
Как изменился ландшафт open source AI за прошедший год в сфере конкуренции, географии, технических трендов и зарождающихся сообществ. Мы анализируем активность на Hugging Face по множеству метрик, чтобы дать комплексную картину экосистемы.
Эта статья продолжает ранее проведенный анализ середины 2025 года, посвященный тому, что создает сообщество Hugging Face. Также рекомендуем ознакомиться с другими взглядами на open source-экосистему от Data Provenance Initiative, Interconnects, OpenRouter и a16z, а также MIT и Linux Foundation. Поскольку экосистема Hugging Face распределена, в анализе сочетаются данные платформы и работы членов сообщества (каждый источник отмечен соответственно).
Активность в экосистеме open source AI стремительно растет: число пользователей, репозиториев моделей и датасетов почти удвоилось. В 2025 году Hugging Face вырос до 11 миллионов пользователей, более 2 миллионов публичных моделей и свыше 500 тысяч публичных датасетов. Этот рост означает не просто повышение интереса к open source — он отражает сдвиг к активному участию. Пользователи все чаще создают производные артефакты — fine-tuned модели (доработанные под конкретную задачу), адаптеры, бенчмарки и приложения, — а не просто потребляют готовые предобученные системы.
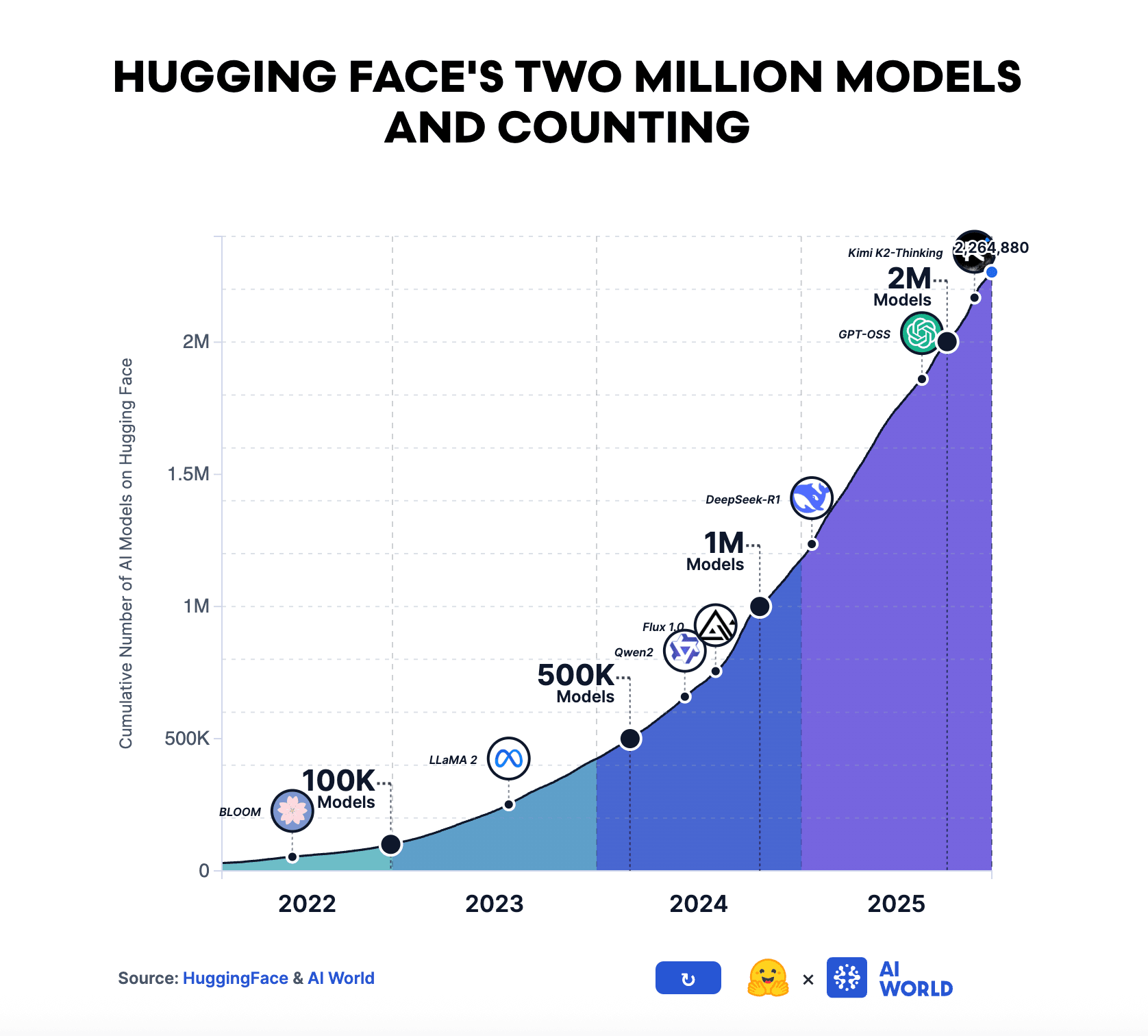
Данные от Hugging Face | Два миллиона моделей Hugging Face и счет продолжается: График и статья от AI World
Экосистема остается высококонцентрированной. Примерно половина моделей на Hugging Face имеет менее 200 загрузок, а топ-200 самых загруженных моделей (всего 0,01% от общего числа) формируют 49,6% всех загрузок.
Вокруг конкретных доменов, языков или проблемных областей формируются специализированные сообщества. Часто они демонстрируют устойчивый интерес и повторное использование артефактов, даже если общее число загрузок невелико. Open source AI лучше понимать не как единый однородный рынок, а как набор пересекающихся субэкосистем.
Open Source в конкуренции
Все больше компаний — как крупных, так и мелких — строят свои решения на базе open source. Теперь более 30% из списка Fortune 500 имеют верифицированные аккаунты на Hugging Face. Стартапы часто используют open-модели как базовые компоненты: Thinking Machines построила опции своей модели Tinker исключительно на open-весах (открытых наборах обученных параметров модели), а популярные IDE, такие как VSCode и Cursor, поддерживают как open, так и закрытые модели. Крупные американские компании, например Airbnb, усиливают взаимодействие с open-экосистемой, а Hugging Face зафиксировал рост числа обновлений корпоративных подписок у традиционных компаний на протяжении 2025 года.
Big Tech компании регулярно создают новые репозитории на Hugging Face Hub. При визуальном сравнении заметен сильный рост числа репозиториев, отражающий инвестиции с течением времени. Лидером по вкладу стала NVIDIA.
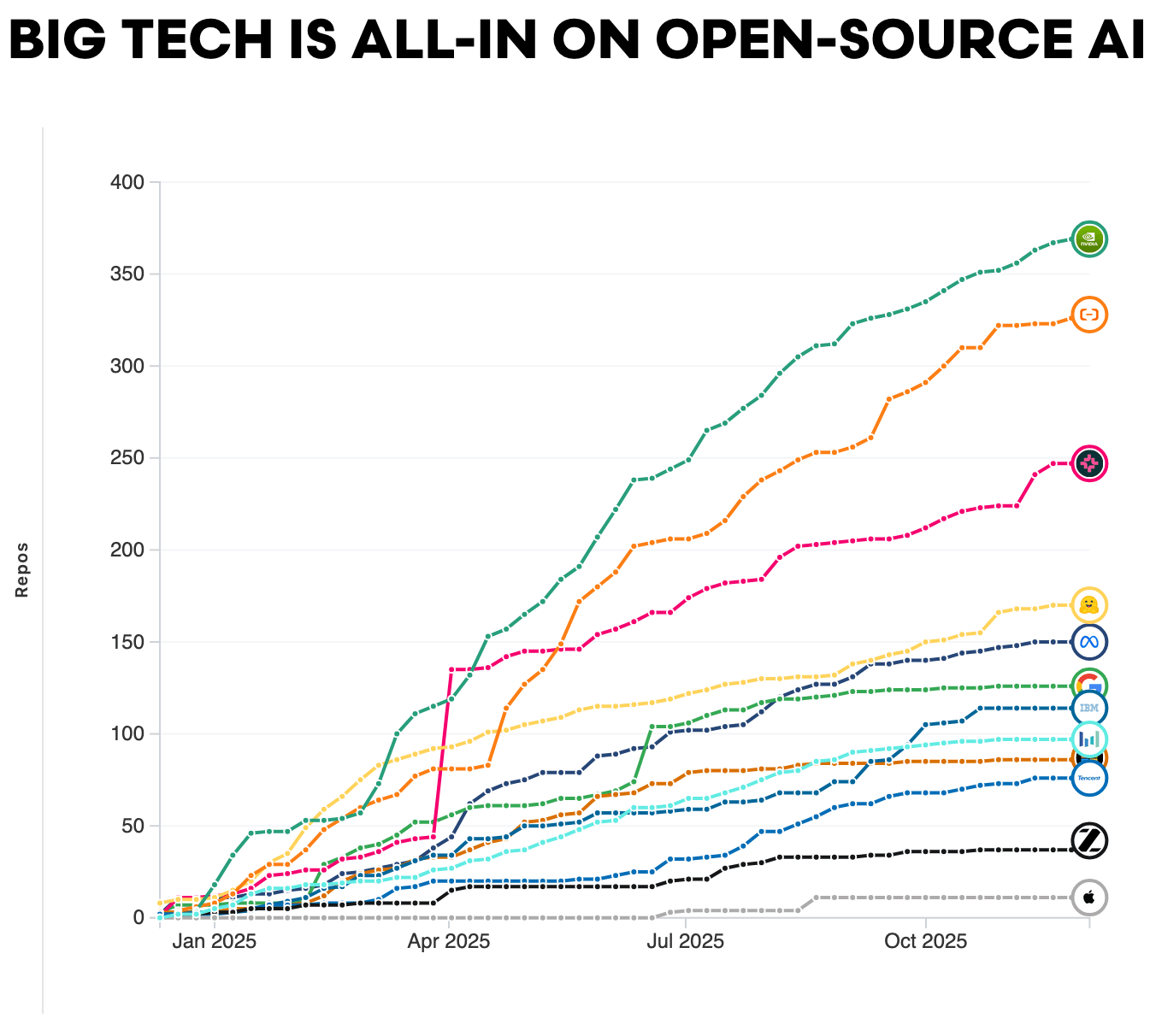
Данные от Hugging Face | Big Tech всецело поддерживает Open Source AI: График и статья от AI World
Исследования open source ПО в целом показывают, что даунстрим-ценность (польза для продуктов и сервисов, построенных поверх базовых моделей) многократно превышает затраты на создание открытых артефактов. Подобная динамика формируется и в AI: open-модели переиспользуются, адаптируются и специализируются в тысячах даунстрим-приложений. Организации, полагающиеся исключительно на закрытые системы, часто несут большие затраты и сталкиваются с меньшей гибкостью при развертывании и кастомизации.
