
Развитие мультимодальных больших языковых моделей (MLLM) позволило browsing-агентам находить и анализировать мультимодальную информацию из реального веба. Но существующие бенчмарки имеют два серьёзных недостатка: слабо оценивают визуальное рассуждение и игнорируют визуальную информацию веб-страниц в цепочке рассуждений. Чтобы закрыть эти пробелы, команда исследователей из CASIA, Ant Group, RUC, THU и других организаций представила VisBrowse-Bench — бенчмарк для визуально-ориентированного поиска.
VisBrowse-Bench содержит 169 VQA-примеров (задач визуального вопрос-ответа) из семи предметных областей. Он оценивает визуально-рассуждающие способности моделей в процессе поиска через перекрёстную проверку мультимодальных свидетельств с помощью поиска изображений по тексту (text-image retrieval) и совместных рассуждений. Данные построены экспертами вручную по многоэтапному пайплайну и прошли строгую верификацию. Дополнительно предложен агентный workflow, побуждающий browsing-агента активно собирать и анализировать визуальную информацию при поиске.
Результаты: даже лучшая модель, Claude-4.6-Opus, набирает лишь 47.6% точности, а проприетарная Deep Research-модель o3-deep-research — 41.1%.
Код и данные: https://github.com/ZhengboZhang/VisBrowse-Bench
Проблема существующих бенчмарков
Большинство текущих бенчмарков (например, MMSearch и BrowseComp-VL) лишь проверяют умение моделей вызывать инструменты для обработки текстово-изображенных запросов. Обычно модель получает изображение, отправляет его в инструмент поиска — и на этом визуальная задача исчерпана. Такое тестирование не требует тонкого понимания мультимодальной информации и по сути проверяет лишь навык вызова инструментов.

Рисунок 1: Существующие бенчмарки имеют два ограничения при оценке мультимодальных browsing-агентов: 1. семантическую информацию визуального запроса легко извлечь через инструменты image search; 2. реальные browsing-окружения содержат массу мультимодальной информации, которую большинство бенчмарков игнорирует. VisBrowse-Bench спроектирован так, чтобы объединять мультимодальную информацию в процессе поиска и делать визуальные способности критически необходимыми для решения задачи.
Даже бенчмарки, требующие начального визуального восприятия запроса (MMSearch-Plus, VDR-Bench), сводят последующий сбор информации к одномодальному текстовому обходу. Стоит запрос-изображение выдать имя сущности или подпись — и всё дальнейшее рассуждение выполняется через текстовый поиск документов. Траектория поиска никогда не требует привязки, разбора или рассуждений над дополнительной визуальной информацией, обнаруженной в процессе. Задача вырождается в текстовый browsing и не проверяет, умеет ли модель динамически находить и интегрировать визуальную информацию, когда она не дана заранее.
VisBrowse-Bench
Бенчмарк охватывает семь категорий: Media, Life, Art, Geography, Technology, Sport и Finance, каждая с несколькими подкатегориями.

Рисунок 4: Обзор VisBrowse-Bench: примеры вопросов и ответов по семи категориям.
Принципы проектирования данных
Два ключевых принципа:
Интеграция мультимодальной информации. И формулировка запроса, и сбор свидетельств требуют активной обработки визуальной и текстовой модальностей. Каждый вопрос сопровождается набором референсных изображений с критически важными подсказками — без визуального восприятия запрос не понять. Пространство поиска состоит из перемежающихся текстовых документов и визуальных материалов. Успешный сбор свидетельств требует мультимодальных запросов и ранжирования смешанно-модальных результатов.
Обязательность визуальных компетенций. Вся визуальная информация структурно незаменима — её нельзя подменить текстовыми подписями или семантическими описаниями. Модель вынуждена задействовать пространственную привязку (spatial grounding — определение положения объектов на изображении), восприятие атрибутов и реляционный парсинг (анализ связей между объектами). Задачи используют пространственную информацию для описания визуальных элементов, требуют точной визуальной локализации, затрагивают перцептивные атрибуты, отсутствующие в тексте. Финальная интеграция информации требует cross-image рассуждений — визуального выравнивания изображений, а не текстового сопоставления.
Сбор данных
Два эксперта в каждой категории независимо отбирают начальные сущности и управляют поисковыми ключевыми словами. Сущности проходят жёсткий отбор: для них должно существовать достаточно публично доступных мультимодальных документов. Эксперты ищут изображения с визуально неоднозначными сущностями, перекрывающимися областями или множеством сосуществующих объектов — требующими точной пространственной локализации и анализа на уровне пикселей.
