
Мультимодальные большие языковые модели (MLLM) существенно продвинули визуальное понимание, но мелкая мимика по-прежнему остаётся слабым местом. Главная проблема — неэффективность токенов. Существующие визуальные языковые модели (V-LLM) обрабатывают каждый кадр как набор изображений. Это дорого и заставляет даунсэмплить видео — снижать разрешение или частоту кадров. Микровыражения — приподнятая бровь, подёргивание губ, лёгкая усмешка — при этом просто исчезают.
Вторая проблема — дисбаланс эмоций. Большие модели обучаются на «диких» видео (YouTube, TikTok, VoxCeleb), где преобладают нейтральные фронтальные говорящие головы. Высокоинтенсивные или нетипичные выражения (надутые губы, нахмуренность, смех, усмешка) встречаются редко.
Исследователи из University of Rochester, University of Tokyo, University of Michigan и Voxel51 предлагают решение — TDMM-LM, фреймворк, который полностью обходится без изображений. Он работает исключительно с геометрическими токенами.

Open3DFaceVid: 80 часов синтетической мимики
Чтобы закрыть пробел в данных, авторы создали Open3DFaceVid — масштабируемый синтетический пайплайн. Несколько T2V-моделей генерируют лица по заранее спроектированным промптам, а затем из каждого видео извлекаются 3DMM-параметры — числовые параметры, описывающие форму лица, выражение и поворот головы.
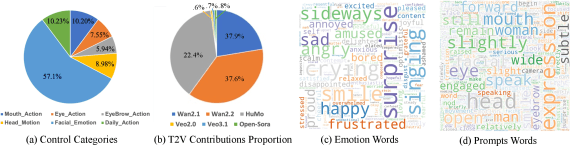
Конструкция промптов делится на две части — внешний вид лица и динамику видео. В части лица авторы варьируют тип эмоции и её интенсивность, добавляя микровыражения: моргание, надувание губ и прочие facial actions. В части видео задают шаблонные ограничения на движение камеры («Кадр остаётся стабильным, голова и плечи по центру»), чтобы минимизировать кинематографическую дрожь. Итоговые шаблоны дорабатывались через ChatGPT-4.1 для естественности.
Синтез запускался на нескольких бэкбонах — Wan-2.1/2.2, Open-Sora, HuMo, Veos — чтобы не переобучиться под специфику одного генератора. Для каждого бэкбона атрибутивная часть промпта стандартизировалась, а видео-специфичные clauses адаптировались под предпочтения модели.
Оценка геометрии проводилась через 3D Morphable Model (3DMM) — конкретно FLAME-модель. Она позволяет получить параметры идентичности лица, выражения и поворота головы (yaw/roll/pitch).

Итого: 81 час видео, 57,2K клипов по 4–6 секунд, 25 FPS, разрешение 618×360. Синтез занял ~400 GPU-часов на 32 H200. Ещё ~10K «диких» клипов из YouTube были дополнительно размечены через Gemini.
Выравнивание языка и движений
На базе Open3DFaceVid авторы строят общее пространство между 3D-движением лица (3DMM) и естественным языком. Пайплайн содержит три компонента.
Geometry VQ-VAE
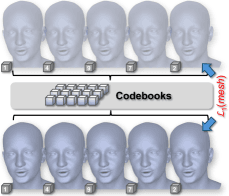
Вместо дискретизации самих 3DMM-параметров (где похожие выражения могут попадать в разные коэффициенты) авторы работают напрямую с восстановленной геометрией. Здесь используется VQ-VAE — автоэнкодер с векторным квантованием, который сжимает данные в набор дискретных кодов. Визуально похожие выражения получают согласованные токены. Это устраняет many-to-one-амбигуность — ситуацию, когда разным входным данным соответствует один и тот же выходной код.