География Open Source
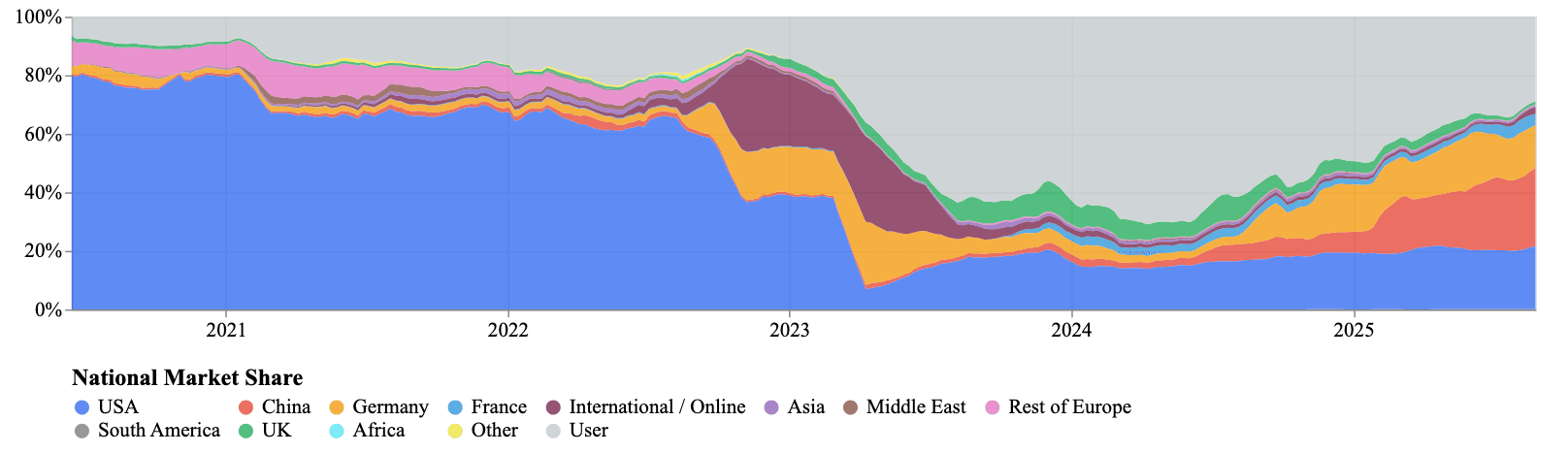
Статистика загрузок за последние четыре года показывает явных лидеров по популярности моделей. Исторически основными контрибьюторами были США и Китай, а Великобритания, Германия и Франция занимали вторые позиции. Модели, разработанные индивидуальными пользователями или распределенными организациями без четкой географической привязки, обеспечивают около половины всех загрузок на платформе.
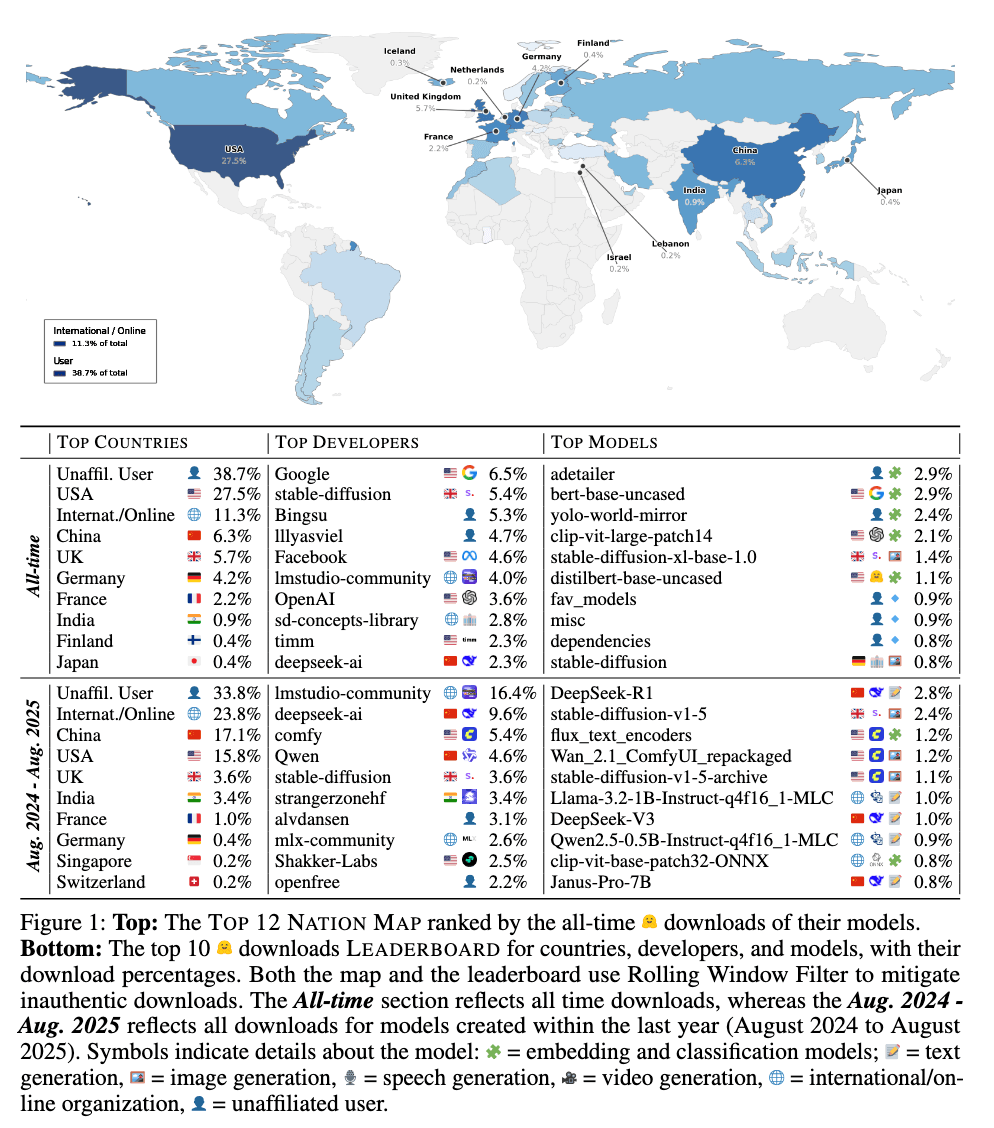
Данные от Hugging Face | График и исследование от Longpre et al. “Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem”
Географический состав open source-экосистемы фундаментально изменился. Данные Hugging Face показывают, что Китай обогнал США по ежемесячным и общим загрузкам. За прошедший год китайские модели быстро заняли крупнейшую долю — 41% от всех загрузок.
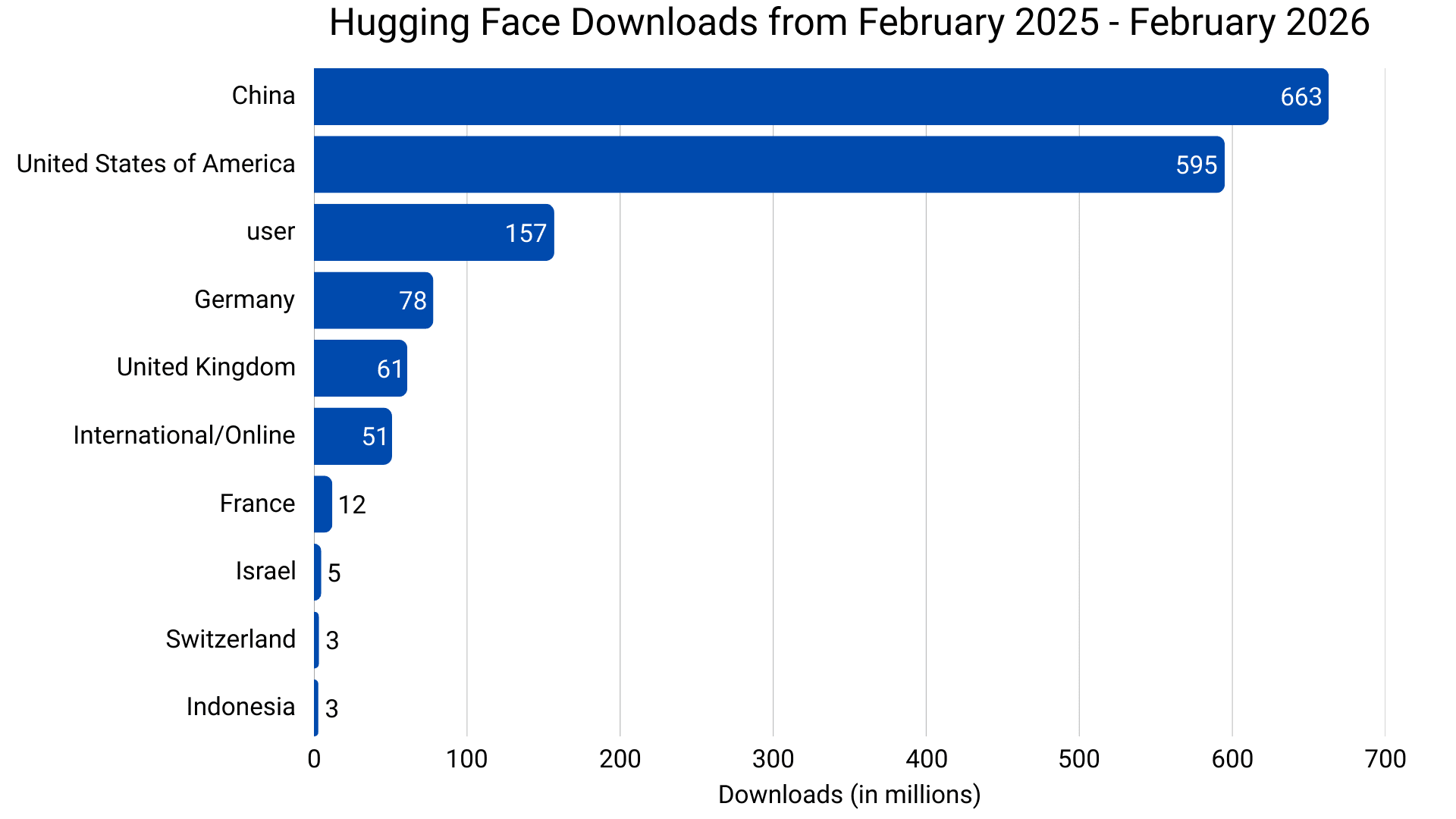
Данные и график от Hugging Face
Доля индустрии в общем объеме разработок упала с ~70% (до 2022 года) до примерно 37% в 2025 году. В то же время независимые или неаффилированные разработчики выросли с 17% до 39% от всех загрузок за этот же период, временами обеспечивая более половины общего использования. Индивидуальные разработчики и небольшие группы сфокусировались на quantization (сжатии моделей для запуска на менее мощном оборудовании), адаптации и перераспределении базовых моделей. Эти посредники теперь во многом определяют, какие модели может запустить типичный пользователь, и то, как инновации распространяются по экосистеме.
Данные от Hugging Face | График и исследование от Longpre et al. “Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem”
Разные регионы вносят разный вклад. США и Западная Европа исторически доминировали за счет крупных индустриальных лабораторий (Google, Meta, OpenAI, Stability AI), тогда как Китай все больше лидирует как по релизам, так и по внедрению. Франция, Германия и Великобритания продолжают вносить вклад через исследовательские организации, национальные AI-инициативы и специализированные семейства моделей. Экосистемы, поддерживающие разнообразие контрибьюторов и организационных форм, как правило, производят более широко используемые артефакты.
