
Вместе с Claude Opus 4.6 и Sonnet 4.6 мы выпускаем обновлённые версии инструментов web search и web fetch. Теперь Claude может напрямую писать и выполнять код во время веб-поиска — чтобы фильтровать результаты до попадания в контекстное окно. Это повышает точность ответов и экономит токены.
Веб-поиск с динамической фильтрацией
Веб-поиск — одна из самых токеноёмких задач. Агенты с базовыми инструментами поиска отправляют запрос, подтягивают результаты в контекст, загружают полные HTML-файлы с нескольких сайтов и только потом начинают рассуждать. Большая часть загруженного контекста при этом оказывается нерелевантной — это снижает качество ответа.
Чтобы решить проблему, web search и web fetch теперь автоматически пишут и выполняют код для постобработки результатов запроса. Claude динамически фильтрует результаты до загрузки в контекст — оставляет только нужное, остальное отбрасывает.
Мы ранее убедились, что этот подход эффективно работает в других агентных сценариях. Для нативной поддержки в API мы добавили инструменты code execution и programmatic tool calling — программный вызов инструментов из кода. Теперь те же техники применяются к веб-поиску и загрузке страниц.
Оценка качества веб-поиска
Мы замерили качество веб-поиска на Sonnet 4.6 и Opus 4.6 с динамической фильтрацией и без неё, без подключения других инструментов. На двух бенчмарках — BrowseComp и DeepsearchQA — динамическая фильтрация в среднем повысила точность на 11% при сокращении входящих токенов на 24%.
BrowseComp: поиск одного ответа в сети
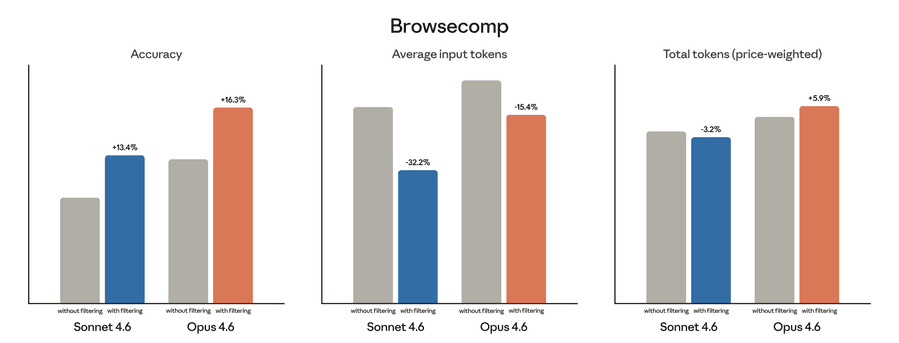
BrowseComp проверяет, может ли агент обойти множество сайтов, чтобы найти конкретную информацию, намеренно скрытую в интернете. Динамическая фильтрация значительно повысила точность: Sonnet 4.6 с 33,3% до 46,6%, Opus 4.6 — с 45,3% до 61,6%.
DeepsearchQA: поиск множества ответов в сети
DeepsearchQA задаёт агентам исследовательские запросы с множеством правильных ответов — все нужно найти через веб-поиск. Бенчмарк проверяет, умеет ли агент системно планировать и выполнять многошаговый поиск без пропусков. Результат измеряется F1-метрикой, которая балансирует точность и полноту — учитывает и корректность найденных ответов, и исчерпывающий поиск.
Динамическая фильтрация повысила F1 Sonnet 4.6 с 52,6% до 59,4%, а Opus 4.6 — с 69,8% до 77,3%.
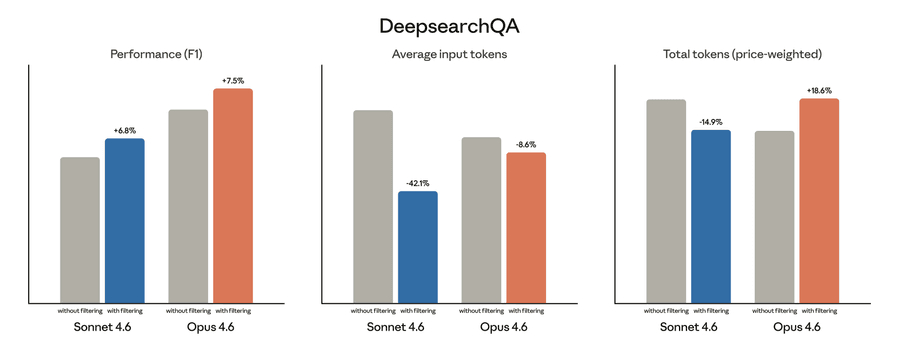
Расход токенов зависит от объёма кода, который модели нужно написать для фильтрации контекста. На обоих бенчмарках стоимость токенов снизилась для Sonnet 4.6, но выросла для Opus 4.6. Чтобы оценить реальные затраты, рекомендуем протестировать инструмент на репрезентативном наборе поисковых запросов, с которыми ваш агент сталкивается в продакшене.
Практика: Quora
Poe от Quora — одна из крупнейших мульти-модельных AI-платформ, где миллионы пользователей получают доступ к более чем 200 моделям через единый интерфейс. Внутренние команды Quora выяснили, что Opus 4.6 с динамической фильтрацией «показал высшую точность на наших внутренних оценках в сравнении с другими флагманскими моделями», — говорит Gareth Jones, руководитель продукта и исследований. «Модель ведёт себя как настоящий исследователь: пишет Python-код, чтобы парсить, фильтровать и перекрёстно проверять результаты, вместо того чтобы рассуждать над сырым HTML в контексте».
Как работает динамическая фильтрация в web search и web fetch
Динамическая фильтрация включена по умолчанию при использовании новых инструментов web search и web fetch с Sonnet 4.6 и Opus 4.6 через Claude API. Для сложных поисковых задач — например, когда нужно прошерстить техническую документацию или проверить цитирования — можно ожидать улучшений, сопоставимых с описанными выше.
Пример вызова через API:
{
"model": "claude-opus-4-6",
"max_tokens": 4096,
"tools": [
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch"
}
],
"messages": [
{
"role": "user",
"content": "Search for the current prices of AAPL and GOOGL, then calculate which has a better P/E ratio."
}
]
}Code execution, memory и другие инструменты теперь в General Availability
Мы также переводим в статус GA (General Availability — общедоступный выпуск) несколько инструментов, которые помогают агентам эффективнее справляться с токеноёмкими задачами:
- Code execution — песочница для выполнения кода во время диалога: фильтрация контекста, анализ данных, вычисления.
- Memory — хранение и извлечение информации между диалогами через постоянное хранилище файлов, чтобы агент сохранял данные без перегрузки контекстного окна.
- Programmatic tool calling — выполнение сложных сценариев с несколькими инструментами в коде с исключением промежуточных результатов из контекстного окна.
- Tool search — динамический поиск инструментов в крупных библиотеках без загрузки всех определений в контекст.
- Tool use examples — примеры вызовов инструментов прямо в их определениях для демонстрации паттернов использования и снижения ошибок в параметрах.
Как начать
Обновлённые web search и web fetch, а также code execution, memory, programmatic tool calling, tool search и tool use examples уже доступны на Claude Platform. Ознакомьтесь с документацией API, чтобы начать работу.