
LLM-агенты всё чаще работают в постоянных реальных ролях и сталкиваются с непрерывным потоком задач. Ключевое ограничение: агенты не умеют учиться на накопленном опыте. Они вынуждены отбрасывать ценную информацию и повторять прошлые ошибки. Исследователи из Google Cloud AI Research, Йельского университета и UIUC предлагают ReasoningBank — фреймворк памяти. Он дистиллирует (выделяет суть) обобщаемые стратегии рассуждений из успешного и провального опыта самого агента.
Проблема
Современные LLM-агенты решают задачи изолированно: каждый запрос обрабатывается независимо, без учёта предыдущего опыта. Существующие подходы к памяти агентов хранят либо сырые логи действий (trace-based), либо только успешные шаблоны (workflow-based). У обоих подходов два недостатка. Они не выделяют высокоуровневые переносимые паттерны рассуждений. Также они игнорируют уроки из собственных провалов.
ReasoningBank
ReasoningBank извлекает из прошлого опыта структурированные элементы памяти — не сырые логи, а абстрактные принципы и стратегии. Каждый элемент состоит из трёх компонентов:
- Заголовок — краткий идентификатор стратегии
- Описание — одно предложение о сути
- Содержимое — выделенные шаги рассуждений, мотивы решений и операционные инсайты
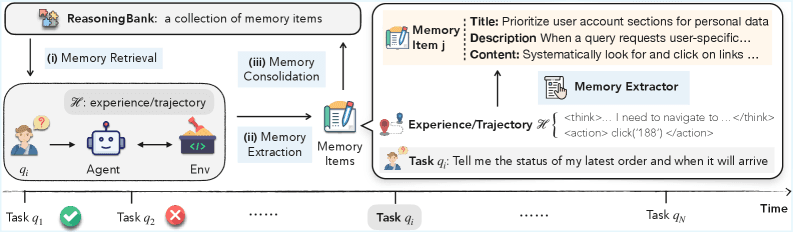
Работа фреймворка строится по замкнутому циклу из трёх этапов:
- Извлечение памяти — после завершения задачи LLM выступает в роли судьи (LLM-as-a-judge). Он классифицирует траекторию как успешную или провальную без доступа к эталонному ответу (ground truth). Из успешных извлекаются валидированные стратегии. Из провальных — контрфактические сигналы и описания ловушек.
- Поиск памяти — при новой задаче агент ищет топ-k релевантных элементов. Поиск идёт через семантическое сравнение векторных представлений (embedding-based similarity search). Найденные элементы внедряются в системный промпт.
- Консолидация — новые элементы добавляются в пул памяти, обеспечивая непрерывную эволюцию.
MaTTS: масштабирование с учётом памяти
Test-time scaling (TTS) — приём повышения качества LLM за счёт дополнительных вычислений на этапе генерации ответа (инференсе). Авторы интегрируют TTS с ReasoningBank в подходе MaTTS (Memory-aware Test-Time Scaling). Он реализован в двух вариантах.
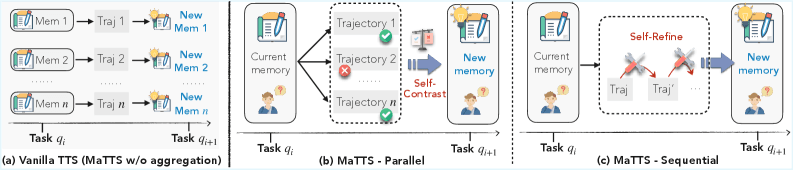
Параллельное масштабирование — генерируется несколько траекторий для одной задачи под управлением памяти. Агент сравнивает их между собой (self-contrast). Это позволяет выделить устойчивые паттерны и отфильтровать случайные решения.
Последовательное масштабирование — агент итеративно уточняет рассуждения внутри одной траектории (self-refinement). Промежуточные заметки служат сигналами для памяти. Они фиксируют попытки, коррекции и инсайты, которых нет в финальном решении.