Страны, организации и индивидуальные пользователи
Популярные модели от стартапов получили более широкое распространение. Среди конкурентоспособных стран выделились Франция и Южная Корея. Примечательно, что четвертым по популярности субъектом, создающим новые трендовые модели, оказались индивидуальные пользователи, а не организации. Создавать конкурентоспособные модели на пользовательском уровне стало проще, чем когда-либо.
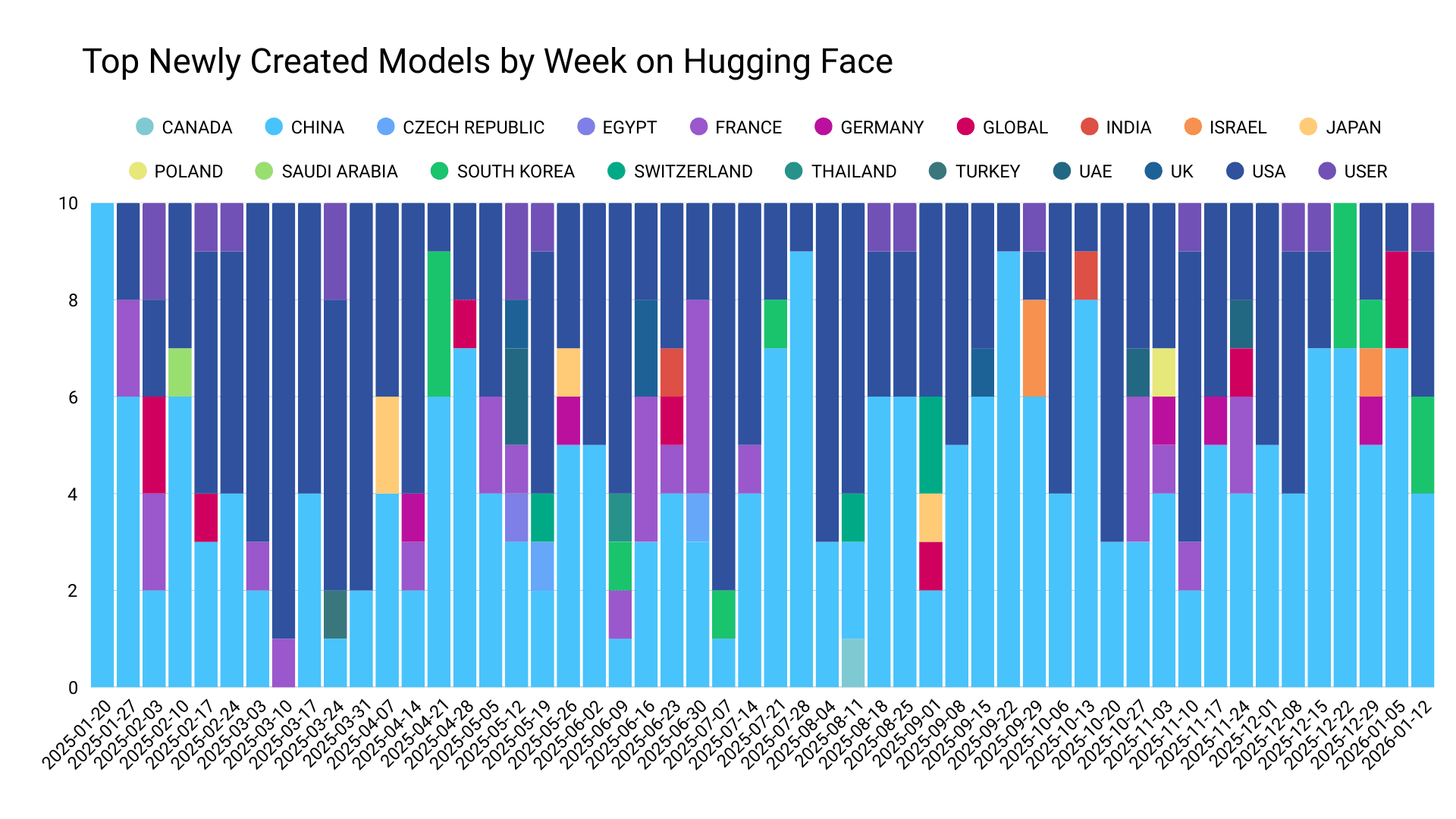
Данные и график от Hugging Face
Между США и Китаем
Среди новых моделей, созданных в 2025 году, большинство трендовых было разработано в Китае либо являлось производными от китайских моделей. Самые популярные модели создавались крупными организациями, преимущественно из США и Китая. Подробнее о китайской AI-экосистеме можно прочитать в нашей серии из трех статей, приуроченных к годовщине «DeepSeek-момента»: о стратегических изменениях, об архитектурных изменениях и об организациях и будущем.
В 2025 году AI-экосистема Китая решительно повернула в сторону open source после вирусного релиза модели R1 от DeepSeek в январе. Количество конкурентоспособных китайских организаций, выпускающих моделей, и число репозиториев на Hugging Face резко возросли. Baidu перешла от нулевых релизов на Hub в 2024 году к более чем 100 в 2025 году. ByteDance и Tencent увеличили релизы в 8–9 раз. Организации, ранее предпочитавшие закрытый подход, включая Baidu и MiniMax, решительно сменили курс в сторону открытых релизов.
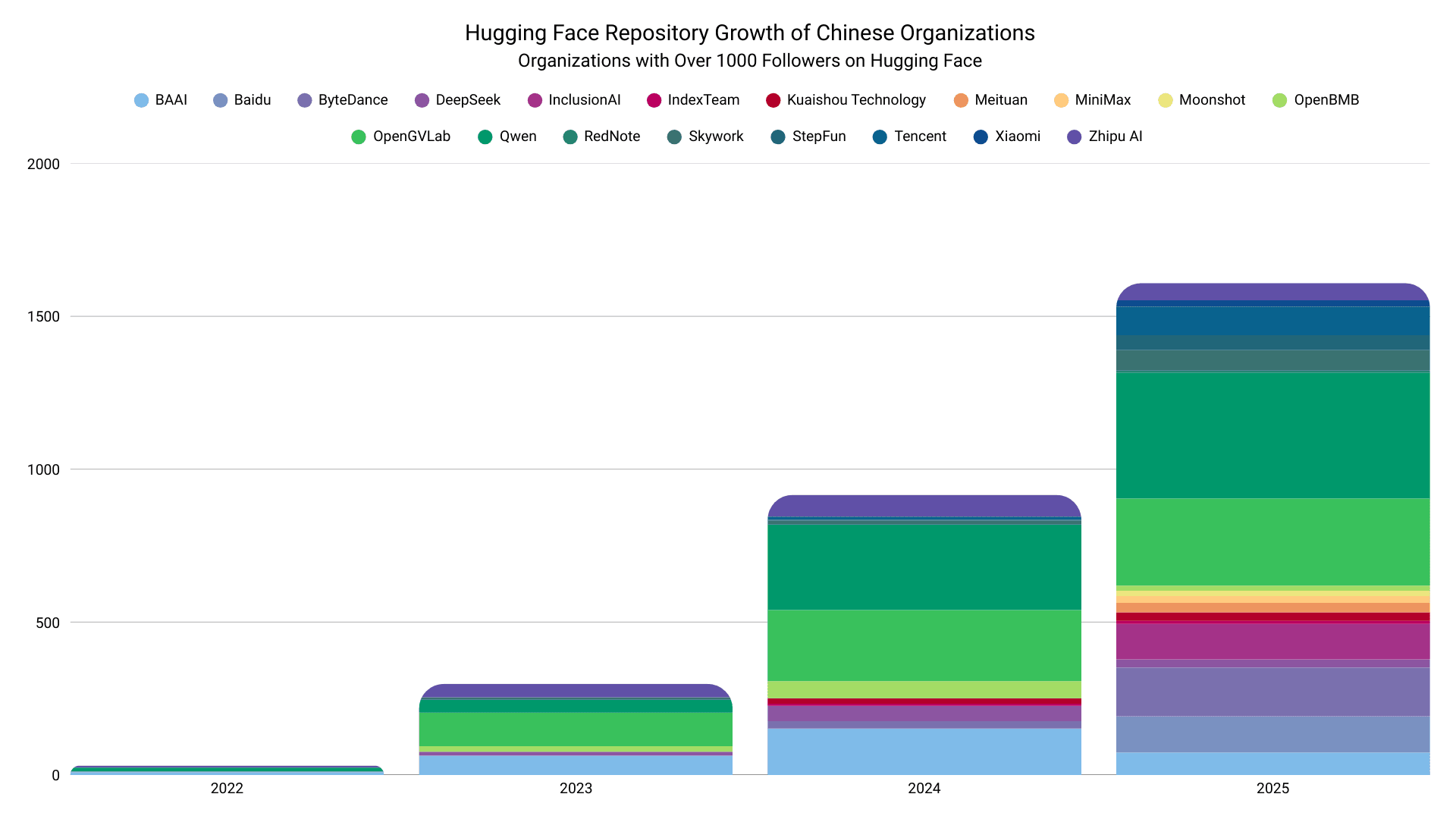
Данные и график от Hugging Face
Сопоставимое число популярных американских организаций стабильно вносило больший объем репозиториев с течением времени. Значительную долю open-релизов обеспечивает Meta (вместе с бывшей исследовательской группой Facebook), а Google — в меньшей степени.