Сбор идёт через итеративный обход «сущность → событие → визуальная информация». Эксперты находят реальные события, связанные с сущностью, затем через события локализуют дополнительную визуальную информацию. При этом визуальная информация должна указывать на новую связанную сущность, отличную от предыдущего шага. Процесс визуального поиска, связывания и cross-modal перехода сущностей (между текстом и изображением) повторяется рекурсивно — получаются многошаговые (multi-hop) цепочки свидетельств с не менее чем двумя визуальными блоками.
Валидация качества
Двухуровневая проверка. На уровне инстанции — два эксперта подтверждают, что визуальная информация структурно незаменима. Каждое решение должно покрывать минимум три шага (hop) и не менее двух визуальных блоков свидетельств, причём проверяется отсутствие одношаговых ярлыков.
На уровне корпуса — верификация разрешимости и уникальности ответа. Каждый вопрос независимо решают два эксперта с полной фиксацией хода рассуждений. Инстанции, где эксперты не сходятся или выявляют пробелы в свидетельствах, отправляются на перестройку или исключаются.
Статистика датасета
Датасет сбалансирован по семи основным категориям, дополнительно разбит на 24 подкатегории. Каждый вопрос содержит минимум одно изображение как визуальный запрос. Средняя длина текстовой части вопроса — 47.7 слова.
Агентный фреймворк
Для реализации парадигмы мультимодального deep search спроектирован агентный workflow с пятью инструментами:
- text_search — агент отправляет текстовый запрос, SerperAPI возвращает ранжированные кандидаты веб-страниц (заголовки, сниппеты, URL):
text_search(query) → [(title, webpage_url, snippet), ...]- image_search — поиск недостающих визуальных свидетельств по текстовому запросу; SerperAPI возвращает семантически похожие изображения с информацией о содержащих их страницах:
image_search(query) → [(title, image_url, webpage_url), ...]- reverse_image_search — поиск по изображению; SerperAPI возвращает похожие изображения с информацией о страницах:
reverse_image_search(image_url) → [(title, image_url, webpage_url), ...]- image_crop — извлечение области интереса для локального визуального анализа:
crop_image(image_url) → cropped_url- webpage_visit — агент передаёт целевой URL и запрос, JinaAPI возвращает структурированную информацию страницы; LLM сжимает и анализирует контент, генерируя промежуточные выводы:
webpage_visit(webpage_url, query) → conclusionWorkflow работает как замкнутый контур: MLLM разбирает мультимодальный запрос, формирует начальную стратегию поиска, вызывает нужные инструменты на основе текущих пробелов в свидетельствах, обрабатывает результаты, обновляет внутреннее состояние и уточняет следующие запросы — пока не соберёт достаточно данных для синтеза ответа. Это гарантирует, что сбор визуальных и текстовых свидетельств перемежается на протяжении всей цепочки рассуждений.
Сравнение с существующими бенчмарками
| Бенчмарк | Мультимодальные запросы | Многоходовое взаимодействие | Публичная поисковая информация | Экспертная валидация | Thinking with image | Визуальные свидетельства | Cross-image рассуждения |
|---|---|---|---|---|---|---|---|
| MMSearch | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| BrowseComp-VL | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| MM-BrowseComp | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| MMSearch-Plus | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ |
| VDR-Bench | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| VisBrowse-Bench (наш) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
VisBrowse-Bench — единственный бенчмарк, объединяющий все семь характеристик: он встраивает визуальные свидетельства в процесс поиска и рассуждений, требует от MLLM «думать с изображениями» и рассуждать через несколько изображений одновременно.
Эксперименты
Setup
Оценываемые модели. Закрытые: Gemini-3.0-Pro, Gemini-3.0-Flash, Gemini-2.5-Pro, Gemini-2.5-Flash, GPT-5.2, GPT-5.1, Claude-4.6-Opus, Claude-4.6-Sonnet, Kimi-K2.5, Qwen3-VL-Plus. Открытая: Qwen3-VL-235B-A22B-Instruct. Deep Research: o3-Deep-Research.
Методы оценки — три уровня использования инструментов:
- Direct Answer — модель отвечает без внешних инструментов, опираясь на встроенные знания (параметрические знания).
- + TS — доступны только
text_searchиwebpage_visit. - + IS — доступны все пять инструментов фреймворка.
