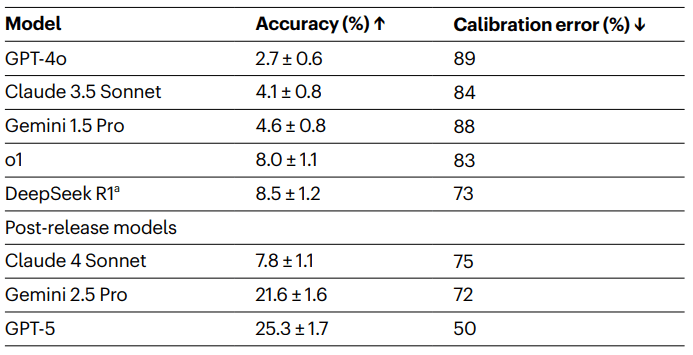
Все модели показали низкую точность на HLE. Отчасти это связано с конструкцией бенчмарка: вопросы, которые текущие модели решают правильно, отфильтровались на этапе создания. Тем не менее точность не равна нулю. За счёт случайности при генерации (инференсе) модели иногда угадывают правильный ответ, а иногда отвечают хуже случайного выбора. Вопросы с множественным выбором решались лучше, чем с точным ответом. Исследователи оставили это как естественную особенность набора, не проводя жёсткой фильтрации на устойчивость к угадыванию (adversarial-фильтрации). Истинная нижняя граница возможностей моделей на этом датасете остаётся открытым вопросом. Небольшие колебания точности вблизи нуля ненадёжны как индикатор прогресса.
Важное наблюдение: модели давали неверные ответы с высокой уверенностью. Для проверки калибровки (соответствия заявленной уверенности реальной точности) исследователи попросили модели указывать уверенность в ответе от 0% до 100%. У хорошо откалиброванной модели заявленная уверенность должна соответствовать фактической точности. Данные показали, что модели систематически переоценивали себя.
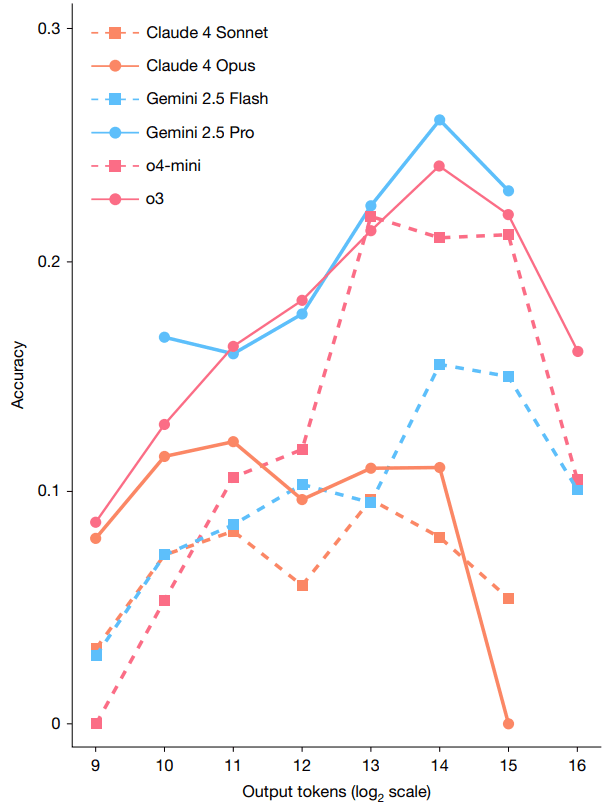
Модели рассуждения тратят дополнительные вычислительные ресурсы на генерацию промежуточных токенов (единиц текста) перед финальным ответом. Исследователи проанализировали, как точность зависит от числа выходных токенов, включая токены рассуждения. При увеличении длины ответа точность росла примерно линейно по логарифмической шкале. Но после 2^14 (16 384) токенов тренд разворачивался: дальнейшее увеличение «размышлений» не улучшало результат. Это означает, что будущие модели должны совершенствовать не только базовую точность, но и вычислительную эффективность.
Цифры
Конкретные результаты, упомянутые авторами: GPT-4o — 2,7%, Claude 3.5 Sonnet — 4,1%, o1 от OpenAI — 8%. Самые мощные на момент тестирования системы, включая Gemini 3.1 Pro и Claude Opus 4.6, достигли 40–50% точности.
Эпилог
HLE — не просто тест на знание фактов. Авторы подчёркивают: наличие знаний не эквивалентно пониманию. Модели, уверенно выдающие неверные ответы, наглядно это демонстрируют. LLM обладают колоссальной базой знаний, но глубокие рассуждения, рассмотрение задачи с нестандартного угла, творческий подход остаются им недоступны. ИИ — полезный инструмент, но замена человеческому мышлению ему пока не под силу.
Подробнее — в докладе и дополнительных материалах к нему.