Ключевая идея: качественная память направляет масштабирование на перспективные пути, а богатый опыт от масштабирования формирует ещё более сильную память — образуется положительная обратная связь.
Результаты
Эксперименты проводились на WebArena, Mind2Web и SWE-Bench-Verified. В качестве базовых моделей (backbone) использовались Gemini-2.5 и Claude-3.7-Sonnet.
ReasoningBank против базовых подходов
Таблица 1: Результаты на WebArena. SR (↑) — успешность, Step (↓) — количество шагов.
| Модели | Shopping (187) | Admin (182) | Gitlab (180) | Reddit (106) | Multi (29) | Overall (684) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | Step | SR | Step | SR | Step | SR | Step | SR | Step | SR | Step | |
| Gemini-2.5-flash | ||||||||||||
| No Memory | 39.0 | 8.2 | 44.5 | 9.5 | 33.9 | 13.3 | 55.7 | 6.7 | 10.3 | 10.0 | 40.5 | 9.7 |
| Synapse | 40.6 | 7.0 | 45.1 | 9.1 | 35.6 | 13.0 | 59.4 | 6.5 | 10.3 | 10.5 | 42.1 | 9.2 |
| AWM | 44.4 | 7.0 | 46.7 | 8.8 | 37.2 | 13.2 | 62.3 | 6.1 | 3.4 | 7.7 | 44.1 | 9.0 |
| ReasoningBank | 49.7 | 6.1 | 51.1 | 8.2 | 40.6 | 12.3 | 67.0 | 5.6 | 13.8 | 8.8 | 48.8 | 8.3 |
| Gemini-2.5-pro | ||||||||||||
| No Memory | 45.5 | 7.6 | 51.1 | 8.7 | 35.0 | 11.6 | 71.7 | 6.0 | 6.9 | 8.8 | 46.7 | 8.8 |
| Synapse | 46.5 | 6.6 | 52.2 | 8.9 | 38.3 | 11.3 | 68.9 | 5.9 | 6.9 | 9.0 | 47.7 | 8.5 |
| AWM | 48.1 | 6.4 | 49.3 | 9.8 | 40.0 | 11.2 | 68.9 | 6.4 | 3.4 | 9.3 | 47.6 | 8.7 |
| ReasoningBank | 51.9 | 6.0 | 56.6 | 7.7 | 44.4 | 9.8 | 80.2 | 5.1 | 13.8 | 8.2 | 53.9 | 7.4 |
| Claude-3.7-sonnet | ||||||||||||
| No Memory | 38.5 | 6.1 | 49.5 | 8.4 | 36.7 | 10.6 | 53.8 | 5.5 | 0.0 | 11.6 | 41.7 | 8.0 |
| Synapse | 39.6 | 5.8 | 50.5 | 8.5 | 38.0 | 10.0 | 53.8 | 6.1 | 0.0 | 11.8 | 42.6 | 7.9 |
| AWM | 39.6 | 7.2 | 47.8 | 9.3 | 34.6 | 10.9 | 52.8 | 7.0 | 0.0 | 12.4 | 40.8 | 8.9 |
| ReasoningBank | 44.9 | 5.6 | 53.3 | 7.6 | 41.1 | 9.5 | 57.5 | 5.2 | 3.4 | 10.5 | 46.3 | 7.3 |
ReasoningBank стабильно превосходит базовые модели на всех датасетах и с разными базовыми моделями. На WebArena общий прирост успешности составляет +8.3, +7.2 и +4.6 для трёх разных LLM по сравнению с агентами без памяти.
