
Команда Baidu Qianfan представила Qianfan-OCR — end-to-end модель (обрабатывающая данные от начала до конца без промежуточных этапов) на 4 млрд параметров. Она объединяет парсинг документов, анализ разметки и понимание контента в единой vision-language архитектуре (работает одновременно с изображениями и текстом). В отличие от традиционных многоступенчатых OCR-пайплайнов, где отдельные модули отвечают за детекцию разметки и распознавание текста, Qianfan-OCR выполняет прямую конвертацию изображений в Markdown. Задачи настраиваются через промпты: извлечение таблиц, вопросно-ответные системы по документам.
https://arxiv.org/pdf/2603.13398
Архитектура и технические характеристики
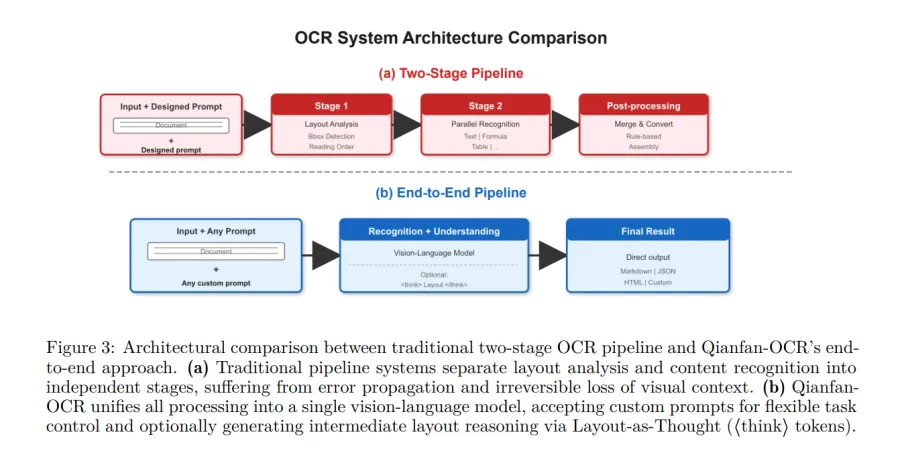
Qianfan-OCR использует мультимодальную архитектуру из фреймворка Qianfan-VL. Система состоит из трёх основных компонентов:
- Vision Encoder (Qianfan-ViT): визуальный энкодер, извлекающий признаки из изображения. Реализует дизайн Any Resolution — разбивает изображения на тайлы (фрагменты) 448 × 448. Поддерживает входы переменного разрешения вплоть до 4K. Генерирует до 4096 визуальных токенов (единиц представления данных в модели) на изображение для сохранения пространственного разрешения мелкого текста и плотных фрагментов.
- Cross-Modal Adapter: лёгкий двухслойный MLP (многослойный перцептрон — базовый тип нейросетевого слоя) с активацией GELU. Проецирует визуальные признаки в пространство эмбеддингов (векторных представлений) языковой модели.
- Language Model Backbone (Qwen3-4B): основная языковая модель на 4,0 млрд параметров с 36 слоями и нативным окном контекста 32K. Использует Grouped-Query Attention (GQA) — оптимизацию механизма внимания, которая сокращает потребление памяти KV cache (кэша промежуточных данных при генерации) в 4 раза.
Механизм Layout-as-Thought
Ключевая особенность модели — Layout-as-Thought, необязательная фаза «размышления», запускаемая токенами Speaker. На этом этапе модель генерирует структурированное представление разметки: bounding box’ы (прямоугольные области, обозначающие положение элементов), типы элементов и порядок чтения. Финальный результат выдаётся после этой фазы.
- Практическая ценность: процесс восстанавливает явные возможности анализа разметки (локализация элементов и классификация их типов), которые обычно теряются в end-to-end подходах.
- Особенности работы: оценка на OmniDocBench v1.5 показывает, что включение фазы размышления даёт стабильный прирост на документах с высокой «энтропией меток разметки» — тех, где есть разнородные элементы: текст, формулы, диаграммы.