Метрика — accuracy (%). Из ответа модели регулярным выражением извлекается финальный ответ, затем GPT-5.1 как judge-модель сравнивает его с эталонным ответом (ground truth) через подход LLM-as-Judge.
Основные результаты
Таблица 2. Основные результаты VisBrowse-Bench по категориям. Метрика — accuracy (%). Зелёные числа — улучшение относительно предыдущего метода, красные — ухудшение. Жирные — лучшая точность, подчёркнутые — вторая.
| Модель | Метод | Overall | Media | Life | Art | Geography | Technology | Sport | Finance | |---|---|---|---|---|---|---|---|---| | Закрытые модели | | | | | | | | | | | Gemini-3.0-Pro | Direct Answer | 23.7 | 25.9 | 16.7 | 28.6 | 30.4 | 25.9 | 16.7 | 18.8 | | | + TS | 38.5 (+14.8) | 44.4 | 45.8 | 35.7 | 39.1 | 25.9 | 50.0 | 25.0 | | | + IS | 40.2 (+1.7) | 44.4 | 45.8 | 42.9 | 43.5 | 48.1 | 29.2 | 18.8 | | Gemini-3.0-Flash | Direct Answer | 32.5 | 29.6 | 33.3 | 28.6 | 34.8 | 37.0 | 33.3 | 31.2 | | | + TS | 37.9 (+5.4) | 40.7 | 50.0 | 28.6 | 43.5 | 29.6 | 45.8 | 25.0 | | | + IS | 39.1 (+1.2) | 40.7 | 45.8 | 32.1 | 43.5 | 37.0 | 45.8 | 25.0 | | Gemini-2.5-Pro | Direct Answer | 19.5 | 25.9 | 4.2 | 28.6 | 26.1 | 14.8 | 12.5 | 25.0 | | | + TS | 20.7 (+1.2) | 40.7 | 4.2 | 25.0 | 26.1 | 18.5 | 16.7 | 6.2 | | | + IS | 26.6 (+5.9) | 37.0 | 25.0 | 32.1 | 34.8 | 22.2 | 25.0 | 0.0 | | Gemini-2.5-Flash | Direct Answer | 9.5 | 14.8 | 4.2 | 0.0 | 13.0 | 22.2 | 8.3 | 0.0 | | | + TS | 17.2 (+7.7) | 40.7 | 16.7 | 10.7 | 21.7 | 7.4 | 12.5 | 6.2 | | | + IS | 20.7 (+3.5) | 37.0 | 12.5 | 14.3 | 26.1 | 29.6 | 16.7 | 0.0 | | GPT-5.2 | Direct Answer | 14.8 | 7.4 | 25.0 | 21.4 | 13.0 | 18.5 | 12.5 | 0.0 | | | + TS | 26.0 (+11.2) | 33.3 | 41.7 | 17.9 | 26.1 | 25.9 | 25.0 | 6.2 | | | + IS | 28.4 (+2.4) | 37.0 | 29.2 | 25.0 | 30.4 | 37.0 | 25.0 | 6.2 | | GPT-5.1 | Direct Answer | 13.0 | 14.8 | 20.8 | 21.4 | 17.4 | 11.1 | 0.0 | 0.0 | | | + TS | 16.6 (+3.6) | 25.9 | 29.2 | 14.3 | 21.7 | 14.8 | 0.0 | 6.2 | | | + IS | 23.1 (+6.5) | 22.2 | 41.7 | 14.3 | 30.4 | 22.2 | 12.5 | 18.8 | | Claude-4.6-Opus | Direct Answer | 27.2 | 37.0 | 25.0 | 28.6 | 26.1 | 29.6 | 20.8 | 18.8 | | | + TS | 42.6 (+15.4) | 48.1 | 45.8 | 35.7 | 56.5 | 48.1 | 33.3 | 25.0 | | | + IS | 47.6 (+5.0) | 53.6 | 50.0 | 35.7 | 56.5 | 59.3 | 45.8 | 25.0 | | Claude-4.6-Sonnet | Direct Answer | 13.0 | 18.5 | 12.5 | 14.3 | 26.1 | 11.1 | 4.2 | 0.0 | | | + TS | 23.7 (+10.7) | 29.6 | 20.8 | 25.0 | 39.1 | 14.8 | 20.8 | 