Таблица 2: Результаты на SWE-Bench-Verified.
| Методы | Resolve Rate | Step |
|---|---|---|
| Gemini-2.5-flash | ||
| No Memory | 34.2 | 30.3 |
| Synapse | 35.4 | 30.7 |
| ReasoningBank | 38.8 | 27.5 |
| Gemini-2.5-pro | ||
| No Memory | 54.0 | 21.1 |
| Synapse | 53.4 | 21.0 |
| ReasoningBank | 57.4 | 19.8 |
Таблица 3: Результаты на Mind2Web для cross-task, cross-website и cross-domain обобщения. EA (↑) — element accuracy, AF₁ (↑) — action F₁, SSR (↑) — step success rate, SR (↑) — task-level success rate.
| Модели | Cross-Task (252) | Cross-Website (177) | Cross-Domain (912) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EA | AF₁ | SSR | SR | EA | AF₁ | SSR | SR | EA | AF₁ | SSR | SR | |
| Gemini-2.5-flash | ||||||||||||
| No Memory | 46.0 | 59.1 | 40.3 | 3.3 | 39.8 | 45.1 | 31.7 | 1.7 | 35.8 | 37.9 | 31.9 | 1.0 |
| Synapse | 47.0 | 59.5 | 41.2 | 3.5 | 40.3 | 46.0 | 32.1 | 1.9 | 36.3 | 38.5 | 32.4 | 1.1 |
| AWM | 46.3 | 56.1 | 41.0 | 3.5 | 39.1 | 42.2 | 31.7 | 2.1 | 33.3 | 36.5 | 30.1 | 0.7 |
| ReasoningBank | 52.1 | 60.4 | 44.9 | 4.8 | 44.3 | 52.6 | 33.9 | 2.3 | 40.6 | 41.3 | 36.6 | 1.6 |
| Gemini-2.5-pro | ||||||||||||
| No Memory | 49.3 | 60.2 | 44.4 | 3.5 | 41.2 | 49.8 | 34.8 | 3.4 | 37.9 | 37.7 | 35.0 | 1.4 |
| Synapse | 50.1 | 61.0 | 44.7 | 3.6 | 41.8 | 51.2 | 35.0 | 3.2 | 38.5 | 39.8 | 35.6 | 1.5 |
| AWM | 48.6 | 61.2 | 44.4 | 3.7 | 41.9 | 47.9 | 34.8 | 2.3 | 37.3 | 38.1 | 34.4 | 1.2 |
| ReasoningBank | 53.6 | 62.7 | 45.6 | 5.1 | 46.1 | 54.8 | 36.9 | 3.8 | 42.8 | 45.2 | 38.1 | 1.7 |
Особенно заметен прирост на подмножестве WebArena-Multi, требующем переноса памяти между несколькими сайтами: ReasoningBank даёт средний прирост +4.6 по SR, тогда как AWM в этом сценарии деградирует.
Эффективность
Помимо роста успешности, ReasoningBank сокращает количество шагов взаимодействия. На WebArena среднее снижение — до 1.4 шага по сравнению с «No Memory» и 1.6 шага по сравнению с другими механизмами памяти. На SWE-Bench-Verified экономия составляет 2.8 и 1.3 шага соответственно.
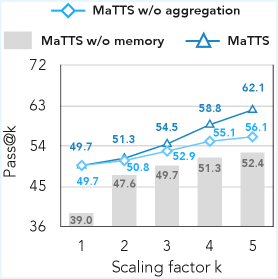
Результаты MaTTS
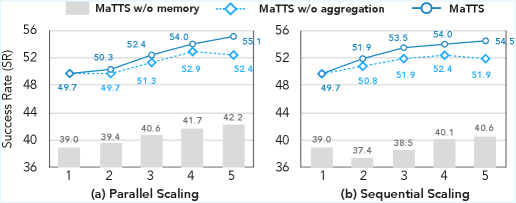
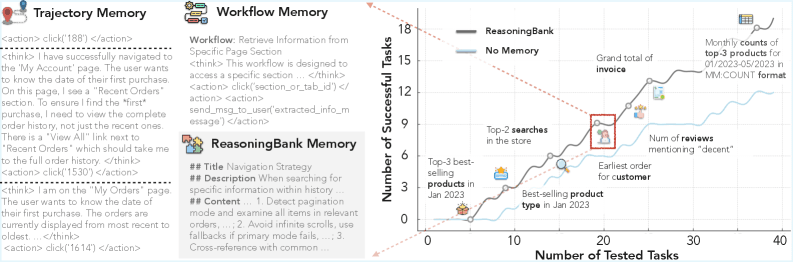
Эксперименты с Gemini-2.5-flash на WebArena-Shopping показывают:
- Параллельное масштабирование: рост с 49.7 (k=1) до 55.1 (k=5) с MaTTS против 39.0–42.2 без памяти.