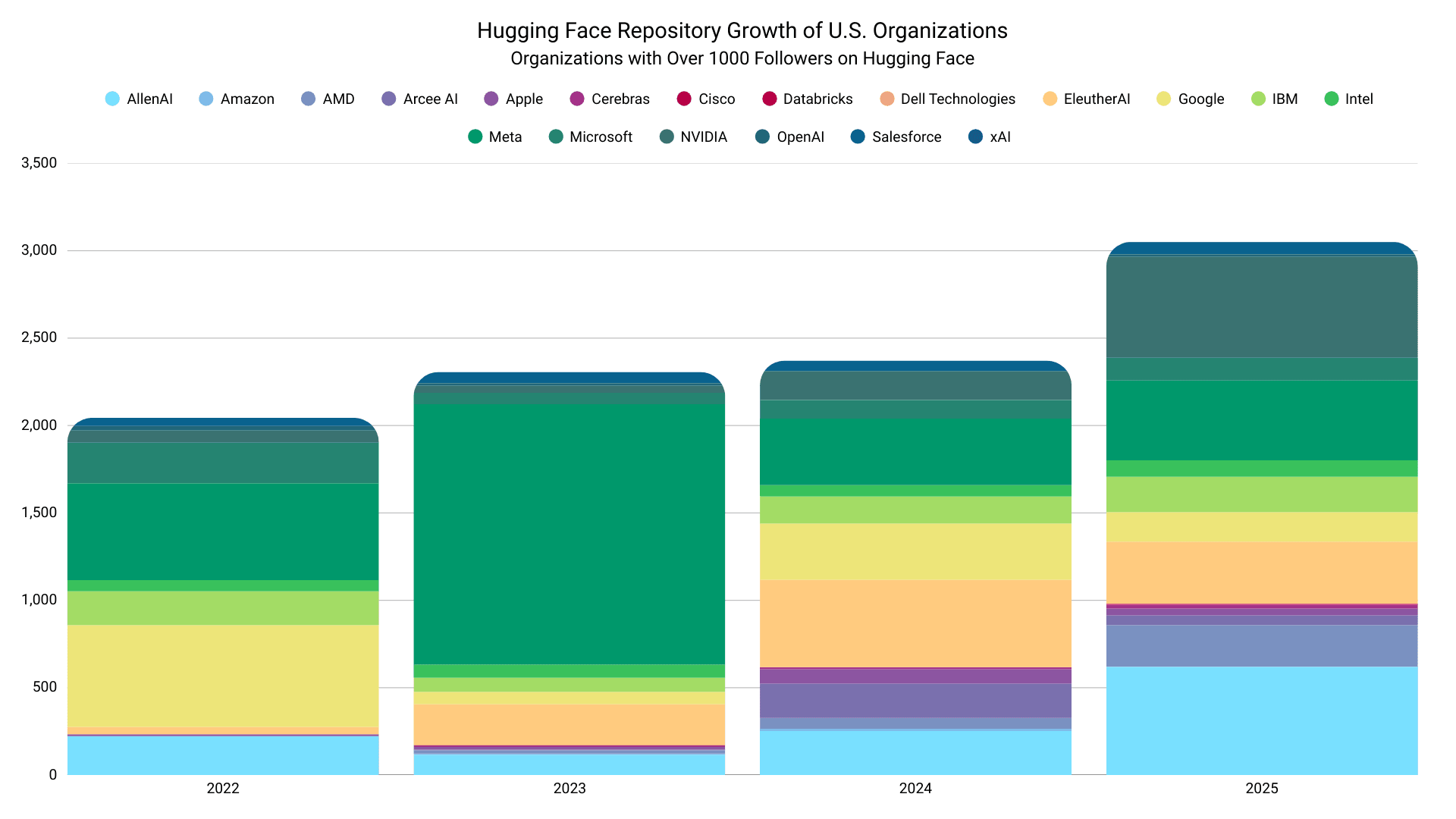
Данные и график от Hugging Face
При боковом сравнении резкий восходящий тренд роста репозиториев среди популярных китайских организаций выделяется как ключевое стратегическое различие.
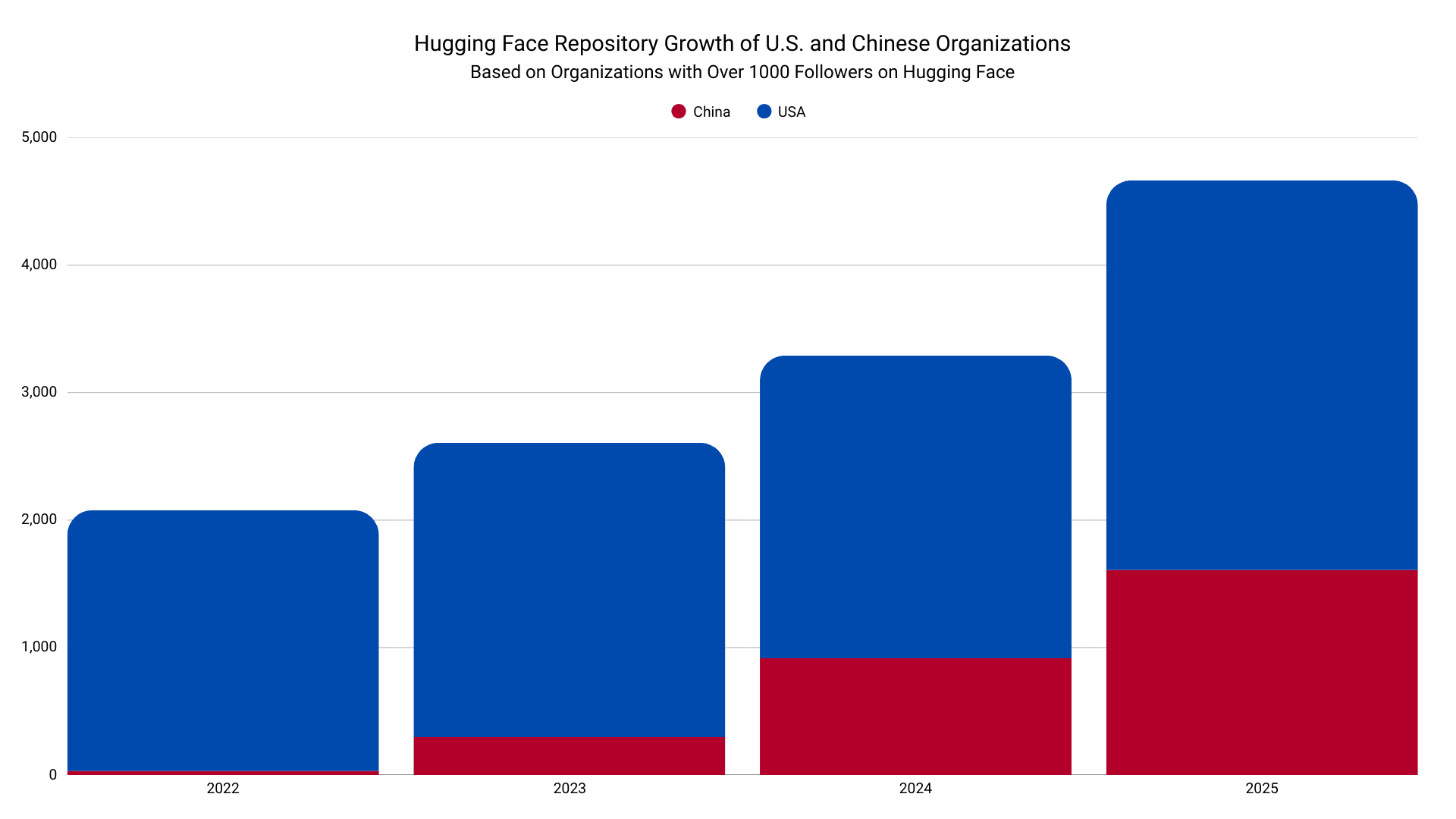
Данные и график от Hugging Face
Глобальный Open Source и суверенитет
Open source AI все больше связан с вопросами суверенитета. Модели с открытыми весами позволяют правительствам и государственным учреждениям дообучать (fine-tune’ить) системы на локальных данных в рамках национального законодательства. Модели, которые можно развернуть на отечественном железе, снижают зависимость от контролируемой из-за рубежа облачной инфраструктуры. Прозрачность архитектуры модели, процессов обучения и оценки поддерживает регуляторный контроль и публичную подотчетность. Подробнее об open source-подходе к суверенитету читайте здесь.
На национальном уровне правительства принимают меры. Инициатива национального суверенного AI Южной Кореи, запущенная в середине 2025 года, назвала национальных чемпионов — LG AI Research, SK Telecom, Naver Cloud, NC AI и Upstage — для создания конкурентоспособных отечественных моделей. В феврале 2026 года три модели из Южной Кореи одновременно попали в тренды Hugging Face Hub. В марте 2026 года Южная Корея и американский стартап Reflection AI объявили о партнерстве по созданию дата-центра, что также принесло в страну передовые open-весовые модели.
Швейцарская инициатива Swiss AI и различные проекты, финансируемые ЕС, отражают аналогичные приоритеты. Британский принцип «общественные деньги — общественный код» повлиял на несколько поддержанных государством AI-инициатив.
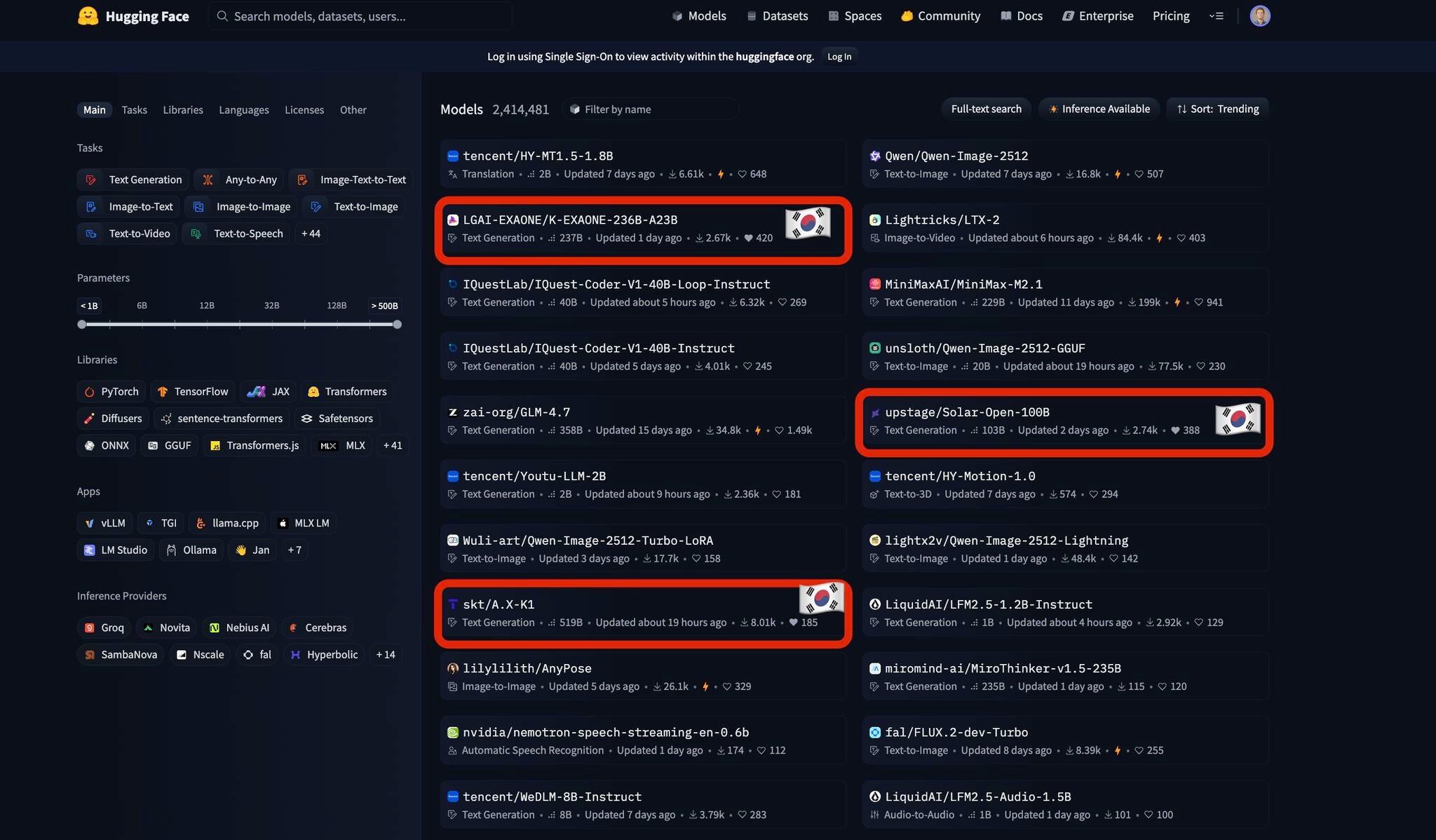
Страница трендов Hugging Face, февраль 2026 года
Инвестиции в open source и open-веса AI уже приносят дивиденды странам с собственными развитыми экосистемами обучения AI. Как мы видим, модели и датасеты обычно чаще всего используются в тех регионах, где они были разработаны: разработчики часто обращаются к моделям, которые лучше всего представляют их языки и отвечают схожим техническим и прикладным требованиям.