12.5 | | | + IS | 18.3 (-5.4) | 25.9 | 20.8 | 3.6 | 30.4 | 18.5 | 20.8 | 6.2 | | Kimi-K2.5 | Direct Answer | 21.3 | 18.5 | 12.5 | 17.9 | 26.1 | 25.9 | 29.2 | 18.8 | | | + TS | 21.9 (+0.6) | 29.6 | 16.7 | 14.3 | 34.8 | 29.6 | 16.7 | 6.2 | | | + IS | 41.4 (+19.5) | 63.0 | 50.0 | 39.1 | 51.9 | 33.3 | 18.8 | — | | Qwen3-VL-Plus | Direct Answer | 17.8 | 18.5 | 20.8 | 17.9 | 8.7 | 25.9 | 20.8 | 6.2 | | | + TS | 27.8 (+10.0) | 33.3 | 29.2 | 21.4 | 30.4 | 37.0 | 20.8 | 18.8 | | | + IS | 32.5 (+4.7) | 37.0 | 50.0 | 39.1 | 40.7 | 16.7 | 12.5 | — | | Открытые модели | | | | | | | | | | | Qwen3-VL-235B-A22B | Direct Answer | 10.1 | 11.1 | 20.8 | 3.6 | 8.7 | 14.8 | 8.3 | 0.0 | | | + TS | 11.2 (+1.0) | 11.1 | 12.5 | 0.0 | 17.4 | 22.2 | 12.5 | 0.0 | | | + IS | 14.2 (+3.0) | 25.9 | 25.0 | 3.6 | 26.1 | 11.1 | 4.2 | 0.0 | | Deep Research | | | | | | | | | | | o3-Deep-Research | Direct Answer | 41.1 | 55.6 | 41.7 | 21.4 | 52.2 | 48.1 | 37.5 | 25.0 |
Анализ результатов
Внутренняя сложность. В режиме Direct Answer все модели показывают низкие результаты — встроенных знаний недостаточно для запросов, требующих динамически собираемых свидетельств.
Недостаточность текстовых свидетельств. Добавление текстового поиска (+ TS) улучшает результаты всех моделей, но прирост ограничен — визуальные свидетельства, необходимые для ответов, нельзя извлечь только текстовым поиском.
Необходимость визуальных свидетельств. Подключение image search (+ IS) даёт дальнейший прирост, подтверждая эффективность фреймворка. Однако Claude-4.6-Sonnet некорректно использует инструменты визуального поиска, что приводит к деградации точности на 5.4 п.п.
Лучший результат — 47.6% у Claude-4.6-Opus. Лучшая открытая модель — Qwen3-VL-235B-A22B с 14.2%. Модели с богатыми предварительными знаниями и сильными рассуждающими способностями склонны полагаться исключительно на текстовые рассуждения, игнорируя визуальные инструменты.
Анализ использования инструментов
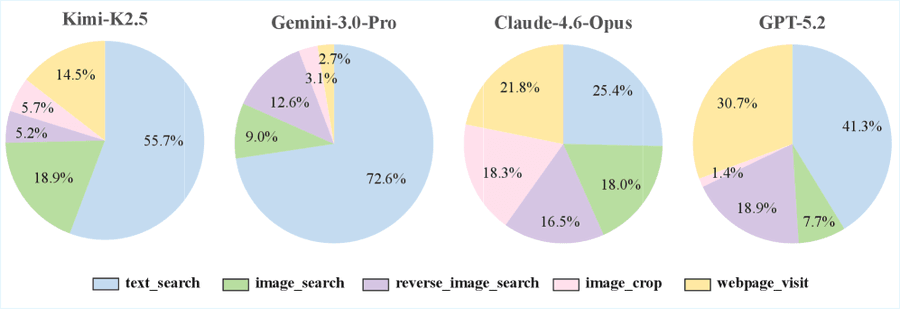
Рисунок 7: Доля использования каждого из пяти инструментов у четырёх MLLM: Kimi-K2.5, Gemini-3.0-Pro, Claude-4.6-Opus и GPT-5.2
Claude-4.6-Opus использует пять инструментов относительно сбалансированно и показывает лучший результат. Kimi-K2.5 заметно чаще вызывает image_search по сравнению с Gemini-3.0-Pro и GPT-5.2, что позволяет обнаружить больше визуальной информации и даёт наибольший прирост при переходе к + IS (+19.5 п.п.).