- Эффективность: координаты bounding box’ов кодируются специальными токенами (
<COORD_0>—<COORD_999>). Это сокращает длину вывода на этапе размышления примерно на 50% по сравнению с обычными числовыми последовательностями.
Результаты на бенчмарках
Qianfan-OCR сравнивалась как со специализированными OCR-системами, так и с универсальными vision-language моделями (VLM).
Парсинг документов и общий OCR
Модель занимает первое место среди end-to-end моделей на нескольких ключевых бенчмарках:
- OmniDocBench v1.5: 93,12 — обходит DeepSeek-OCR-v2 (91,09) и Gemini-3 Pro (90,33).
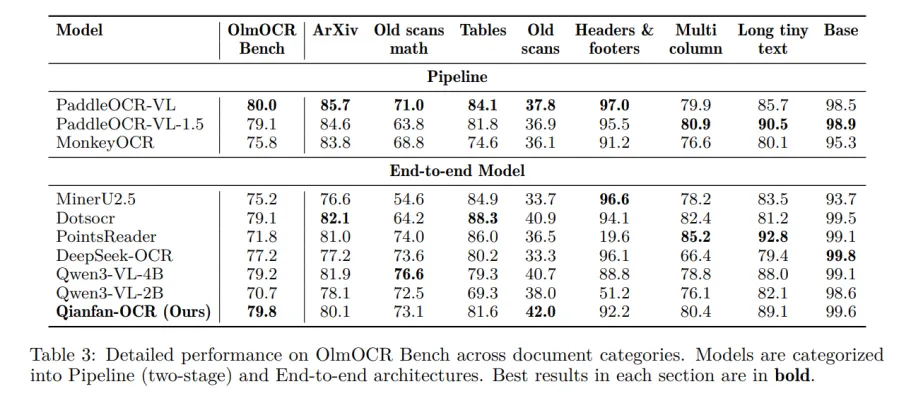
- OlmOCR Bench: 79,8 — лидер в категории end-to-end.
- OCRBench: 880 — первое место среди всех протестированных моделей.
На публичных KIE-бенчмарках (Key Information Extraction — извлечение структурированной информации из документов) Qianfan-OCR набрала высший средний балл (87,9), значительно обойдя модели большего размера.
| Модель | Средний балл (KIE) | OCRBench KIE | Nanonets KIE (F1) |
|---|---|---|---|
| Qianfan-OCR (4B) | 87,9 | 95,0 | 86,5 |
| Qwen3-4B-VL | 83,5 | 89,0 | 83,3 |
| Qwen3-VL-235B-A22B | 84,2 | 94,0 | 83,8 |
| Gemini-3.1-Pro | 79,2 | 96,0 | 76,1 |
Понимание документов
Сравнительное тестирование показало, что двухступенчатые пайплайны OCR+LLM регулярно проваливают задачи, требующие пространственного рассуждения. Например, все протестированные двухступенчатые системы набрали 0,0 на бенчмарке CharXiv. Этап извлечения текста отбрасывает визуальный контекст (соотношения осей, позиции точек данных), необходимый для интерпретации графиков.
https://arxiv.org/pdf/2603.13398
Развёртывание и инференс
Эффективность инференса измерялась в страницах в секунду (PPS) на одной NVIDIA A100.
- Квантование: с квантованием W8A8 (AWQ) — сжатием весов и активаций до 8 бит — модель достигает 1,024 PPS. Это двукратное ускорение относительно базовой W16A16 (16-битные веса и активации) при пренебрежимо малой потере точности.
- Архитектурное преимущество: в отличие от пайплайн-систем, где анализ разметки выполняется на CPU и становится узким местом, Qianfan-OCR полностью GPU-centric (выполняется на GPU). Это устраняет задержки между стадиями и позволяет эффективно обрабатывать большие батчи (пакеты данных).