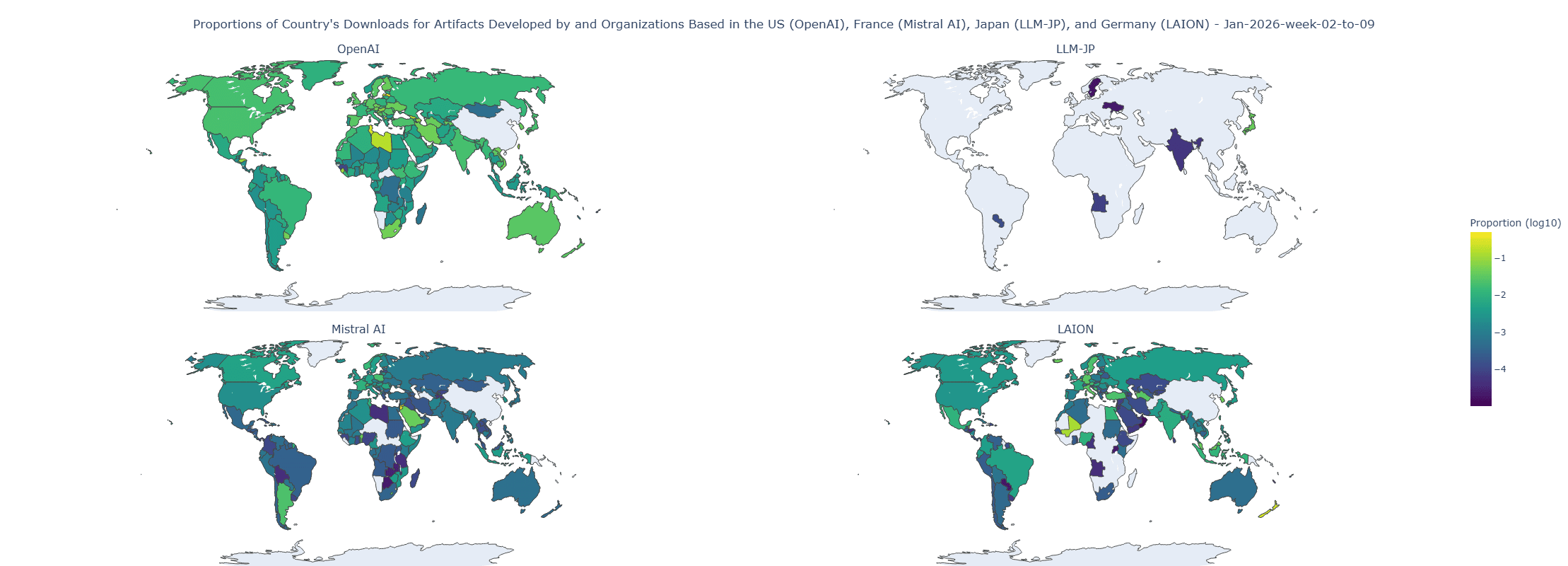
Данные и график от Hugging Face
Популярность моделей
Самые оцениваемые (liked) модели на Hub отражают внимание сообщества — возможность вернуться к модели, сослаться на нее или общий уровень популярности. Хотя эта метрика не всегда отражает реальное использование, накопленное со временем внимание служит индикатором интереса. За один год самые оцениваемые модели изменились: с преобладающего доминирования разработанных в США моделей семейства Llama от Meta они превратились в международный микс, во главе которого оказалась китайская DeepSeek-R1.

Данные и графика от Hugging Face
Статьи и научный вклад
Хотя ценность научного вклада можно оценивать по множеству метрик, наша функция upvote на Hub показывает, что статьи от крупных AI-организаций широко оцениваются членами сообщества. Примечательно, что большинство самых оцениваемых статей принадлежат крупным организациям, в основном из США и Китая. Большинство топовых организаций — китайские Big Tech компании, при этом ByteDance публикует большое количество статей с высоким импакт-фактором.
Space от Hugging Face | PaperVerse Explorer
Среди Daily Papers Hugging Face — подборки, которую курирует AK, — статьи, ссылающиеся на создание моделей и датасетов (показывающие наибольшее adoption в open source), обычно отличаются разнообразием. Медицинские статьи оказывают значительное влияние, в то время как влияние Big Tech здесь минимально.
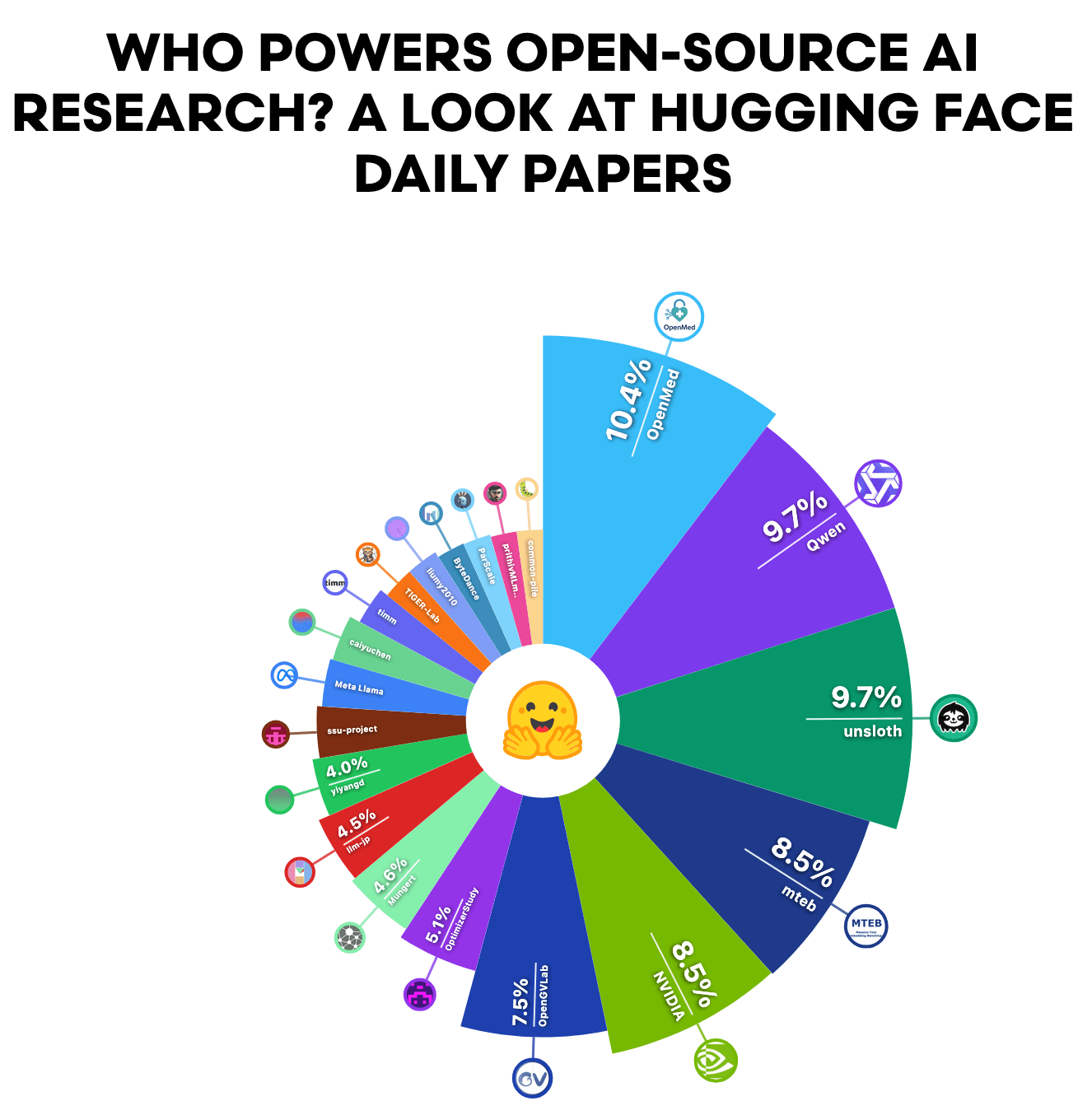
Данные от Hugging Face | Графика и статья от AI World
Производные модели
То, как члены сообщества выбирают способ построения поверх моделей — будь то fine-tuning, merging или другие методы, — отражает популярность и удобство использования модели. Как организация, Alibaba имеет больше производных моделей, чем Google и Meta вместе взятые, при этом семейство Qwen составляет более 113 000 производных моделей. Если включить все модели, отмеченные тегом Qwen, это число вырастает более чем до 200 000 моделей.