- Последовательное масштабирование: рост с 49.7 до 54.5 с MaTTS против 37.4–40.6 без памяти.
- MaTTS стабильно превосходит базовое масштабирование без улучшений (vanilla TTS). При k=5 параллельное масштабирование даёт 55.1 против 52.4. Последовательное — 54.5 против 51.9.
- При сильной памяти (ReasoningBank) последовательное масштабирование даёт больший прирост при малых k, но быстро насыщается. Параллельное продолжает расти на больших k.
Синергия памяти и масштабирования
Двунаправленное взаимодействие между памятью и масштабированием:
- Лучшая память → сильнее масштабирование: без памяти лучший из N вариантов (BoN, Best-of-N) растёт с 39.0 до 40.6. С Synapse — до 42.8. С AWM — до 45.5. С ReasoningBank — до 52.4.
- Масштабирование → лучшая память: у слабых механизмов памяти масштабирование снижает успешность с первой попытки (Pass@1). Для Synapse показатель падает с 40.6 до 40.1, для AWM — с 44.4 до 41.2. Дополнительные траектории вносят шум. ReasoningBank — единственный метод, где Pass@1 растёт (с 49.7 до 50.8).
Анализ
Эмерджентное поведение

Стратегии в ReasoningBank не статичны. Они эволюционируют во времени, напоминая динамику обучения с подкреплением (RL). Эволюция одного элемента памяти проходит через четыре стадии:
- Процедурные стратегии — агент следует прямолинейным правилам (например, «найти навигационные ссылки»)
- Адаптивная саморефлексия — перепроверка идентификаторов для снижения ошибок
- Адаптивные проверки — системное использование поиска и фильтров для полноты результатов
- Композиционные стратегии — перекрёстная проверка требований задачи и переоценка вариантов
Роль провальных траекторий
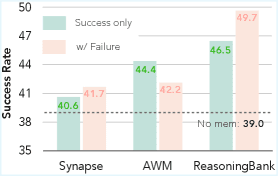
Базовые решения (baselines) вроде Synapse и AWM строят память только из успешных траекторий. Они не умеют извлекать пользу из провалов. При добавлении провалов Synapse растёт минимально (40.6 → 41.7), а AWM деградирует (44.4 → 42.2). ReasoningBank достигает 46.5 только на успешных траекториях и 49.7 с добавлением провалов. Провалы превращаются в конструктивные сигналы, а не в шум.
Эффективность: успешные vs провальные случаи
Разделение анализа на успешные и провальные тестовые случаи даёт интересный результат. ReasoningBank сокращает шаги прежде всего на успешных случаях — до 2.1 шага (26.9% относительного снижения). На провальных случаях экономия составляет 0.2–1.4 шага. Это означает, что память помогает агенту находить решения за меньшее число взаимодействий, а не просто обрывать неудачные попытки.
Детали реализации
Извлечение памяти
Для извлечения элементов используется LLM с температурой 1.0. Это та же базовая модель, что и у агента. Из каждой траектории извлекается максимум 3 элемента в формате Markdown с полями title, description, content. Для классификации успешности применяется LLM-as-a-judge с температурой 0.0.


Поиск и консолидация
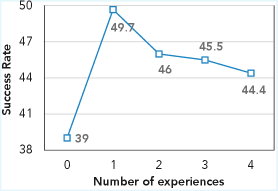
Запросы преобразуются в векторы (эмбеддятся) через gemini-embedding-001. Поиск идёт по косинусному сходству (cosine similarity). По умолчанию k=1 — дополнительные опыты показывают, что увеличение количества извлекаемых элементов снижает результат (49.7 при k=1, 46.0 при k=2, 44.4 при k=4). Консолидация минимальна. Новые элементы просто добавляются в пул без удаления старых (pruning). Это сделано, чтобы изолировать эффект качества контента.