| Модель | Среднее число ходов | TS | IS | RIS | IC | WV |
|---|---|---|---|---|---|---|
| Закрытые модели | ||||||
| Gemini-3.0-Pro | 12.7 | 72.6 | 9.0 | 12.6 | 3.1 | 2.7 |
| Gemini-3.0-Flash | 9.1 | 75.3 | 15.4 | 5.2 | 0.8 | 3.3 |
| Gemini-2.5-Pro | 6.0 | 44.4 | 20.4 | 15.9 | 5.6 | 13.7 |
| Gemini-2.5-Flash | 5.4 | 45.4 | 11.6 | 18.1 | 3.9 | 21.0 |
| GPT-5.2 | 7.3 | 41.3 | 7.7 | 18.9 | 1.4 | 30.7 |
| GPT-5.1 | 3.5 | 45.6 | 5.9 | 31.6 | 0.7 | 16.2 |
| Claude-4.6-Opus | 12.3 | 25.4 | 18.0 | 16.5 | 18.3 | 21.8 |
| Claude-4.6-Sonnet | 10.9 | 28.6 | 8.3 | 29.2 | 5.0 | 28.9 |
| Kimi-K2.5 | 8.6 | 55.7 | 18.9 | 5.2 | 5.7 | 14.5 |
| Qwen3-VL-Plus | 5.5 | 56.6 | 23.8 | 2.4 | 7.6 | 9.6 |
| Открытые модели | ||||||
| Qwen3-VL-235B-A22B | 5.5 | 46.6 | 42.7 | 0.0 | 7.6 | 3.1 |
Сложность бенчмарка подтверждается глубиной инструментального взаимодействия, необходимого для решения. MLLM должны итеративно уточнять визуальные гипотезы через image search, верифицировать происхождение через reverse image search, извлекать детали через cropping и подтверждать находки текстовыми свидетельствами — ни один инструмент не даёт достаточно информации самостоятельно.
Примеры из практики
Успешный кейс
Вопрос: Человек в правом верхнем углу этого изображения снялся в высоко оценённом критиками фильме 2023 года. На главном визуальном постере этого фильма центральный персонаж изображён разговаривающим с другим персонажем у озера в Принстоне. Кто сыграл персонажа, одетого в чёрное, в той сцене?

Рисунок 8: Визуальный запрос
Claude-4.6-Opus успешно решил задачу за 15 шагов: обрезал изображение для идентификации Роберта Дауни мл. → подтвердил через text_search, что его фильм 2023 года — «Оппенгеймер» → нашёл постер через image_search → идентифицировал центральную фигуру (Киллиан Мёрфи) → через text_search нашёл сцену у озера с Эйнштейном → через image_search нашёл изображение сцены → через webpage_visit верифицировал детали → проанализировал одежду: Эйнштейн (Tom Conti) в тёмно-сером/чёрном пальто, Оппенгеймер — в коричневом. Ответ: Tom Conti.
Неудачный кейс
Вопрос: Бренд серого SUV в левом верхнем углу изображения выпустил новую коллекцию в августе 2023 года. Какого цвета галстук носит бренд-амбассадор на постере его мирового тура 2025 года?

Рисунок 9: Визуальный запрос
Claude-4.6-Opus правильно идентифицировал SUV как Changan CS75 Plus, нашёл бренд «Qiyuan/Nevo», запущенный в августе 2023, и определил амбассадора — Джей Чоу с его туром «Carnival World Tour 2025». Но на финальном этапе модель нашла постер тура через image_search, а затем попыталась проанализировать изображение через webpage_visit (который возвращает текстовое описание страницы, а не визуальный анализ). Вместо того чтобы использовать визуальные способности для определения цвета галстука на найденном изображении, модель угадала «blue» на основе общей синей тематики постера. Правильный ответ: black.
Выводы
VisBrowse-Bench выявляет два ключевых пробела в оценке мультимодальных browsing-агентов: недостаточное тестирование визуальных рассуждений и игнорирование интеграции мультимодальной информации в процессе рассуждений. Бенчмарк из 169 экспертно проверенных вопросов по семи категориям спроектирован так, что объединение мультимодальных данных необходимо на протяжении поиска, а визуальное понимание критично для решения. Предложенный агентный workflow с пятью инструментами (text search, image search, reverse image search, image cropping, webpage browsing) доказал свою эффективность, но результаты показывают, что даже лучшие модели справляются менее чем в половине случаев — направление визуально-ориентированного deep search требует дальнейшего развития.