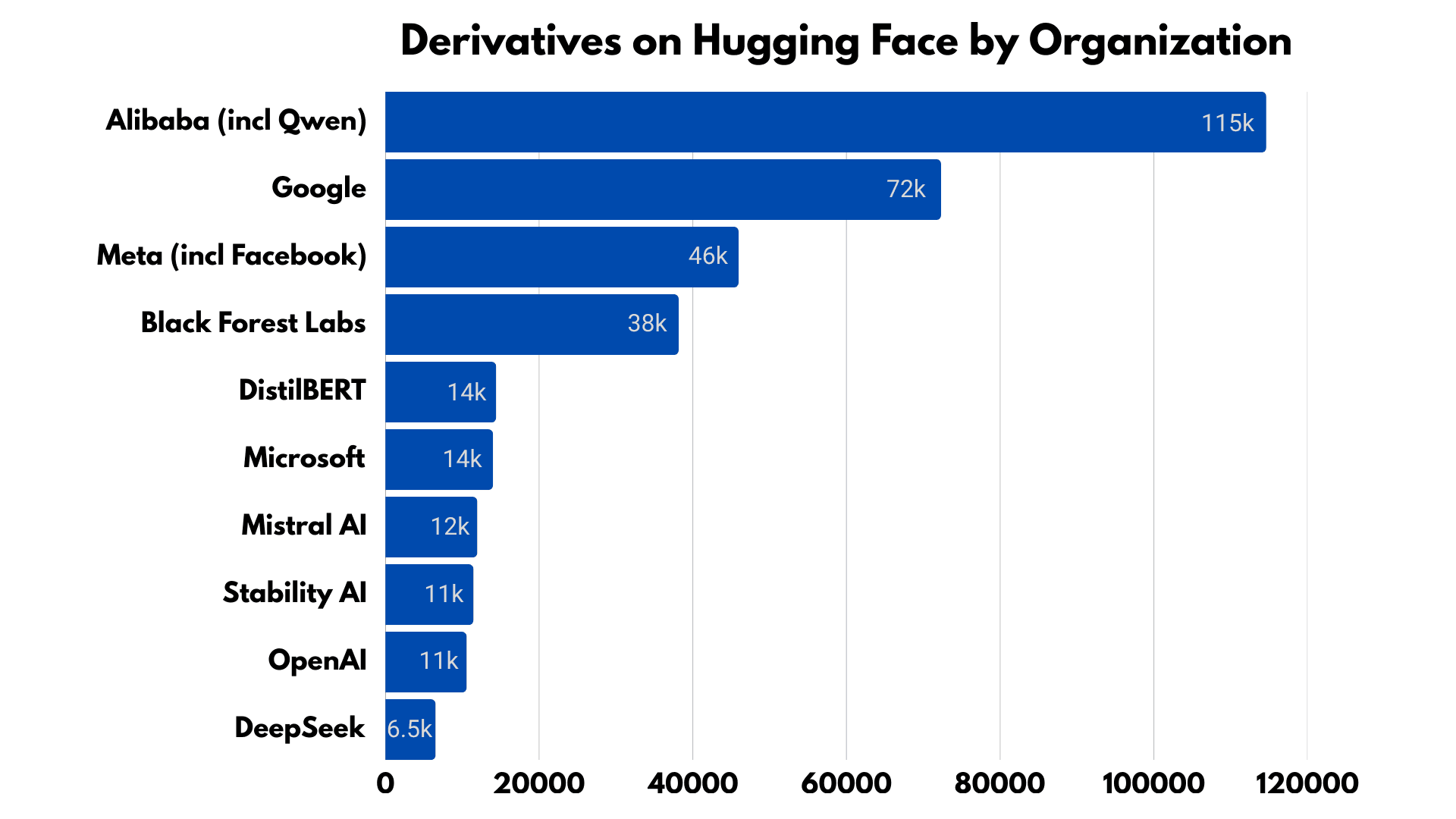
Данные и график от Hugging Face
Внедрение и доступность
Разработка моделей все больше акцентирует внимание на доступности наряду с масштабом. Малые модели загружаются и развертываются с гораздо большей частотой, чем очень большие системы, что отражает практические ограничения по стоимости, задержкам и доступности железа.
Доминирование малых моделей отчасти объясняется тем, что именно в этом размере выпускается FAR больше моделей. Но даже при нормализации этих данных статистика Relative Adoption Metric от ATOM Project показывает, что медиана топ-10 моделей с 1–9B параметров загружается примерно в 4 раза чаще, чем модели свыше 100B. Автоматизированные системы и CI-пайплайны дополнительно завышали счетчики загрузок малых моделей, но тренд на компактные, готовые к развертыванию модели реален.
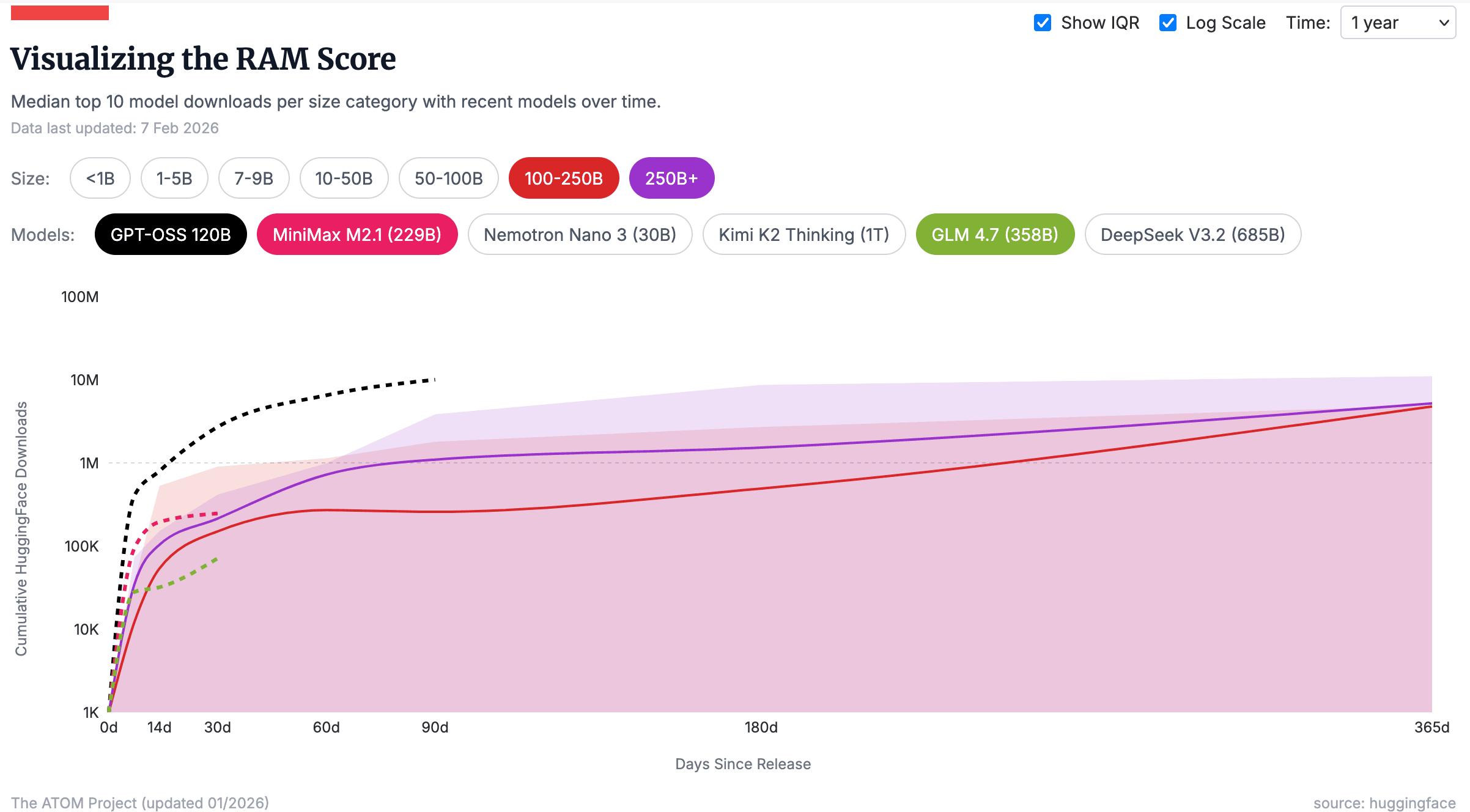
Данные от Hugging Face | График и статья от ATOM
Взаимодействие с open-моделями обычно достигает пика практически сразу после релиза, а затем замедляется. Средняя продолжительность активного интереса составляет около 6 недель. Непрерывное улучшение и частые обновления стали критически важными для удержания актуальности. Последовательные релизы DeepSeek (V3, R1, V3.2) сохраняли ее конкурентоспособность, несмотря на появление конкурентов. Организации, стагнирующие в разработке, быстро теряют долю в пользу тех, кто часто обновляет модели или выпускает domain-specific fine-tunes (доработки под конкретную предметную область).
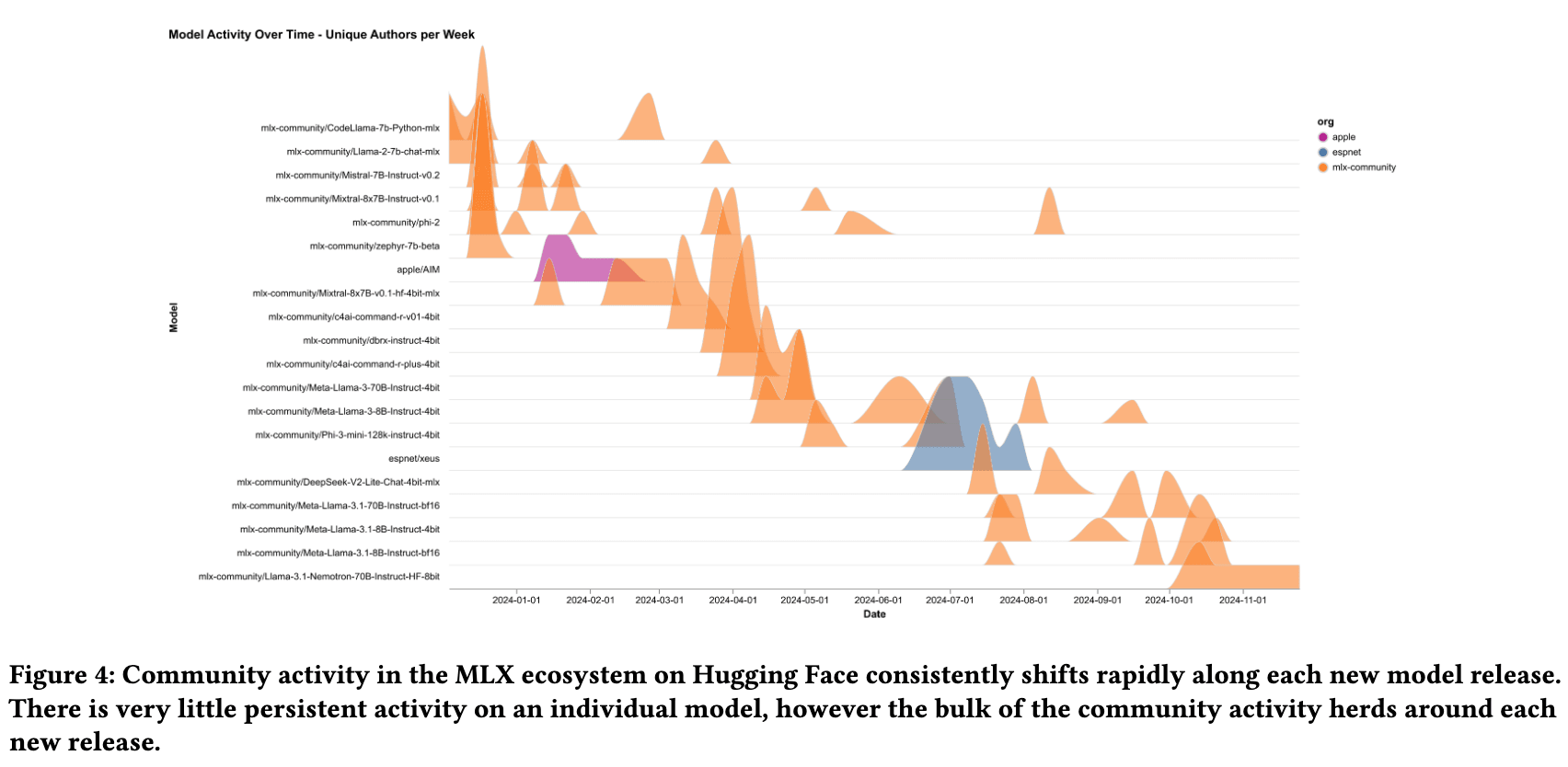
Данные от Hugging Face | График и исследование от Choksi et al. “The Brief and Wondrous Life of Open Models”
Средний размер загружаемых open-моделей вырос с 827M параметров в 2023 году до 20.8B в 2025 году, во многом благодаря quantization и архитектурам mixture-of-experts (где разные части модели специализируются на разных типах задач). Однако медиана увеличилась незначительно — с 326M до 406M параметров. Это расхождение указывает на то, что пользователи высокоуровневых LLM тянут среднее значение вверх, в то время как базовое использование малых моделей остается стабильным.