Motion2Language
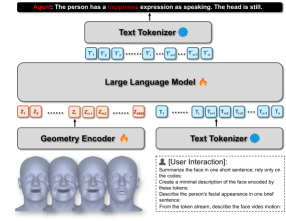
Дискретные геометрические токены подаются в LLM как символьные наблюдения — без изображений. Модель выдаёт свободные описания эмоций, интенсивности, микровыражений и динамики головы. Каждая аннотация расширяется несколькими парафразами от вспомогательной LLM для улучшения лингвистического покрытия.
Language2Motion
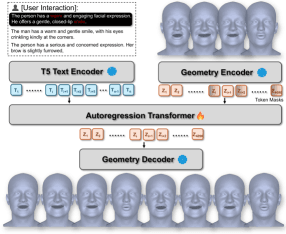
Ключевое отличие от стандартных text-to-motion пайплайнов — вместо сжатия промпта в единое векторное представление (embedding) авторы используют word-level language prefix. Предобученные эмбеддинги LLM инжектируются в авторегрессионный декодер движения лица на уровне отдельных слов. Это позволяет отдельным словам управлять локальными движениями мышц.
Эксперименты
Таблица 1. Количественная оценка Motion2Language. Средние оценки корректности 1–5 от GPT-4 и людей для эмоции (Cor_E, USER_E), движения (Cor_M, USER_M) и интенсивности (Cor_I). Модель на геометрических токенах стабильно превосходит HumanOmni и Gemini-2.5 VLM.
Таблица 2. Оценка Motion2Language на естественных изображениях. Та же метрика корректности, но вместо геометрических входов — натуральные facial images для адаптации к VLM.
Бейзлайны
Motion2Language: HumanOmni (human-centric VLM, работает в pixel space) и Gemini VLM (унифицированный сэмплинг кадров + инструктивный промпт).
Language2Motion: T2M-X (трансформерная text-to-motion модель с дискретными токенами, адаптированная под лицевую ветвь) и T2M-GPT (GPT-стиль генерации на дискретных motion-кодах, обученный на датасете авторов).
Motion2Language: результаты

Метрики: корректность эмоции (Cor_E), движения (Cor_M) и интенсивности (Cor_I) через GPT-4 как автоматического судью на 2K тестовых клипах, плюс человеческие оценки (USER_E, USER_M) на 300 сэмплах.
HumanOmni и Gemini-2.5 Pro, обученные преимущественно на естественных изображениях, плохо интерпретируют временную динамику мимики — их оценки корректности близки к 1. Авторская модель стабильно восстанавливает семантику из 3DMM-токенов. При этом каждый кадр кодируется одним геометрическим токеном вместо 300–500 визуальных.
На естественных изображениях Gemini показывает лидирующие результаты, но важно: метод авторов использует на порядок меньше входных токенов.
Language2Motion: результаты
Таблица 3. Количественная оценка Language2Motion. Сравнение с T2M-X и T2M-GPT по метрикам параметрического пространства (L_2/FD/Tok) и языковым метрикам (Cor_E/USER). L_2/FD оценивают фиделити выражения/позы, Tok — точность на уровне токенов.
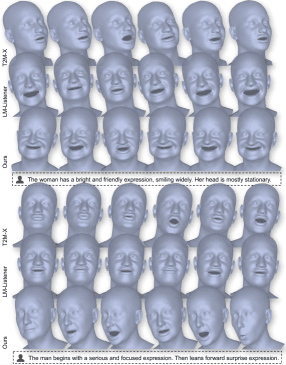
Метрики делились на две группы. Геометрические: L_2-расстояние на выражении и позе, Fréchet Distance (FD) между распределениями признаков сгенерированных и ground-truth последовательностей, точность предсказания токенов (Tok). Языковые: корректность выражения (Cor_E) через обученную Motion2Language модель как внешнего семантического оценщика, и человеческие оценки (USER) на 300 сэмплах.
Метод авторов стабильно лидирует по всем метрикам. T2M-GPT показывает приемлемые результаты благодаря авторегрессионной архитектуре, но уступает по семантическим метрикам. Это подчёркивает преимущество conditioning на мощный LLM-бэкбон. Модель чувствительно реагирует на нюансированные инструкции (переход от «сосредоточенного» к «удивлённому») и лучше передаёт выразительную аффективность («радостный»).