Промпты для MaTTS

В параллельном режиме модель сравнивает несколько траекторий одной задачи, выявляя паттерны успеха и ошибки. В последовательном — итеративно перепроверяет траекторию без внешнего арбитра.
Примеры из практики
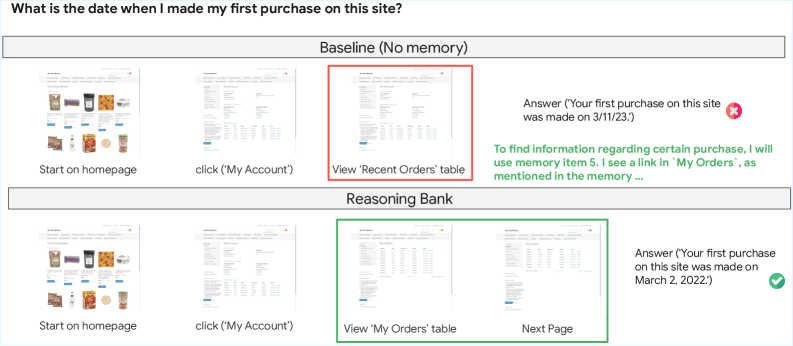
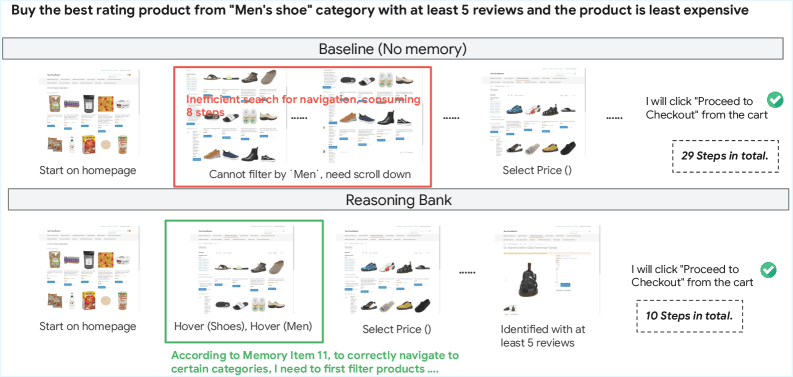
Ограничения и перспективы
Фокус на контенте памяти. Работа концентрируется на том, что хранить и переиспользовать. Архитектура памяти (например, эпизодическая или иерархическая) не рассматривается. Исследование их комбинации — перспективное направление.
Простота поиска и консолидации. Применён намеренно простой поиск по векторам без адаптивной маршрутизации. Консолидация минимальна. Это сделано для изоляции эффекта качества контента. Более сложные стратегии совместимы с фреймворком.
Зависимость от LLM-as-a-judge. Автоматическая разметка успешности может вносить шум при неоднозначных задачах. Будущие работы могут усилить верификацию через ансамблевые оценки или привлечение человека к проверке (human-in-the-loop).
Среди перспективных направлений — композиционная память (комбинирование элементов в высокоуровневые макросы) и послойные архитектуры памяти (эпизодическая для контекста задачи, рабочая для сессии, долгосрочная с политиками забывания). Философия ReasoningBank совместима со всеми этими подходами.
Итог
ReasoningBank показывает, что память на основе выделенных стратегий рассуждений создаёт новое измерение масштабирования для AI-агентов. Причём стратегии извлекаются из обоих исходов — как из успехов, так и из провалов. В связке с MaTTS это формирует самоподкрепляющийся цикл: память направляет масштабирование на перспективные пути, а масштабирование обогащает память контрастными сигналами. Результат — агенты, которые не просто решают задачи, а непрерывно эволюционируют, развиваясь от простых процедурных действий до композиционных стратегий рассуждений.