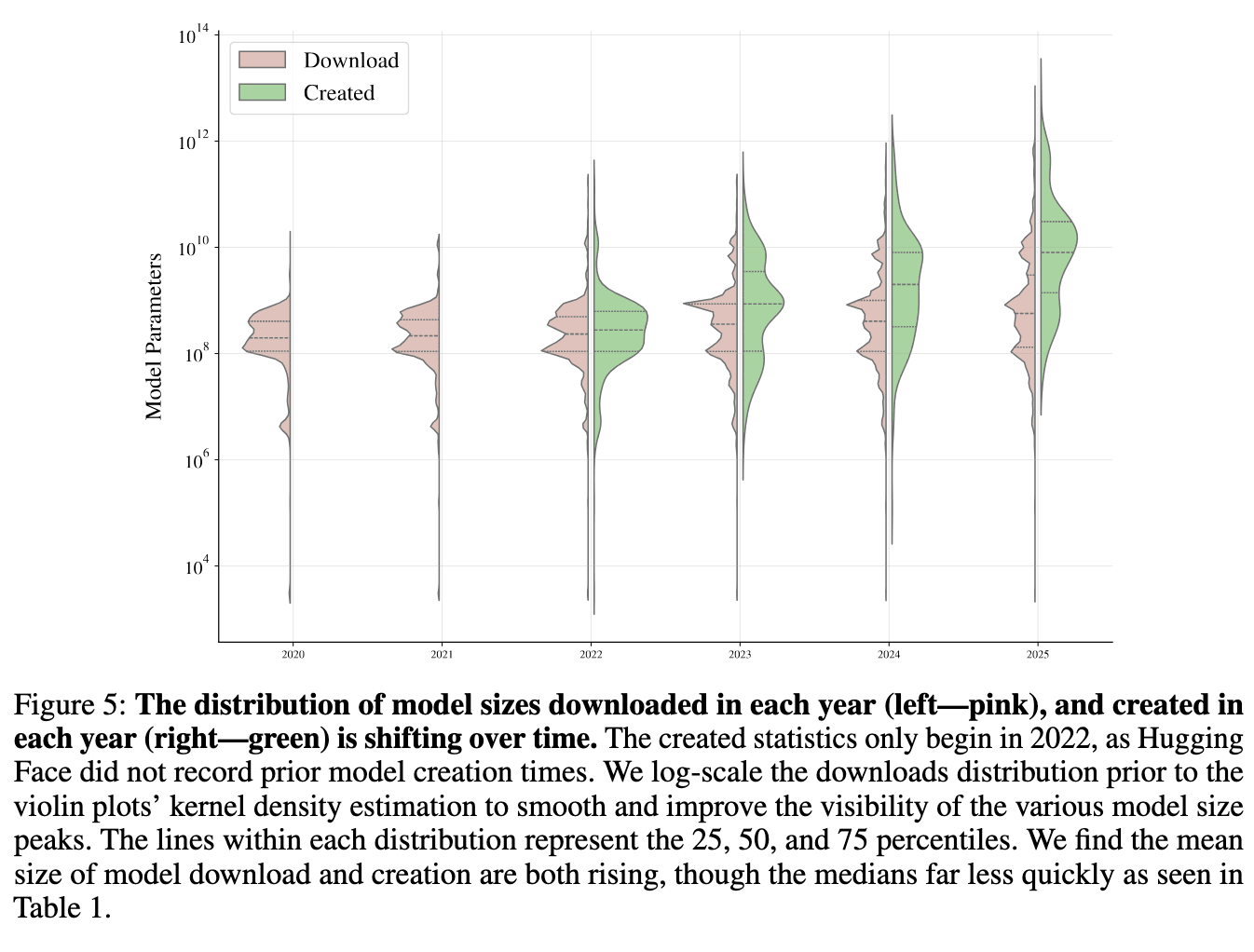
Данные от Hugging Face | График и исследование от Longpre et al. “Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem”
Разрыв в производительности между frontier-моделями (самыми мощными моделями на текущий момент) и малыми системами часто быстро сокращается благодаря fine-tuning и специфичной адаптации под задачи. На Hub модели с сотнями миллионов параметров поддерживают рабочие процессы поиска, тегирования и обработки документов, в то время как модели с размером в однозначные миллиарды параметров широко используются для кодинга, рассуждений и мультимодальных задач. В результате большинство крупных разработчиков моделей теперь выпускают семейства моделей, охватывающие широкий диапазон размеров. Подъем способных малых моделей смещает автономность ближе к edge-устройствам (конечным устройствам на границе сети — смартфонам, ПК, IoT-устройствам), снижая зависимость от централизованных облачных провайдеров.
Вычислительные мощности, железо и Open Source
Разработка open source AI тесно связана с трендами в железе. Большинство моделей оптимизированы под GPU NVIDIA, но поддержка оборудования AMD продолжает расширяться. Коллекции моделей Stability AI теперь оптимизированы как для платформ NVIDIA, так и для AMD. Все больше библиотек нацелены на обе платформы, а инструментарий улучшился, чтобы сделать кросс-аппаратное развертывание более простым. В 2025 году Hugging Face запустил Kernel Hub для загрузки и запуска ядер, оптимизированных для GPU NVIDIA и AMD.
Параллельно китайские open-модели выпускаются с явной поддержкой отечественно разработанных чипов. Alibaba инвестировала в архитектуры чипов, ориентированных на inference (выполнение модели — генерацию ответов), чтобы заполнить китайские дата-центры оборудованием, способным локально запускать open source модели.
Хотя доступ к вычислительным мощностям остается фундаментальной необходимостью для разработки и развертывания AI-моделей, open source и модели с открытыми весами помогают вырваться из экосистемы, где это является единственным определяющим фактором. Все больше моделей на всех уровнях производительности снижают затраты в 10–1000 раз по сравнению с флагманскими AI-моделями от крупнейших разработчиков.
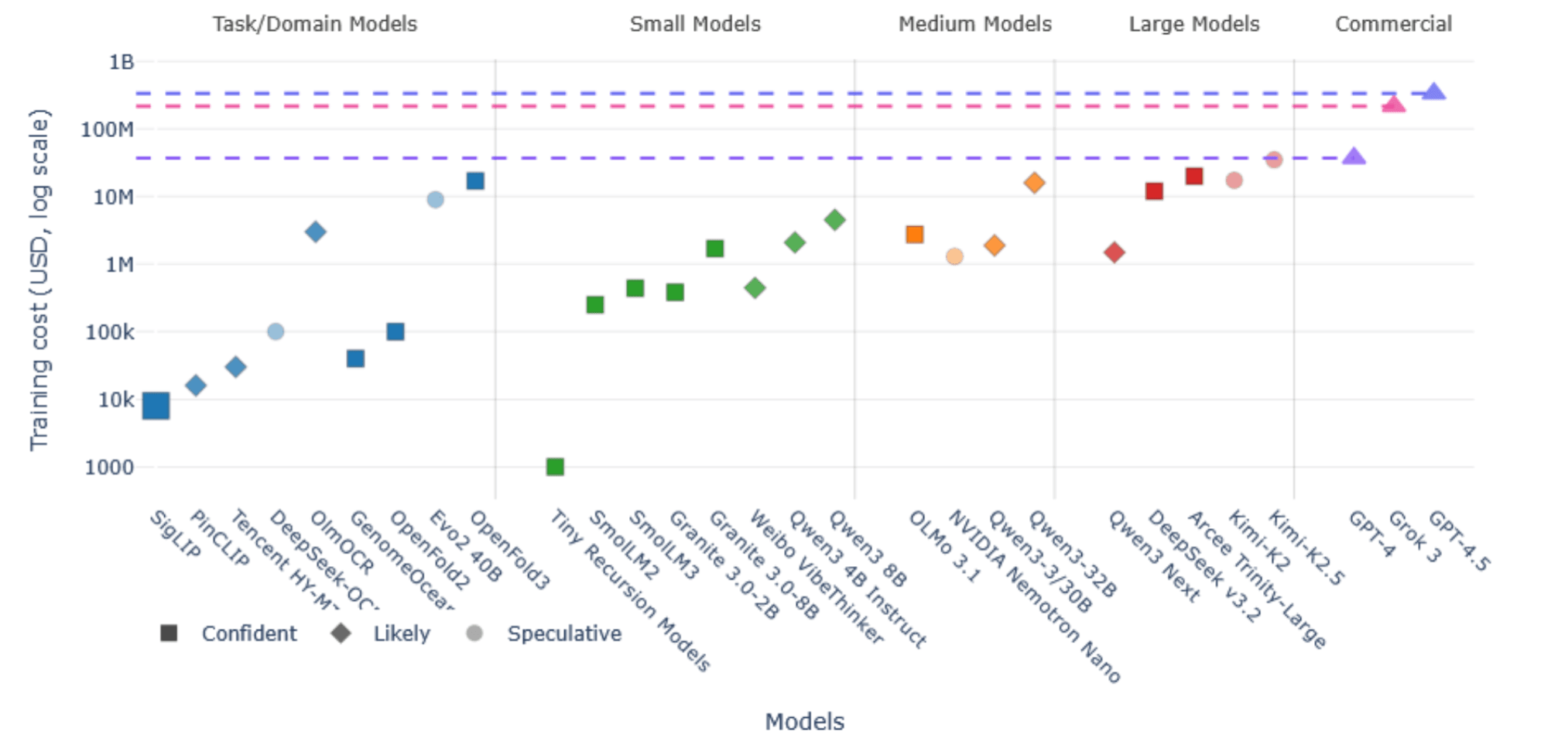
Данные и графика от Hugging Face
Тем не менее вопрос инфраструктурных инвестиций для open source остается острым. Государственное финансирование дата-центров, способных обучать и обслуживать open-модели, становится растущей темой для политических дискуссий, особенно в Европе и Великобритании. Разрыв между вычислительными ресурсами, доступными крупным компаниям с закрытыми моделями, и теми, что доступны open source-сообществу, продолжает определять, что осуществимо в рамках открытой разработки.
Субсообщества: Робототехника
Робототехника стала одним из самых быстрорастущих субсообществ на Hugging Face. Цифры впечатляют: количество датасетов по робототехнике выросло с 1 145 в 2024 году до 26 991 в 2025 году, поднявшись с 44-го места на первое место по количеству датасетов на Hub всего за три года. Для сравнения, text generation, вторая по величине категория, насчитывала в 2025 году всего около 5 000 датасетов.
