
Большие языковые модели (LLM) переходят от формата диалога к автономным агентам. Такие агенты способны выполнять сложные профессиональные workflows. Однако их реальное внедрение в корпоративной среде упирается в нехватку бенчмарков, учитывающих специфику таких задач. К ним относятся долгосрочное планирование, постоянные изменения состояния и строгие протоколы доступа.
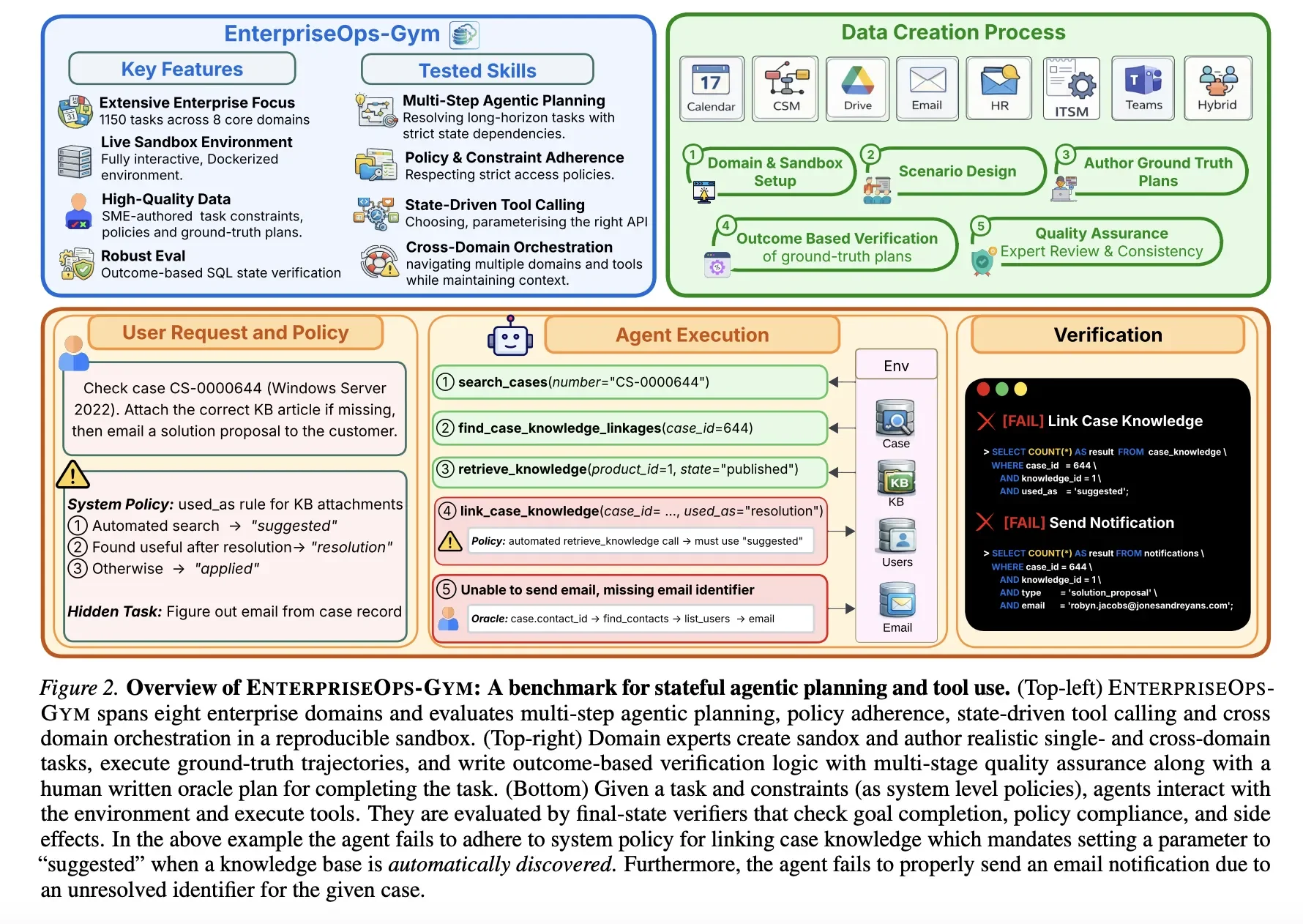
Чтобы закрыть этот пробел, исследователи ServiceNow Research, Mila и Университета Монреаля создали EnterpriseOps-Gym. Это высоконадёжная изолированная тестовая среда (sandbox) для оценки agentic-планирования — планирования действий автономными ИИ-агентами — в реалистичных корпоративных сценариях.
 Источник: arxiv.org/pdf/2603.13594
Источник: arxiv.org/pdf/2603.13594
Среда оценки
EnterpriseOps-Gym развёрнут в контейнеризированной Docker-среде. Она симулирует восемь критически важных для бизнеса доменов:
- Операционные домены: Customer Service Management (CSM), Human Resources (HR) и IT Service Management (ITSM).
- Домены совместной работы: Email, Calendar, Teams и Drive.
- Гибридный домен: кросс-доменные задачи, требующие координированного выполнения в нескольких системах.