Абляции по датасету
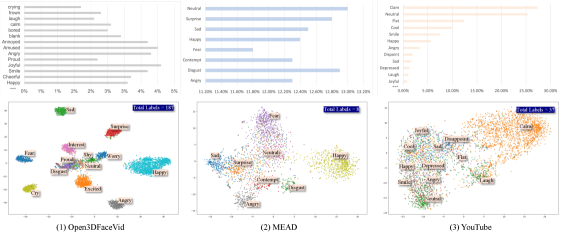
Open3DFaceVid сравнивался с MEAD (студийная съёмка, one-hot метки эмоций — код вида [0,0,1,0,…], где единица стоит только на позиции нужного класса, конвертированные в текст) и YouTube-выборкой с автоматической аннотацией через Gemini.
t-SNE-визуализации (метод снижения размерности для визуального анализа данных, рис. 9) отчётливо показывают: Open3DFaceVid формирует чёткие сбалансированные кластеры по 187 меткам. MEAD с восемью грубыми метками даёт плотные, малоинформативные кластеры. YouTube-данные даже после Gemini-аннотации сильно смещены к нейтральным выражениям с существенным перекрытием.
Таблица 4. Абляция по обучающему корпусу для Motion2Language. Идентичные архитектуры обучены на MEAD, YouTube (Gemini-аннотации) и Open3DFaceVid.
Таблица 5. Абляция по обучающему корпусу для Language2Motion. Обучение на Open3DFaceVid даёт лучший баланс между геометрическим фиделити и text–motion-выравниванием.


При обучении на Open3DFaceVid обе задачи выигрывают. Motion2Language получает более богатую семантику, а Language2Motion — более чистую артикуляцию выражений (например, «надутые губы» на рис. 10). Несмотря на то что MEAD иногда показывает меньшие расстояния в пространстве признаков из-за более простого набора меток, модели на Open3DFaceVid набирают самые высокие USER-оценки.
Масштабирование и контроль
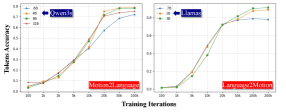
Для Motion2Language производительность насыщается около 4B–8B параметров. Language2Motion выигрывает от масштаба сильнее — большие модели дают более высокую точность генерации токенов.
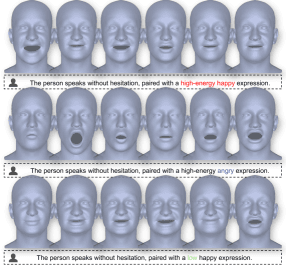
Замена всего одного слова в промпте позволяет регулировать интенсивность стиля («высокоэнергичный» → «тихий») или сменить саму эмоциональную категорию («счастливый» → «злой»). Это подтверждает нюансированное языковое понимание модели и способность переводить мелкозернистые промпты в контролируемую мимику.
Итог
TDMM-LM — первое исследование, которое формулирует моделирование лицевых параметров как языковую задачу. Авторы показывают, что низкомерные геометрические сигналы (3DMM) при правильной токенизации сохраняют тонкую временную вариацию и избавляют от избыточных визуальных токенов. Датасет Open3DFaceVid (~80 часов, 57K клипов, 187 эмоциональных категорий) и двунаправленный фреймворк (Motion2Language + Language2Motion) закладывают фундамент для будущей работы над пониманием и анимацией 3D-мимики.
Ключевые вклады:
- Open3DFaceVid — крупнейший на сегодняшний день корпус пар текст–лицо с разнообразными эмоциями, персонами и вариациями интенсивности.
- Motion2Language — расширение LLM на интерпретацию 3D-движения лица, выдающее компактные описания эмоций, микровыражений и движений головы.
- Language2Motion — генерация 3D-движения лица из текста через conditioning авторегрессионного декодера на уровне отдельных слов, обеспечивающая мелкозернистый контроль.