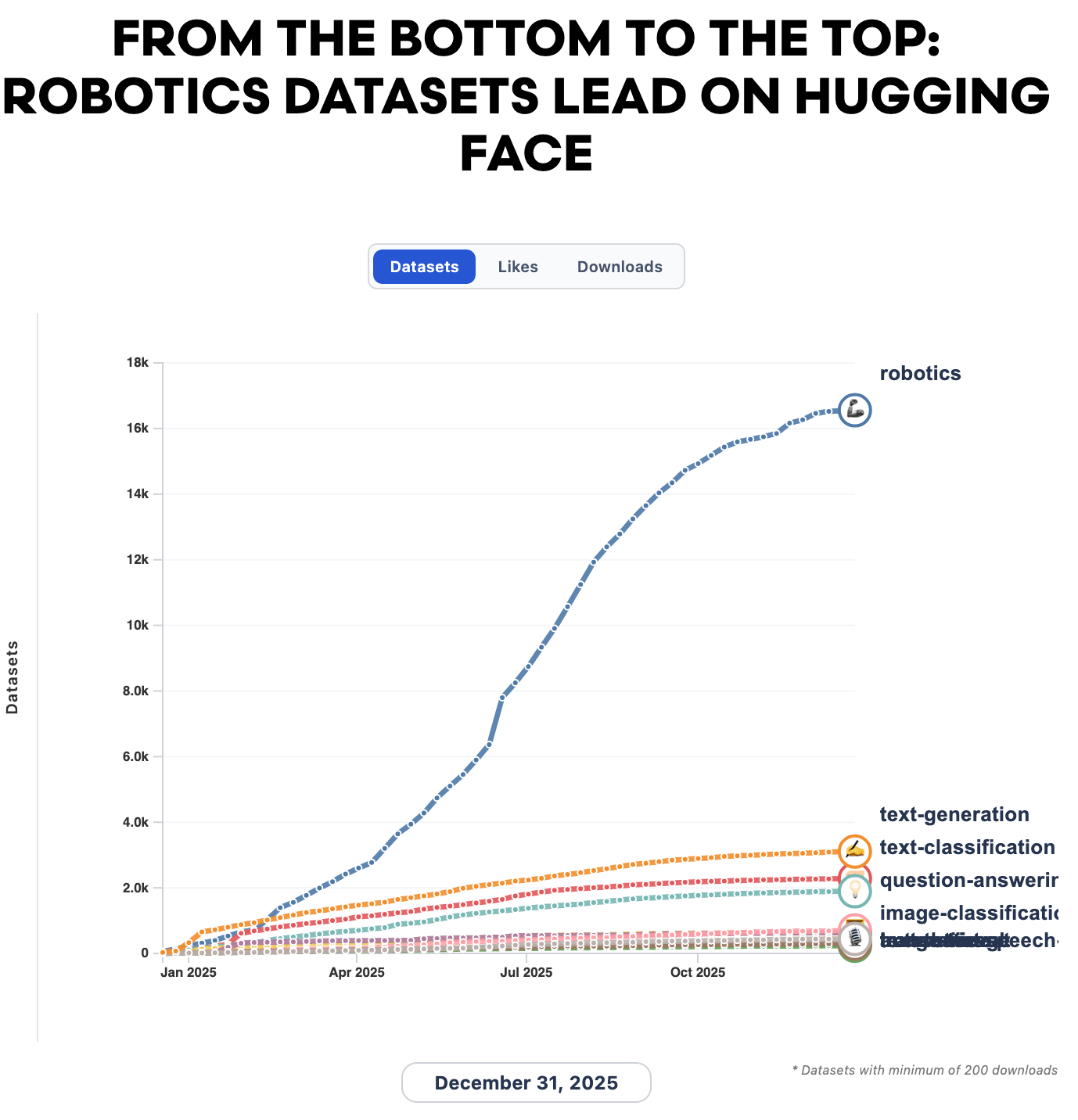
Данные от Hugging Face | График и статья от AI World
Датасеты, предоставленные сообществом, охватывают всё — от бытовых манипуляционных задач до автономного вождения. Крупнейший мультимодальный датасет для пространственного интеллекта, Learning to Drive (L2D), был выпущен в результате сотрудничества LeRobot с Yaak. Такие датасеты, как RoboMIND, содержащий более 107 000 реальных траекторий по 479 различным задачам и множеству роботизированных платформ, обеспечивают тот масштаб и разнообразие, которые необходимы для обучения обобщаемых роботизированных политик (алгоритмов управления роботами).
Поглощение Pollen Robotics компанией Hugging Face открыло продажи open source-роботов как для индустрии и академических лабораторий, так и для повседневных энтузиастов. LeRobot, open source-библиотека робототехники от Hugging Face, предоставляющая модели, датасеты и инструменты для работы с реальной робототехникой в PyTorch, пережила стремительный рост. Библиотека охватывает imitation learning (обучение путем копирования действий эксперта), reinforcement learning (обучение методом проб и ошибок с наградами) и vision-language-action модели (модели, объединяющие зрение, язык и управление действиями). За прошедший год количество звезд на ее GitHub-репозитории почти утроилось.
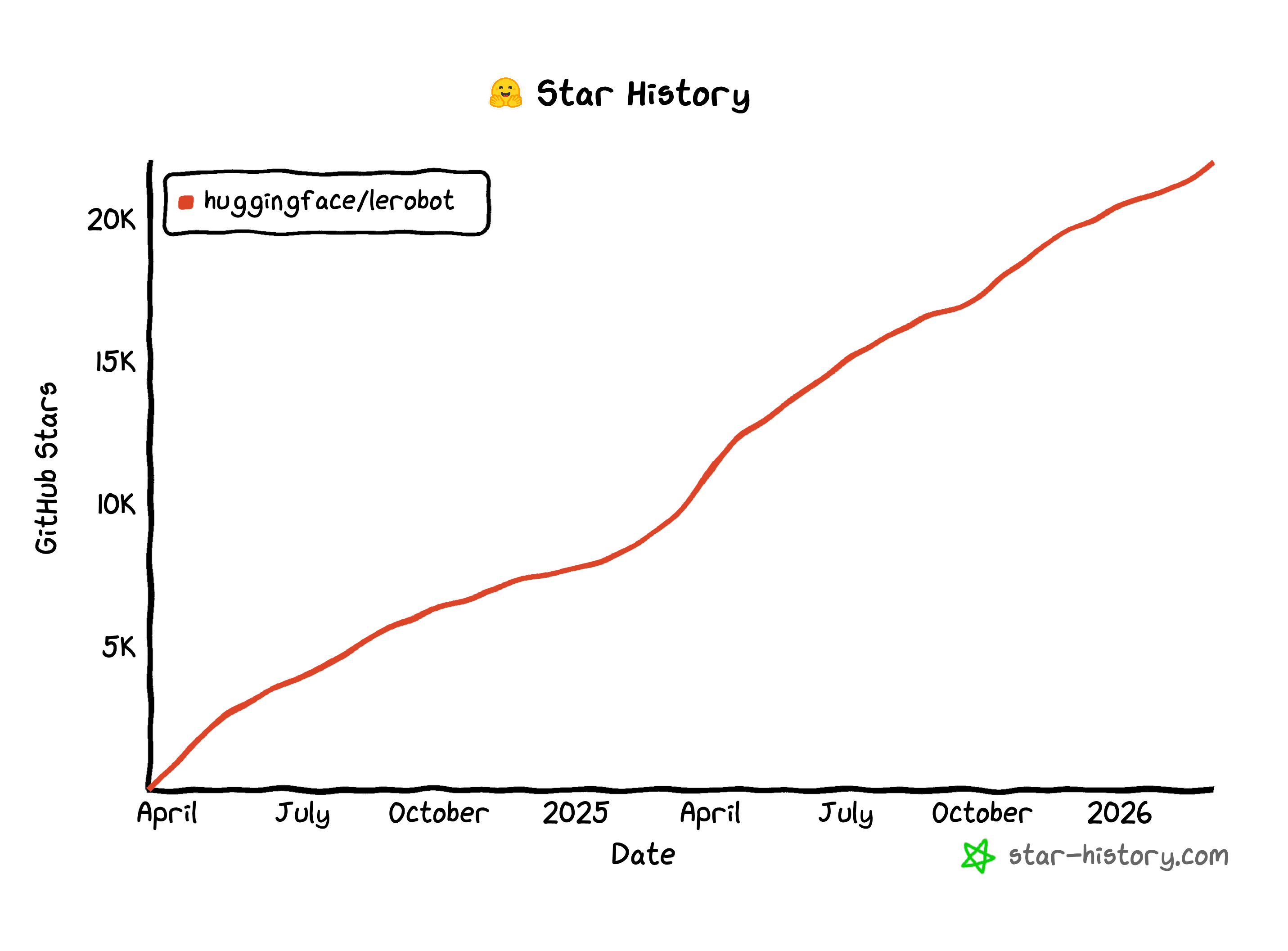
Данные с GitHub | Графика от star-history.com
Субсообщества: ИИ для науки
Научные исследования стали еще одной особенно активной областью. Open-модели и датасеты всё чаще используются для предсказания структуры белков, молекулярной динамики, открытия лекарств и анализа научных данных. Теперь все frontier AI-компании имеют специализированные научные команды, хотя текущий фокус по-прежнему во многом смещен на поиск по литературе, а не на прямые эксперименты.
Space от Hugging Face | Science Release Heatmap
Проекты, инициированные сообществом, сформировались вокруг общих исследовательских целей, часто с участием сотен контрибьюторов, работающих в разных учреждениях и дисциплинах. Эти усилия показывают, что open source работает как механизм координации крупномасштабных междисциплинарных работ. Такие проекты было бы трудно организовать в рамках традиционных академических или корпоративных структур.
Взгляд в будущее
Экосистема open source AI продолжает развиваться благодаря сочетанию глобального участия, технической специализации и институционального внедрения. Несколько трендов, вероятно, будут определять следующий этап.
Географический перебаланс сил ускоряется. Западные организации всё активнее ищут коммерчески жизнеспособные альтернативы китайским моделям. Это придает срочность таким усилиям, как GPT-OSS от OpenAI, OLMo от AI2 и Gemma от Google. Эти проекты призваны предложить конкурентоспособные open-варианты от разработчиков из США и Европы. Смогут ли эти усилия сравниться по темпам adoption с Qwen и DeepSeek — ключевой вопрос 2026 года.
Рост субсообществ в робототехнике и науке свидетельствует о том, что open source AI выходит за рамки генерации текста и изображений. Он проникает в физические и экспериментальные домены. Инфраструктура, нормы и механизмы координации, разработанные вокруг текстовых и графических моделей, адаптируются для новых модальностей и сценариев использования.
Для исследователей, разработчиков, компаний и правительств open source остается фундаментальным слоем для создания, оценки и управления AI-системами. С ростом числа agentic-развертываний (развертываний AI-агентов, автономно выполняющих цепочки задач) open source и совместимость (interoperability) станут ключевыми для успешной работы агентов. Траектория за прошедший год делает одну вещь очевидной: именно в open source-экосистеме происходит большая часть практической работы по разработке, адаптации и развертыванию AI. Ее влияние на более широкий ландшафт AI продолжает расти.
Спасибо сообществу Hugging Face за то, что оно продолжает строить фундамент AI-экосистемы 🤗