Бенчмарк включает 164 реляционные таблицы БД и 512 функциональных инструментов. Средний показатель внешних ключей (foreign key) равен 1.7. Это означает высокую реляционную плотность: агентам приходится учитывать сложные межтабличные зависимости для сохранения целостности данных (referential integrity). В бенчмарке 1 150 экспертно составленных задач, средняя длина траектории выполнения — 9 шагов, максимум — 34.
Результаты: явный разрыв в возможностях
Исследователи протестировали 14 фронтовых моделей по метрике pass@1 — задача считается выполненной, только если с первой попытки проходят все SQL-верификаторы по результатам.
| Модель | Средний success rate (%) | Стоимость за задачу (USD) |
|---|---|---|
| Claude Opus 4.5 | 37.4% | $0.36 |
| Gemini-3-Flash | 31.9% | $0.03 |
| GPT-5.2 (High) | 31.8% | Не указано |
| Claude Sonnet 4.5 | 30.9% | $0.26 |
| GPT-5 | 29.8% | $0.16 |
| DeepSeek-V3.2 (High) | 24.5% | $0.014 |
| GPT-OSS-120B (High) | 23.7% | $0.015 |
Даже лучшие из SOTA-моделей (лучших на сегодняшний день) не достигают 40% надёжности в таких структурированных средах. Результаты сильно зависят от домена. Лучше всего модели справляются с инструментами совместной работы (Email, Teams), но существенно проседают в доменах с жёсткими политиками — ITSM (28.5%) и Hybrid (30.7%).
Планирование против выполнения
Ключевой вывод исследования: стратегическое планирование, а не вызов инструментов, — основное узкое место производительности.
Исследователи провели «Oracle»-эксперименты, снабдив агентов планами, написанными людьми. Это дало прирост 14–35 процентных пунктов во всех моделях. Примечательно, что небольшие модели вроде Qwen3-4B при внешнем стратегическом рассуждении становились конкурентоспособны с моделями на порядок крупнее. При этом добавление отвлекающих («дистракторных») инструментов для симуляции ошибок поиска почти не повлияло на результат. Это подтверждает: поиск инструментов не является ограничивающим фактором.
Типичные ошибки и вопросы безопасности
Качественный анализ выявил четыре повторяющихся паттерна сбоев:
- Пропуск проверки предусловий: создание объектов без запроса необходимых предварительных данных, что приводит к записям без связей с другими таблицами.
- Каскадное распространение состояния: отсутствие необходимых последующих (follow-up) действий, требуемых политиками системы после изменения состояния.
- Некорректное разрешение ID: передача непроверенных или угаданных идентификаторов в вызовы инструментов.
- Галлюцинация досрочного завершения: объявление задачи выполненной до того, как пройдены все обязательные шаги.
Кроме того, агенты плохо справляются с безопасным отказом — корректным отказом от выполнения недопустимых запросов. Бенчмарк содержит 30 невыполнимых задач (нарушение правил доступа, работа с неактивными пользователями и т.д.). Лучшая модель, GPT-5.2 (Low), корректно отказалась выполнить такие задачи лишь в 53.9% случаев. В продовой среде невыполнение несанкционированного или невыполнимого запроса грозит повреждением БД и уязвимостями.
Оркестрация и мультиагентные системы (MAS)
Исследователи проверили, способны ли более сложные архитектуры агентов закрыть разрыв в производительности. Схема Planner+Executor (одна модель планирует, другая выполняет) дала скромный прирост. Однако более сложные декомпозиционные архитектуры (разбивающие задачу на части) чаще снижали результаты. В доменах CSM и HR задачи имеют жёсткие последовательные зависимости по состоянию. Разбиение их на подзадачи для отдельных агентов разрушает необходимый контекст и приводит к результатам хуже, чем простые ReAct-циклы (циклы «размышление-действие»).
Экономика: Pareto-фронтир
Для практического внедрения бенчмарк даёт чёткую картину компромисса между стоимостью и качеством (Pareto-фронтир — граница оптимальных соотношений, где улучшение качества требует непропорционального роста затрат):
- Gemini-3-Flash — лучший практический выбор среди закрытых моделей: 31.9% при стоимости на 90% ниже, чем у GPT-5 или Claude Sonnet 4.5.
- DeepSeek-V3.2 (High) и GPT-OSS-120B (High) — лидеры среди open-source: примерно 24% при ~$0.015 за задачу.
- Claude Opus 4.5 — эталон абсолютной надёжности (37.4%), но при максимальной стоимости в $0.36 за задачу.
Главные выводы
- Масштаб и сложность бенчмарка: EnterpriseOps-Gym предоставляет высоконадёжную среду оценки с 164 реляционными таблицами и 512 инструментами по восьми корпоративным доменам.
- Значительный разрыв в производительности: текущие фронтовые модели ещё не готовы к автономному деплою — лучшая из них, Claude Opus 4.5, показывает лишь 37.4% success rate.
- Планирование как главное узкое место: стратегическое рассуждение ограничивает результативность, а не выполнение инструментов; человеческие планы дают прирост 14–35 п.п.
- Неудовлетворительный безопасный отказ: модели плохо распознают невыполнимые запросы — лучшая отказывается корректно лишь в 53.9% случаев.
- Ограничения thinking budget: увеличение вычислений в момент выполнения запроса (test-time compute) даёт прирост в отдельных доменах, но в других результат выходит на плато. Больше «thinking»-токенов не компенсирует пробелы в понимании политик и доменных знаниях.